需要相亲屡次才气找到靠谱的工具?

谈到相亲就不得不提到著名的麦穗问题。说有一天,苏格拉底教育几个门生来到一块成熟的麦地边。他对门生们说:“你们去麦地里摘一个较大的麦穗,但要求只能摘一次,只许进不许退,我在麦地的止境等你们。”可以看得出,相亲这种勾当就有点雷同于摘麦穗,在期待和定夺之间告竣均衡是办理问题的重点。
将上述的麦穗问题进一步抽象就是一个经典的概率问题。若一个袋子里有100个差异的球。每个球上标明白其尺寸巨细。我们每次随机无放回的从袋中取一个球出来,调查其巨细属性之后需抉择要或是不要。假如要,取球就此遏制。假如不要, 再继承取球,但禁绝再转头要原先的球。这样下去,直到100个球取完为止。目标就是取到谁人较大的球。
对付这个概率问题,一种思路就是取1到100之间的某个数字n,以它作为支解点将整袋球分别为两组,第一组即从第1个到第n个球,第二组即从第n+1个到第100个球。我们以第一组为调查工具,找到第一组中较大的球M,记录其巨细但并不可动。然后从第二组中寻找大于M的第一个球,取该球为最终选择。那么n应该设为几多,才气使取到较大球的概率尽大概的高呢?Ross在其《概率论基本教程》中已经给出了较准确的理会(英文版第8版P345;可能陈木法的《随机进程导论》 P105),最优的n公式表达为  ;在N充实大时,n应该取在1/e的比例处,也就是所有球数目标37%处。在解的进程中先运用条件概率获得全概率表达式,再用持续化的积分来近似离散化的概率,将积分求出后举办求导获得最终谜底。看到这里列位是否有些惊奇,这个e但是无所不在啊。
;在N充实大时,n应该取在1/e的比例处,也就是所有球数目标37%处。在解的进程中先运用条件概率获得全概率表达式,再用持续化的积分来近似离散化的概率,将积分求出后举办求导获得最终谜底。看到这里列位是否有些惊奇,这个e但是无所不在啊。
换句话说,假如你确定在生掷中会碰着100个工具,那么对前37个就请按捺住你的热情,鉴定个中最优秀的那位M,然后再去寻找比M更优秀的,假如然的碰着就立即动作,不要再踌躇。因为她/他很大概就是Mr. Right。
口说无凭,我们用R来检测一下上面的结论。先结构一个用于选择的函数,输入参数n是数据的支解点,输出即为选取获得的功效,假如获得100表白选取获得最优秀的工具,假如获得0则表白一无所获。然后配置n取值范畴从1到100,对每个n的值模仿10000次选取行为,计较出给定n条件下获得较大值的频次。从下图可以看到较大值简直取在37四周,切公道论功效。
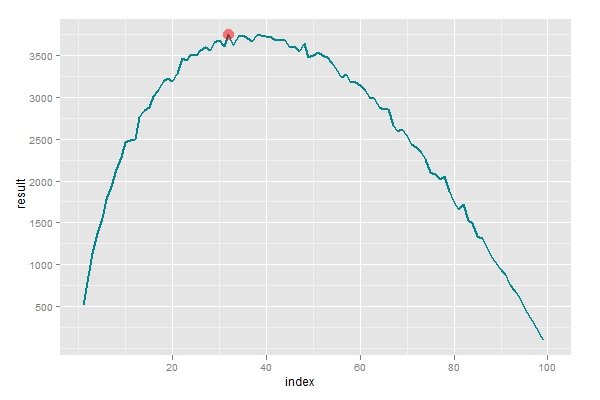
横轴暗示了差异的分别参数n,纵轴暗示给定n条件下,能获得最优值的频数
这里尚有一个问题,最优解不必然是令人满足的。按照最优解来动作,会有36%的大概获得较佳的工具,但也有靠近38%的大概会一无所获。实际上,有时候我们甘心获得一个次优的功效(譬喻99)也不但愿孤傲的糊口。所以在选择n这个参数的时候,方针应该着重于功效的期望值巨细。从头编程运行后,从下图可以调查到最优值取在7四周。也就是说,假如你确定在生掷中会碰着100个工具,那么前7个就略过,鉴定个中最优秀的那位M,然后再去寻找比M更优秀的,这样有较大的大概获得靠谱的工具。
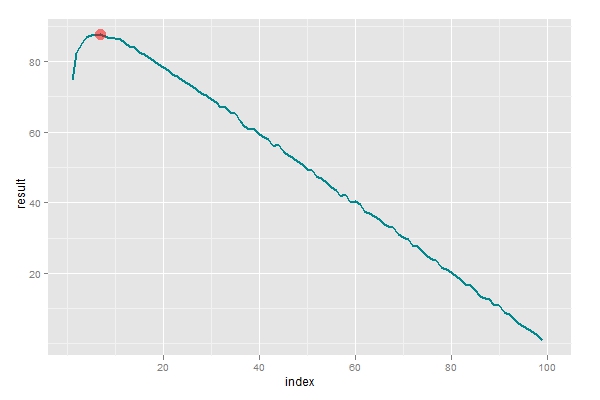
横轴为差异的分别参数n,纵轴暗示10000次模仿的期望值
好了,我们知道了应该在调查7个工具后就开始动作,那么回到本文的题目上来,也就是需要几多次相亲才气碰上Mr. Right呢?我们先结构一个函数来记录在第二组中举办实验的次数。然后模仿10000次后绘制直方图如下,可以看到仍然有7%阁下的人未能找到符合的工具,而50%的人在10次实验之内即能选取到符合的工具(未加上第一组的7次调查勾当),80%的人在30次实验之内即能找到符合的工具。所以说,只要你人品不是太差,在37次相亲实验之内,应该就可以找到靠谱的工具。进展你不会掉入离群点中去。
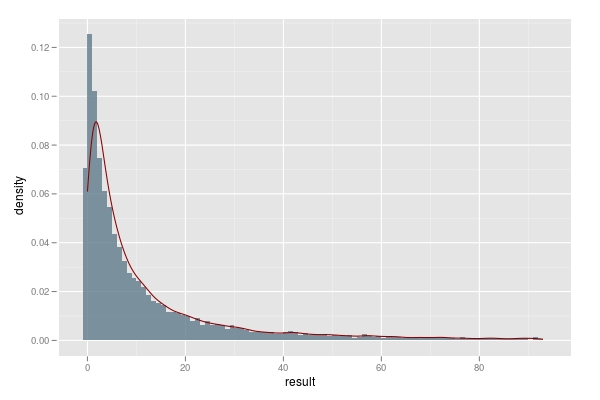
举办工具选取的一万次模仿,每次模仿返回选取工具所需要的实验次数,0暗示未能获得任何工具,1暗示在调查七个工具后,只需要一次实验就获得较优的工具。
注:本文结论有许多埋没前提,其推理亦大概有失误之处,仅供娱乐。若读者完全以本文为指导举办相亲勾当,其效果概不认真 ^_^
R代码如下:
# 举办调查和选取的函数,n认真对整体举办分别,取值在1到100之间
selection <- function(n) {
raw.data <- sample(1:100,100)
first.group <- raw.data[1:n]
second.group <- raw.data[(n+1):100]
first.max <- max(first.group)
morethan.first <- second.group > first.max
my.select <- ifelse(any(morethan.first) == TRUE,
second.group[morethan.first][1],0)
return(my.select)
}# 举办第一次模仿,找到最优的分别参数,使选取到较大值的概率较大。
data <- matrix(rep(0,10000*100),ncol=100)
result1 <- rep(0,100)
for (i in 1:100) {
temp <- replicate(n=10000,selection(i))
data[ ,i] <- temp
result1[i] <- sum(data[,i] == 100)
}
which.max(result1)# 用ggplot2画图包举办调查
library(ggplot2)
index <- 1:100
p <- ggplot(data=data.frame(index,result1),aes(index,result1))
p+geom_line(size=1, colour=’turquoise4′) +
geom_point(aes(x = which.max(result1),y=result1[which.max(result1)]),colour=alpha(‘red’,0.5),size=5)# 举办第二次模仿,找到最优的分别参数,使选取的期望值到达较大
result2 <- rep(0,100)
for (i in 1:100) {
result2[i] <- mean(replicate(n=10000,selection(i)))
}
p <- ggplot(data=data.frame(index,result2),aes(index,result2))
p+geom_line(size=1, colour=’turquoise4′) +
geom_point(aes(x = which.max(result2),y=result2[which.max(result2)]),colour=alpha(‘red’,0.5),size=5)# 结构函数,记录需要几多次实验才气选取较优的工具
howmany <- function(n) {
raw.data <- sample(1:100,100)
first.group <- raw.data[1:n]
second.group <- raw.data[(n+1):100]
first.max <- max(first.group)
morethan.first <- second.group > first.max
which.select <- ifelse(any(morethan.first) == TRUE,
which(morethan.first==T)[1],0)
return(which.select)
}# 记录实验次数的10000次模仿功效,并绘制直方图
result3<- replicate(n=10000,howmany(7))
p <- ggplot(data=data.frame(result3),aes(result3))
p + geom_histogram(binwidth=1, position=’identity’,
alpha=0.5,fill=’lightskyblue4′,aes(y = ..density..,))+
stat_density(geom = ‘line’,colour=’red4′)# 调查10次实验内可选取到符合工具的人数比例
length(result[result>0 & result <10])/10000
length(result[result>0 & result <30])/10000
