R语言为Hadoop注入统计血脉
RHadoop实践系列文章,
包括了R语言与Hadoop团结举办海量数据阐明。Hadoop主要用来存储海量数据,R语言完成MapReduce
算法,用来替代Java的MapReduce实现。有了RHadoop可以让宽大的R语言喜好者,有更强大的东西处理惩罚大数据1G, 10G, 100G,
TB, PB。 由于大数据所带来的单机机能问题,大概会一去不复返了。
RHadoop实践是一套系列文章,主要包罗”Hadoop情况搭建”,”RHadoop安装与利用”,”R实现MapReduce的协同过滤算法”,”HBase和rhbase的安装与利用”。对付单独的R语言喜好者,Java喜好者,可能Hadoop喜好者来说,同时具备三种语言常识并不容 易。此文虽为入门文章,但R,Java,Hadoop基本常识照旧需要各人提前把握。
关于作者
张丹(Conan), 措施员Java,R,PHP,Javascript
weibo:@Conan_Z
blog: http://blog.fens.me
email: [email protected]
转载请注明出处:
http://blog.fens.me/r-hadoop-intro/

媒介
写过几篇关于RHadoop的技能性文章,都是从统计的角度,先容如何让R语言操作Hadoop处理惩罚大数据。本日抉择反过来,从计较机开拓人员的角度,先容如何让Hadoop团结R语言,能做统计阐明的工作。
目次
- R语言先容
- Hadoop先容
- 为什么要让Hadoop团结R语言?
- 如何让Hadoop团结R语言?
- R和Hadoop在实际中的案例
1. R语言先容
发源
R语言,一种自由软件编程语言与操尽兴况,主要用于统计阐明、画图、数据挖掘。R原来是由来自新西兰奥克兰大学的Ross
Ihaka和Robert
Gentleman开拓(也因此称为R),此刻由“R开拓焦点团队”认真开拓。R是基于S语言的一个GNU打算项目,所以也可以看成S语言的一种实现。R
的语法是来自Scheme。
跨平台,许可证
R的源代码可自由下载利用,GNU通用民众许可证,可在多种平台下运行,包罗UNIX,Linux,Windows和MacOS。R主要是以呼吁行操纵为主,同时支持GUI的图形用户界面。
R的数字基因
R内建多种统计学及数字阐明成果。因为S的血缘,R比其他统计学或数学专用的编程语言有更强的物件导向成果。
R的另一强项是画图成果,制图具有印刷的素质,也可插手数学标记。
固然R主要用于统计阐明可能开拓统计相关的软体,但也有人用作矩阵计较。其阐明速度可媲美GNU Octave甚至贸易软件MATLAB。
代码库
CRAN为Comprehensive R Archive Network的简称。它除了保藏了R的执行档下载版、源代码和说明文件,也收录了各类用户撰写的软件包。全球有高出一百个CRAN镜像站,上万个第三方的软件包。
R的行业应用
统计阐明,应用数学,计量经济,金融阐明,财经阐明,人文科学,数据挖掘,人工智能,生物信息学,生物制药,全球地理科学,数据可视化。
贸易竞争敌手
2. Hadoop先容
Hadoop对付计较机的人,都是耳熟能说的技能了。
Hadoop是一个漫衍式系统基本架构,由Apache基金会开拓。用户可以在不相识漫衍式底层细节的环境下,开拓漫衍式措施。充实操作集群的威力
高速运算和存储。Hadoop实现了一个漫衍式文件系统(Hadoop Distributed File
System),简称HDFS。HDFS有着高容错性的特点,而且设计用来陈设在低廉的(low-cost)硬件上。并且它提供高传输率(high
throughput)来会见应用措施的数据,适合那些有着超大数据集(large data
set)的应用措施。HDFS放宽了(relax)POSIX的要求(requirements)这样可以流的形式会见(streaming
access)文件系统中的数据。
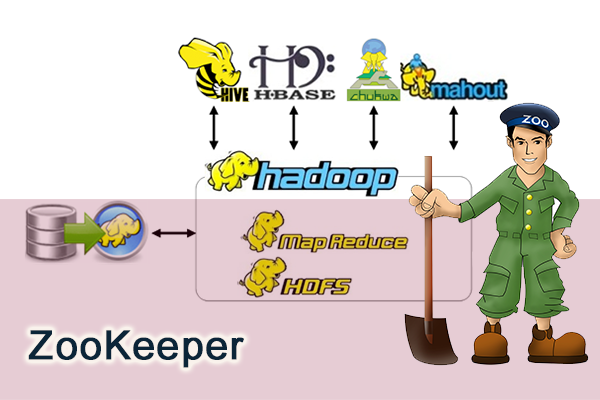
Hadoop的家属成员:Hive, HBase, Zookeeper, Avro, Pig, Ambari, Sqoop, Mahout, Chukwa
#p#分页标题#e#
自2006年,Hadoop以MapReduce和HDFS独立成长开始,到本年2013年不外7年时间,Hadoop的家属已经孵化出多个
Apache的较高级项目。出格是最近1-2年,成长速度越来越快,又融入了许多新技能(YARN, Hcatalog, Oozie,
Cassandra),都有点让我们都学不外来了。
3. 为什么要让Hadoop团结R语言?
前面两章,R语言先容和Hadoop先容,让我们体会到了,两种技能在各自规模的强大。许多开拓人员在计较机的角度,城市提出下面2个问题。
下面我实验着做一个解答:
问题1: Hadoop的家属如此之强大,为什么还要团结R语言?
a. Hadoop家属的强大之处,在于对大数据的处理惩罚,让本来的不行能(TB,PB数据量计较),成为了大概。
b. R语言的强大之处,在于统计阐明,在没有Hadoop之前,我们对付大数据的处理惩罚,要取样本,假设检讨,做回归,持久以来R语言都是统计学家专属的东西。
c. 从a和b两点,我们可以看出,hadoop重点是全量数据阐明,而R语言重点是样本数据阐明。 两种技能放在一起,恰好是最长补短!
d. 模仿场景:对1PB的新闻网站会见日志做阐明,预测将来流量变革
d1:用R语言,通过阐明少量数据,对业务方针建回归建模,并界说指标。
d2:用Hadoop从海量日志数据中,提取指标数据
d3:用R语言模子,对指标数据举办测试和调优
d4:用Hadoop分步式算法,重写R语言的模子,陈设上线
这个场景中,R和Hadoop别离都起着很是重要的浸染。以计较机开拓人员的思路,所有有工作都用Hadoop去做,没有数据建模和证明,”预测的功效”必然是有问题的。以统计人员的思路,所有的工作都用R去做,以抽样方法,获得的“预测的功效”也必然是有问题的。
所以让二者团结,是产界业的一定的导向,也是产界业和学术界的交集,同时也为交错学科的人才提供了无限辽阔的想象空间。
问题2: Mahout同样可以做数据挖掘和呆板进修,和R语言的区别是什么?
a. Mahout是基于Hadoop的数据挖掘和呆板进修的算法框架,Mahout的重点同样是办理大数据的计较的问题。
b. Mahout今朝已支持的算法包罗,协同过滤,推荐算法,聚类算法,分类算法,LDA, 朴素bayes,随机丛林。上面的算法中,大部门都是间隔的算法,可以通过矩阵解析后,充实操作MapReduce的并行计较框架,高效地完成计较任务。
c.
Mahout的空缺点,尚有许多的数据挖掘算法,很难实现MapReduce并行化。Mahout的现有模子,都是通用模子,直接用到的项目中,计较功效
只会比随机功效好一点点。Mahout二次开拓,要求有深厚的JAVA和Hadoop的技能基本,较好兼有 “线性代数”,“概率统计”,“算法导论”
等的基本常识。所以想玩转Mahout真的不是一件容易的工作。
d. R语言同样提供了Mahout支持的约大大都算法(除专有算法),而且还支持大量的Mahout不支持的算法,算法的增长速度比mahout快N倍。而且开拓简朴,参数设置机动,对小型数据集运算速度很是快。
#p#分页标题#e#
固然,Mahout同样可以做数据挖掘和呆板进修,可是和R语言的擅长规模并不重合。集百家之长,在适合的规模选择符合的技能,才气真正地“保质保量”做软件。
4. 如何让Hadoop团结R语言?
从上一节我们看到,Hadoop和R语言是可以互补的,但所先容的场景都是Hadoop和R语言的别离处理惩罚各自的数据。
一旦市场有需求,自然会有商家填补这个空缺。
1). RHadoop
RHadoop是一款Hadoop和R语言的团结的产物,由RevolutionAnalytics公司开拓,并将代码开源到github社区上面。
RHadoop包括三个R包 (rmr,rhdfs,rhbase),别离是对应Hadoop系统架构中的,MapReduce, HDFS,
HBase 三个部门。
参考文章:
RHadoop实践系列之二:RHadoop安装与利用
RHadoop实践系列之四 rhbase安装与利用
2). RHive
RHive是一款通过R语言直接会见Hive的东西包,是由NexR一个韩国公司研发的。
参考文章:
R利剑NoSQL系列文章 之 Hive
用RHive从汗青数据中提取逆回购信息
3). 重写Mahout
用R语言重写Mahout的实现也是一种团结的思路,我也做过相关的实验。
参考文章:
用R理会Mahout用户推荐协同过滤算法(UserCF)
4).Hadoop挪用R
上面说的都是R如何挪用Hadoop,虽然我们也可以反相操纵,买通JAVA和R的毗连通道,让Hadoop挪用R的函数。可是,这部门还没有商家做出成形的产物。
我写了2个例子,各人可以本身实验着团结,做出纷歧样的应用来。
参考文章:
Rserve与Java的跨平台通信
解惑rJava R与Java的高速通道
5. R和Hadoop在实际中的案例
R和Hadoop的团结,技能门槛照旧有点高的。对付一小我私家来说,不只要把握Linux, Java, Hadoop, R的技能,还要具备 软件开拓,算法,概率统计,线性代数,数据可视化,行业配景 的一些根基素质。
在公司陈设这套情况,同样需要多个部分,多种人才的的共同。Hadoop运维,Hadoop算法研发,R语言建模,R语言MapReduce化,软件开拓,测试等等。。。
所以,这样的案例并不太多。
我做过一些实验和尽力,已经整理成文章的有3个项目,文章中仅仅是实现思路。
参考文章:
RHadoop实践系列之三 R实现MapReduce的协同过滤算法
RHadoop尝试 – 统计邮箱呈现次数
用RHive从汗青数据中提取逆回购信息
展位将来
对付R和Hadoop的团结,在近几年,必定会生成发作式的增长的。但由于跨学科会造成技能壁垒,人才会远远跟不上市场的需求。
所以,必定会有更多的大数据东西,被发现!时机就在我们的手中,也许来日诰日你的创新,就是我们追逐的偏向!!
加油!!
转载请注明出处:
http://blog.fens.me/r-hadoop-intro/
