左手用R右手Python系列——数据塑型与长宽转换
本日这篇是R语言 with Python系列的第三篇,主要跟各人分享数据处理惩罚进程中的数据塑型与长宽转换。
其实这个系列算是我对付之前进修的R语言系列的一个总结,再加上恰好最近入门Python,这样在总结R语言的同时,比拟R语言与Pyhton在数据处理惩罚中常用办理方案的差别,每一个小节只讲一个小常识点,可是这些常识点都是日常数据处理惩罚与清洗进程中很是高频的需求。
不会跟各人烦琐太多每一个函数的具体参数,只列出那些参数中的须要设定,总体以简朴实用为原则。如若需要具体相识每一个函数的内部参数,照旧需要本身查阅官方文档。
数据长宽转换是很常用的需求,出格是当是从Excel中导入的汇总表时,经常需要转换成一维表(长数据)才气提供应图表函数可能模子利用。
在R语言中,提供数据长宽转换的包主要有两个:
reshape2::melt/dcast
tidyr::gather/spread
library(“reshape2”)
library(“tidyr”)mydata<-data.frame(
Name = c(“苹果”,”谷歌”,”脸书”,”亚马逊”,”腾讯”),
Conpany = c(“Apple”,”Google”,”Facebook”,”Amozon”,”Tencent”),
Sale2013 = c(5000,3500,2300,2100,3100),
Sale2014 = c(5050,3800,2900,2500,3300),
Sale2015 = c(5050,3800,2900,2500,3300),
Sale2016 = c(5050,3800,2900,2500,3300)
)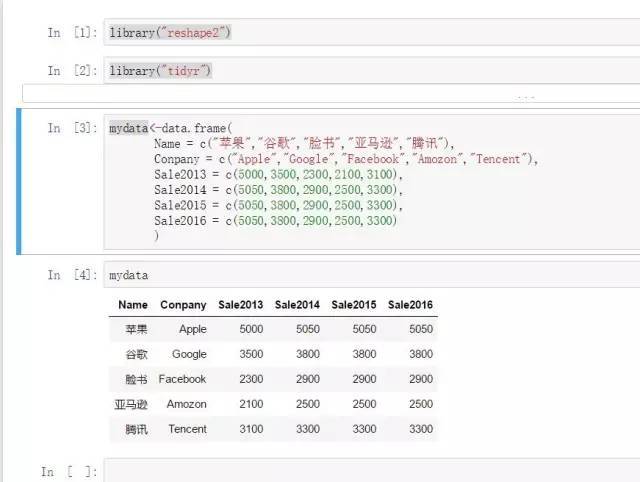 数据重塑(宽转长):
数据重塑(宽转长):
melt函数是reshape2包中的数据宽转长的函数
mydata<-melt(
mydata, #待转换的数据集名称
id.vars=c(“Conpany”,”Name”), #要保存的主字段
variable.name=”Year”, #转换后的分类字段名称(维度)
value.name=”Sale” #转换后的怀抱值名称
)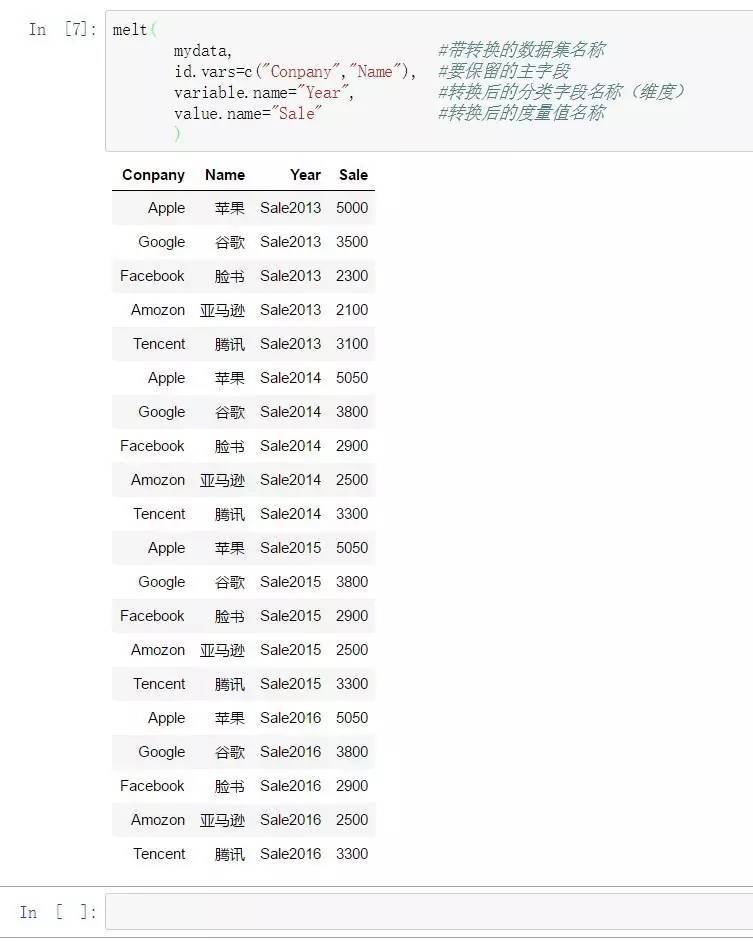 转换之后,长数据布局保存了原始宽数据中的Name、Conpany字段,同时将剩余的年度指标举办仓库,转换为一个代表年度的种别维度和对应年度的指标。(即转换后,所有年度字段被降维化了)。
转换之后,长数据布局保存了原始宽数据中的Name、Conpany字段,同时将剩余的年度指标举办仓库,转换为一个代表年度的种别维度和对应年度的指标。(即转换后,所有年度字段被降维化了)。
在tidyr包中的gather也可以很是快捷的完成宽转长的任务:
data1<-gather(
data=mydata, #待转换的数据集名称
key=”Year”, #转换后的分类字段名称(维度)
value=”Sale” , #转换后的怀抱值名称
Sale2013:Sale2016 #选择将要被拉长的字段组合
) #(可以利用x:y的名目选择持续列,也可以以-z的名目解除主字段)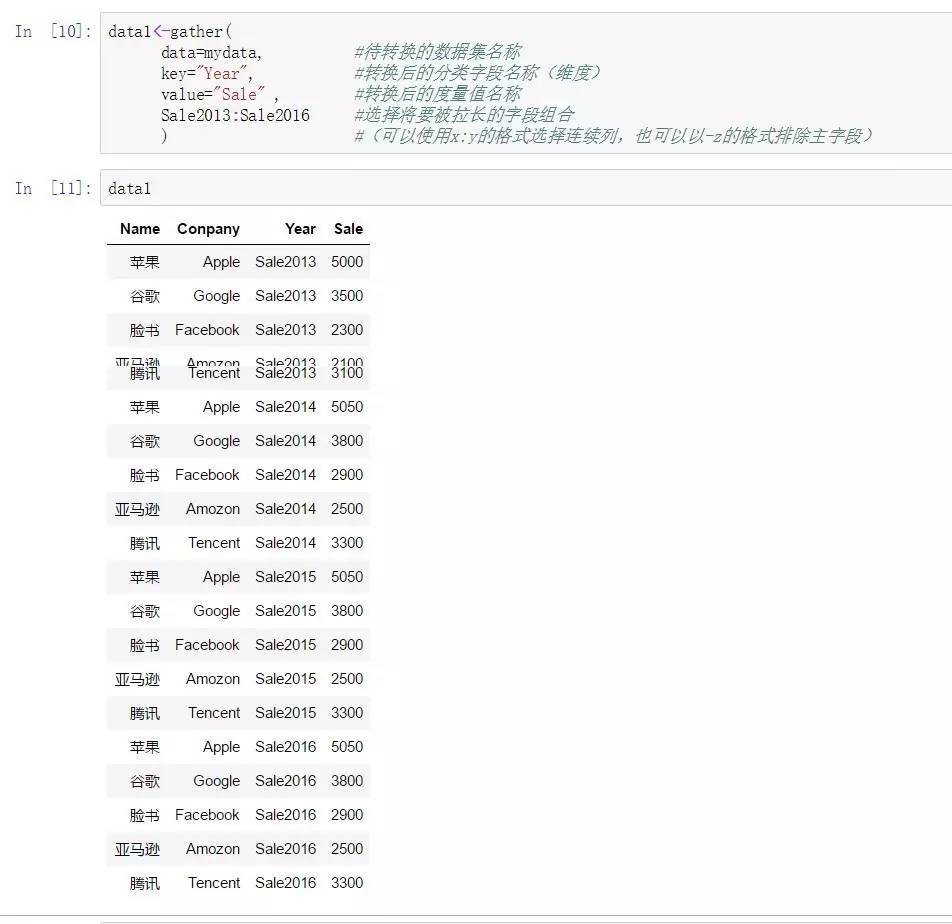 而相对付数据宽转长而言,数据长转宽就显得不是很常用,因为长转宽是数据透视,这种透视进程可以通过汇总函数可能类数据透视表函数来完成。
而相对付数据宽转长而言,数据长转宽就显得不是很常用,因为长转宽是数据透视,这种透视进程可以通过汇总函数可能类数据透视表函数来完成。
可是既然数据长宽转换是成对的需求,自然有对应的长转宽函数。
reshape2中的dcast函数可以完成数据长转宽的需求:
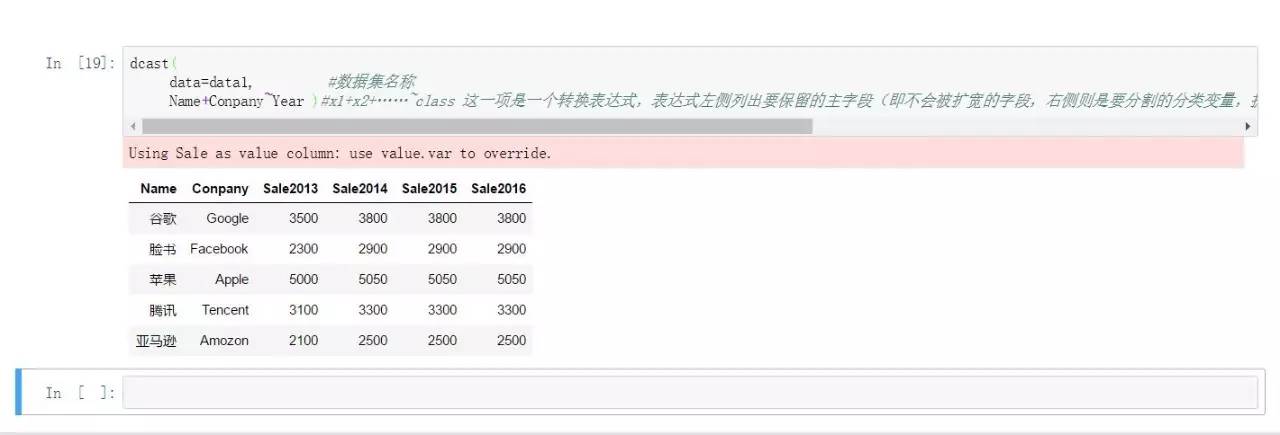
dcast(
data=data1, #数据集名称
Name+Conpany~Year #x1+x2+……~class
#这一项是一个转换表达式,表达式左侧列
#出要保存的主字段(即不会被扩宽的字段,右侧则是要支解的分类变量,扩展之后的
#宽数据会增加若干列怀抱值,列数便是表达式右侧分类变量的种别个数
)
除此之外,tidyr包中的spread函数在办理数据长转宽方面也是很好的一个选择。
spread:
spread(
data=data1, #带转换长数据框名称
key=Year, #带扩宽的种别变量(编程新增列名称)
value=Sale) #带扩宽的怀抱值 (编程新增列怀抱值)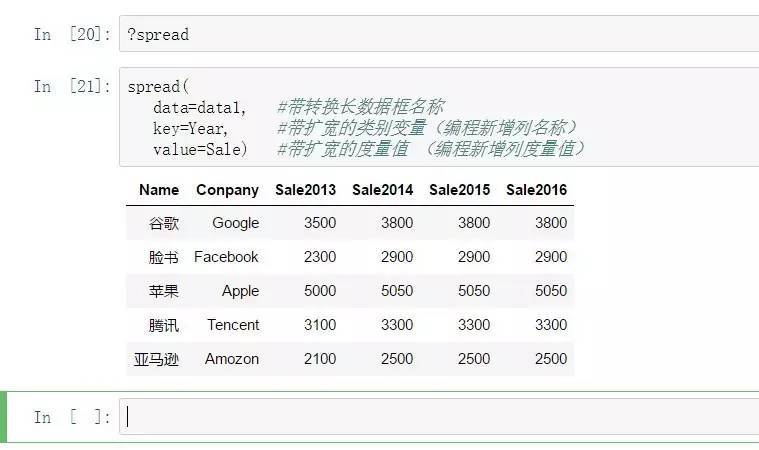 从以上代码的巨大度来看,reshape2内的两个函数melt\dcast和tidyr内的两个函数gather\spread对比,gather\spread这一对函数完胜,不愧是哈神的力作,tidyr内的两个函数所需参数少,逻辑上更好领略,自始至终都环绕着data,key、value三个参数来举办设定,而相对老旧的包reshape2内的melt\dcast函数在参数设置上就显得不是很友好,他是环绕着一直稳定的主字段来举办设定的,tidyr包则环绕着转换进程中会变形的维度和怀抱来设定的。
从以上代码的巨大度来看,reshape2内的两个函数melt\dcast和tidyr内的两个函数gather\spread对比,gather\spread这一对函数完胜,不愧是哈神的力作,tidyr内的两个函数所需参数少,逻辑上更好领略,自始至终都环绕着data,key、value三个参数来举办设定,而相对老旧的包reshape2内的melt\dcast函数在参数设置上就显得不是很友好,他是环绕着一直稳定的主字段来举办设定的,tidyr包则环绕着转换进程中会变形的维度和怀抱来设定的。
接下来是Python中的数据塑性与长宽转换。
Python中我只讲两个函数:
melt #数据宽转长
pivot_table #数据长转宽
Python中的Pandas包提供了与R语言中reshape2包内险些同名的melt函数来对数据举办塑型(宽转长)操纵,甚至连内部参数都保持了一致的气势气魄。
import pandas as pd
import numpy as npmydata=pd.DataFrame({
“Name”:[“苹果”,”谷歌”,”脸书”,”亚马逊”,”腾讯”],
“Conpany”:[“Apple”,”Google”,”Facebook”,”Amozon”,”Tencent”],
“Sale2013”:[5000,3500,2300,2100,3100],
“Sale2014”:[5050,3800,2900,2500,3300],
“Sale2015”:[5050,3800,2900,2500,3300],
“Sale2016”:[5050,3800,2900,2500,3300]
})mydata1=mydata.melt(
id_vars=[“Name”,”Conpany”], #要保存的主字段
var_name=”Year”, #拉长的分类变量
value_name=”Sale” #拉长的怀抱值名称
)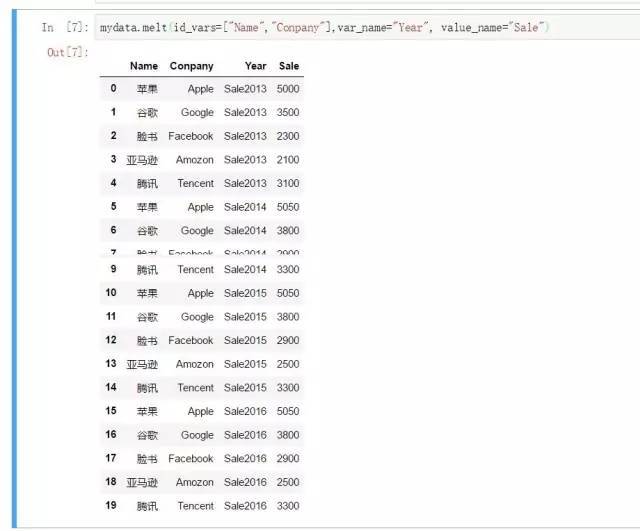 除此之外,我相识到还可以通过stack、wide_to_long函数来举办宽转长,可是小我私家以为melt函数较量直观一些,也与R语言中的数据宽转长用法一致,推荐利用。
除此之外,我相识到还可以通过stack、wide_to_long函数来举办宽转长,可是小我私家以为melt函数较量直观一些,也与R语言中的数据宽转长用法一致,推荐利用。
奇怪的是我仿佛没有在pandas中找到对应melt的数据长转宽函数(R语言中都是成对呈现的)。还在Python中提供了很是便捷的数据透视表操纵函数,刚开始就已经说过是,长数据转宽数据就是数据透视的进程(自然宽转长就可以被称为逆透视咯,PowerBI也是这么称号的)。
pandas中的数据透视表函数提供如同Excel原生透视表一样的利用体验,即行标签、列标签、怀抱值等操纵,按照利用法则,队列主要操纵维度指标,值主要操纵怀抱指标。
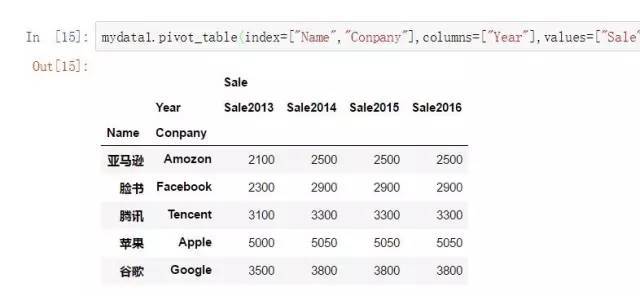
那么以上长数据mydata1就可以通过这种方法实现透视。
mydata1.pivot_table(
index=[“Name”,”Conpany”], #行索引(可以使多个种别变量)
columns=[“Year”], #列索引(可以使多个种别变量)
values=[“Sale”] #值(一般是怀抱指标)
)
凡是这种操纵也可以借助仓库函数来到达同样的目标。(可是利用stack\unstack需要特别配置多索引,灰常贫苦,所以不是很推荐,有乐趣可以查察pandas中的stack/unstack要领,这里不再赘述)。
综上所述,本文主要提供了R语言与Python顶用于处理惩罚数据重塑(长宽转换的常用办理方案)。
R语言:reshape2::melt
reshape2::dcast
tidyr::gather
tidyr::spread
Python:pandas-melt
pandas-pivot_table
(备选方案——stack/unstack、wide_to_long)
接待插手本站果真乐趣群贸易智能与数据阐明群乐趣范畴包罗各类让数据发生代价的步伐,实际应用案例分享与接头,阐明东西,ETL东西,数据客栈,数据挖掘东西,报表系统等全方位常识QQ群:81035754
