手把手教你用R语言成立信用评分模子(二)—单变量阐明
单变量阐明在风险建模的进程中,变量选择可以详细细化为单变量变量筛选 (Univariate Variable Selection)和多变量变量筛选 (Multivariate Variable Selection)。多变量变量筛选一般会操作Stepwise算法在变量池中选取最优变量。 而单变量筛选,可能说单变量阐明,是通过较量指标分箱和对应分箱的违约概率来确定指标是否切合经济意义。
详细的单变量阐明要领有许多种, 如我在《信用评级建模中的数据清洗与变量选择》中先容的的AR值阐明、《信用评分模子中应不该该包罗“歧视变量”》中的 优劣比阐明(Goods/Bads)都可以看作单变量阐明的详细浮现。 在本文,我会先容另一种常见的单变量阐明要领:WoE阐明。
这三种要领,本质的要领论都是一致的:去较量变量分箱和违约程度的相关干系。一般来讲,正向指标 (如公司评级模子中的利润率,零售评级模子中的抵押品代价)要和分箱内违约率呈反向干系, 反向指标要同分箱内违约率呈正向干系。虽然也有非凡的U型指标,这里不再详述,详情请见《信用评级建模中的数据清洗与变量选择》中的先容。但这三者差异的是个中分箱内代表违约程度的指标,在差异的要领中指标计较有所差异(AR值/优劣比/WoE)。
WoE阐明, 是对指标分箱、计较各个档位的WoE值并调查WoE值随指标变革的趋势。个中WoE的数学界说是:
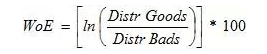
WoE界说,另一种WoE界说不包罗 rescale factor(×100)
在举办阐明时,我们需要对各指标从小到大分列,并计较出相应分档的WoE值。个中正向指标越大,WoE值越小;反向指标越大,WoE值越大。正向指标的WoE值负斜率越大,回声指标的正斜率越大,则说明指标区分本领好。WoE值趋近于直线,则意味指标判定本领较弱。若正向指标和WoE正相关趋势、反向指标同WoE呈现负相关趋势,则说明此指标不切合经济意义,则该当予以去除。
首先来看一下AccountBalance(支票账户余额):AccountBalancewoe=woe(train, “AccountBalance”,Continuous = F, “Creditability”,C_Bin = 4,Good = “1”,Bad = “0”)ggplot(AccountBalancewoe, aes(x = BIN, y = -WOE)) + geom_bar(stat = “identity”,fill = “blue”, colour = “grey60”,size = 0.2, alpha = 0.2)+labs(title = “AccountBalance”) 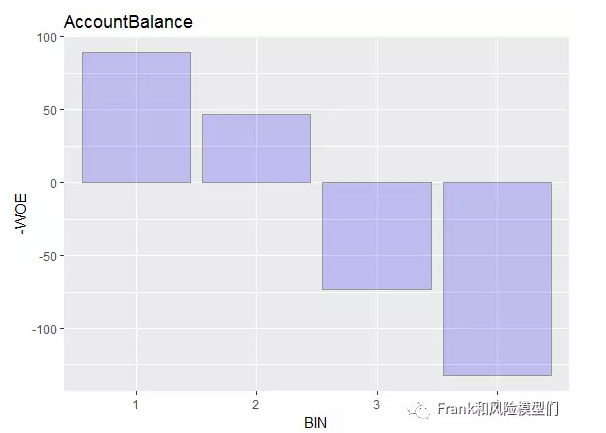 一般来讲,支票账户余额越多,借钱人还款本领越强,所以这个指标是一个正向指标。可以看出AccountBalance同WoE程强负相关干系,且没有跳点(个体分箱不切合总体趋势则被称为跳点)。所以接管AccountBalance作为进入模子的变量之一。
一般来讲,支票账户余额越多,借钱人还款本领越强,所以这个指标是一个正向指标。可以看出AccountBalance同WoE程强负相关干系,且没有跳点(个体分箱不切合总体趋势则被称为跳点)。所以接管AccountBalance作为进入模子的变量之一。
接下来阐明一下ValueSavings(储备账户余额)以下是分箱尺度:ValueSavings1 : … < 100 DM 2 : 100 <= … < 500 DM 3 : 500 <= … < 1000 DM 4 : .. >= 1000 DM 5 : unknown/ no savings account 个中,第五个分箱(unknown/ no savings account )同前四项并无可比性,所以在较量中可以忽略此分箱。
R代码:ValueSavingswoe=woe(train2, “ValueSavings”,Continuous = F, “Creditability”,C_Bin = 5,Good = “1”,Bad = “0”)ggplot(ValueSavingswoe, aes(x = BIN, y = -WOE)) + geom_bar(stat = “identity”,fill = “blue”, colour = “grey60”,size = 0.2, alpha = 0.2)+labs(title = “ValueSavings”)
输出后的R图形:
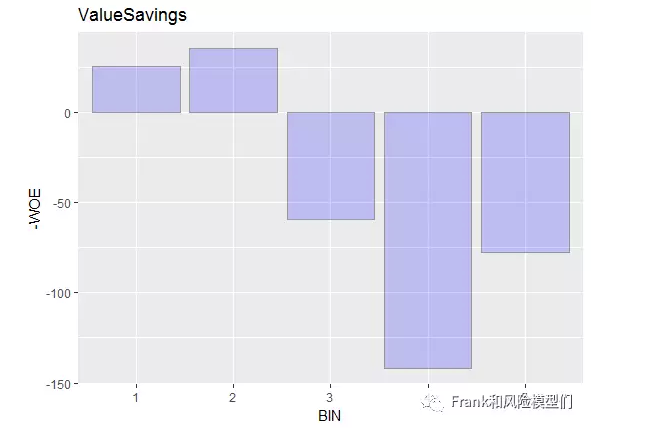
从上图看出,在 分箱2 呈现了轻微的跳点现象。因为跳点幅度并不大,我们可以保存此分箱,可能对分箱1和分箱2举办归并。for(i in 1:750){ if(train$ValueSavings[i]==1){train2$ValueSavings[i]=2}}分箱尺度:ValueSavings2 : < 500 DM 3 : 500 <= … < 1000 DM 4 : .. >= 1000 DM 5 : unknown/ no savings account
从头输出:
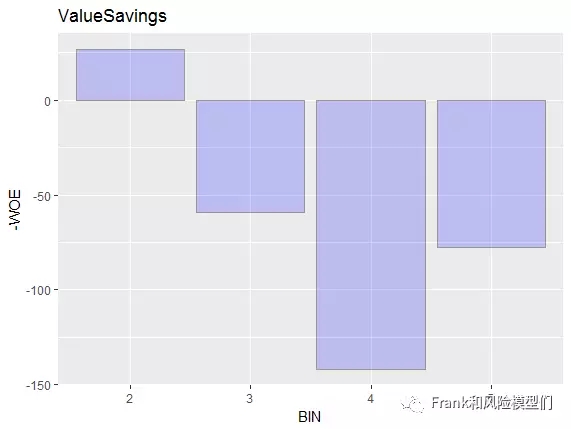
可以看出,通过归并前两个分箱,ValueSavings(储备账户余额)指标和WoE呈明明的负相关干系,且无跳点。因而,可以接管这一指标。
最后一个进入单变量阐明的指标是Lengthofcurrentemployment(受雇佣年限),下面是详细分箱尺度:1 : unemployed 2 : … < 1 year 3 : 1 <= … < 4 years 4 : 4 <= … < 7 years 5 : .. >= 7 years
运行R代码:Lengthofcurrentemploymentwoe=woe(train, “Lengthofcurrentemployment”,Continuous = F, “Creditability”,C_Bin = 4,Good = “1”,Bad = “0”)ggplot(Lengthofcurrentemploymentwoe, aes(x = BIN, y = -WOE)) + geom_bar(stat = “identity”,fill = “blue”, colour = “grey60”,size = 0.2, alpha = 0.2)+labs(title = “Lengthofcurrentemployment”)
输出R图形:
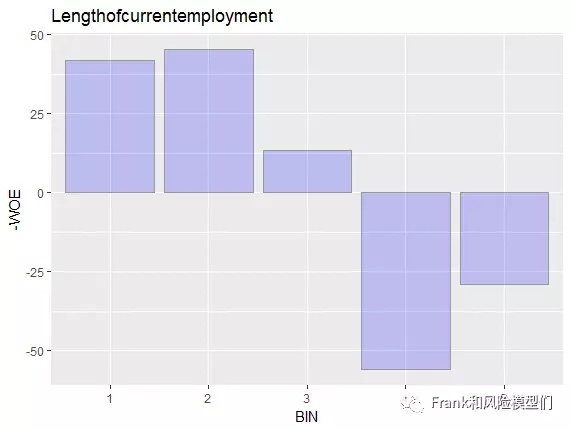
同样, Lengthofcurrentemployment(受雇佣年限)呈现了跳点现象。因而, 我们将分箱4 和 分箱5 举办归并。 for(i in 1:750){ if(train2$Lengthofcurrentemployment[i]==5){train2$Lengthofcurrentemployment[i]=4}}重分箱尺度:1 : unemployed 2 : … < 1 year 3 : 1 <= … < 4 years 4 : .. >= 4 years
从头输出:#p#分页标题#e#
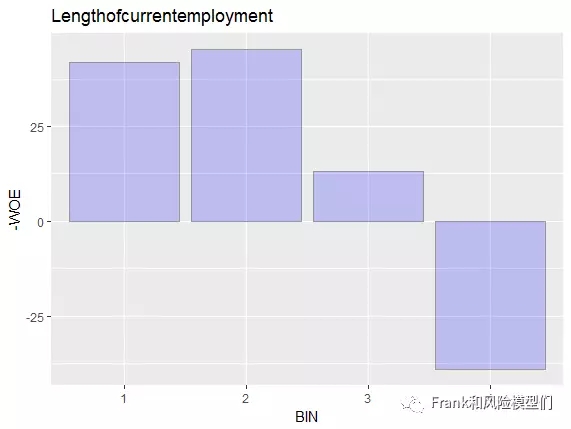
颠末归并后,Lengthofcurrentemployment(受雇佣年限)指标泛起明明的负相关干系,且无跳点现象。可以接管指标进入下一步的筛选。
接待插手本站果真乐趣群贸易智能与数据阐明群乐趣范畴包罗各类让数据发生代价的步伐,实际应用案例分享与接头,阐明东西,ETL东西,数据客栈,数据挖掘东西,报表系统等全方位常识QQ群:81035754
