中文文天职析利便东西包chinese.misc简介
 此刻NLP技能那么发家了,各类东西那么NB了,但是用R做文天职析的人居然还得为如何读文件不乱码、如何分词、如何统计词频这样的事犯难,也是醉了。假如老逗留在这个程度上,那列位亲你们离本身成天挂在嘴边儿的大数据呆板进修之类的根基上就无缘了。所以但愿各人能把更多精神放到算法上,而不是用在一些琐碎、挥霍时间又极其恼人的工作上。 其实像文本清理这种活儿,根基上就应该是用鼠标点吧点吧就能自动完成的,若要还费半天劲的话纯属扯淡。 所以,chinese.misc这个R包就要来完成这个任务。
此刻NLP技能那么发家了,各类东西那么NB了,但是用R做文天职析的人居然还得为如何读文件不乱码、如何分词、如何统计词频这样的事犯难,也是醉了。假如老逗留在这个程度上,那列位亲你们离本身成天挂在嘴边儿的大数据呆板进修之类的根基上就无缘了。所以但愿各人能把更多精神放到算法上,而不是用在一些琐碎、挥霍时间又极其恼人的工作上。 其实像文本清理这种活儿,根基上就应该是用鼠标点吧点吧就能自动完成的,若要还费半天劲的话纯属扯淡。 所以,chinese.misc这个R包就要来完成这个任务。 chinese.misc(今朝为0.1.3版本)的成果极其简朴,主要用于对中文文本举办数据清理事情,另外还包括别的一些实用的处理惩罚和阐明成果。在生成文档-词语矩阵的成果上,可以取代对中文不是太支持的tm包,出格是在淘汰乱码方面。假如你此刻还忙于看如何分词、如何删去停用词、如何计较词频之类的事情,那么这些都用不着看了,让我们把事情变得更无脑些! 这个包的中文手册见https://github.com/githubwwwjjj/chinese.misc。不外,英文pdf比中文说明具体多了。 chinese.misc的焦点函数是corp_or_dtm,可直接从文件夹名/文件名/文本向量中生成文档-词语矩阵,而且自动或按利用者要求举办一些文本清理事情。 另外,软件包中dir_or_file、scancn、make_stoplist、slim_text等函数都是在中文文天职析中较量实用的函数,可以辅佐利用者淘汰许多贫苦。 在这里,我只展示一下这个包的少数成果,其它成果还请各人去看中文手册。 文本样例请到http://pan.baidu.com/s/1nuXLBg1下载,里边是30篇中纪委巡视陈诉。假如你解压后文件数差池或是乱码,那险些只大概是因为你正在利用MAC。请只管在WINDOWS上搞 。我们假设你解压后的文件路径是”f:/sample”。 # 安装、加载。请利用3.3.2及以上版本的Rinstall.packages(“chinese.misc”)library(chinese.misc)f=”f:/sample” # 你的路径 # 我们此刻想要一个词语-文档矩阵。你之前看到的网上飞的各类教程都在跟你们绕弯子,是不是以为很贫苦?好吧,我们就用一个代码办理问题。dtm=corp_or_dtm( f, type=”d”, stop_word=”jiebar”, control=”auto2″ )
chinese.misc(今朝为0.1.3版本)的成果极其简朴,主要用于对中文文本举办数据清理事情,另外还包括别的一些实用的处理惩罚和阐明成果。在生成文档-词语矩阵的成果上,可以取代对中文不是太支持的tm包,出格是在淘汰乱码方面。假如你此刻还忙于看如何分词、如何删去停用词、如何计较词频之类的事情,那么这些都用不着看了,让我们把事情变得更无脑些! 这个包的中文手册见https://github.com/githubwwwjjj/chinese.misc。不外,英文pdf比中文说明具体多了。 chinese.misc的焦点函数是corp_or_dtm,可直接从文件夹名/文件名/文本向量中生成文档-词语矩阵,而且自动或按利用者要求举办一些文本清理事情。 另外,软件包中dir_or_file、scancn、make_stoplist、slim_text等函数都是在中文文天职析中较量实用的函数,可以辅佐利用者淘汰许多贫苦。 在这里,我只展示一下这个包的少数成果,其它成果还请各人去看中文手册。 文本样例请到http://pan.baidu.com/s/1nuXLBg1下载,里边是30篇中纪委巡视陈诉。假如你解压后文件数差池或是乱码,那险些只大概是因为你正在利用MAC。请只管在WINDOWS上搞 。我们假设你解压后的文件路径是”f:/sample”。 # 安装、加载。请利用3.3.2及以上版本的Rinstall.packages(“chinese.misc”)library(chinese.misc)f=”f:/sample” # 你的路径 # 我们此刻想要一个词语-文档矩阵。你之前看到的网上飞的各类教程都在跟你们绕弯子,是不是以为很贫苦?好吧,我们就用一个代码办理问题。dtm=corp_or_dtm( f, type=”d”, stop_word=”jiebar”, control=”auto2″ )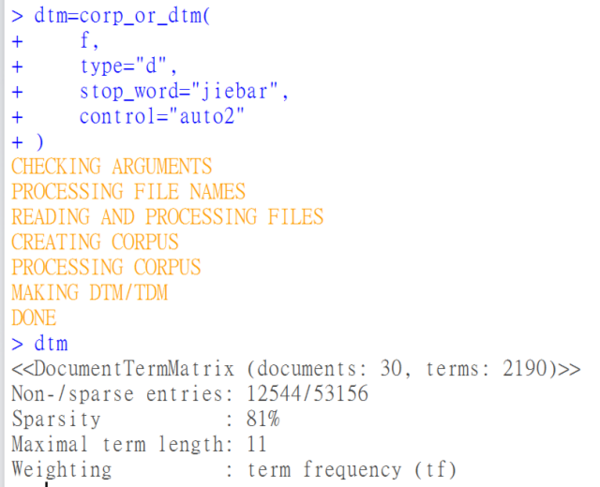 # 在蹦了一串字儿之后,功效就出来了,跟用鼠标点点也没有太大区别。 # 可是我们会以为词太多了,尽量我们在以上函数中去除了停用词,仍然尚有不少虚词存在,因此我们往下砍词的力度不得不再大些。这时就可以用slim_text函数。另外,我们需要再对词语举办限制,除了但愿保存的词语都至少有两个字符外,而但愿这些词都至少呈现过5回。dtm=corp_or_dtm( f, type=”d”, stop_word=”jiebar”, myfun1=slim_text, control=list( wordLengths=c(2,25), have=c(5, 1000) ) )
# 在蹦了一串字儿之后,功效就出来了,跟用鼠标点点也没有太大区别。 # 可是我们会以为词太多了,尽量我们在以上函数中去除了停用词,仍然尚有不少虚词存在,因此我们往下砍词的力度不得不再大些。这时就可以用slim_text函数。另外,我们需要再对词语举办限制,除了但愿保存的词语都至少有两个字符外,而但愿这些词都至少呈现过5回。dtm=corp_or_dtm( f, type=”d”, stop_word=”jiebar”, myfun1=slim_text, control=list( wordLengths=c(2,25), have=c(5, 1000) ) )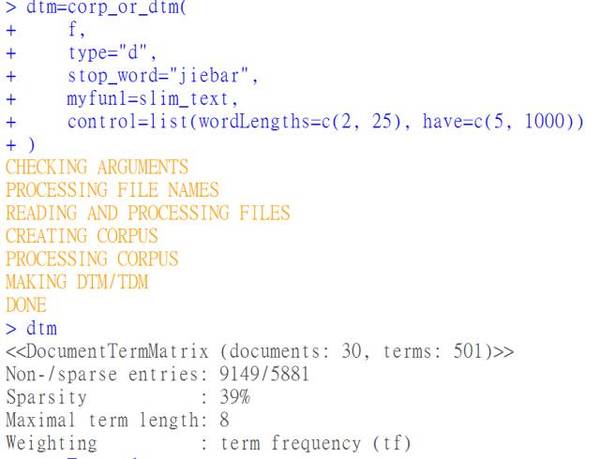 # 公然,词语数量大幅淘汰了。 # 接下来,我们想看一下高频词有哪些,让我们看最前边的20个词:sort_tf(dtm, top=20)
# 公然,词语数量大幅淘汰了。 # 接下来,我们想看一下高频词有哪些,让我们看最前边的20个词:sort_tf(dtm, top=20)
# 是的,功效会直接打在你屏幕上,你可以顺便复制粘贴到Excel里。虽然,你也可以生成一个数据框: df=sort_tf(dtm, top=20, todf=TRUE) # 然后呢,再看看词语之间的关联,好比:word_cor(dtm, word=c(“作风”, “规律”, “责任”, “精力”))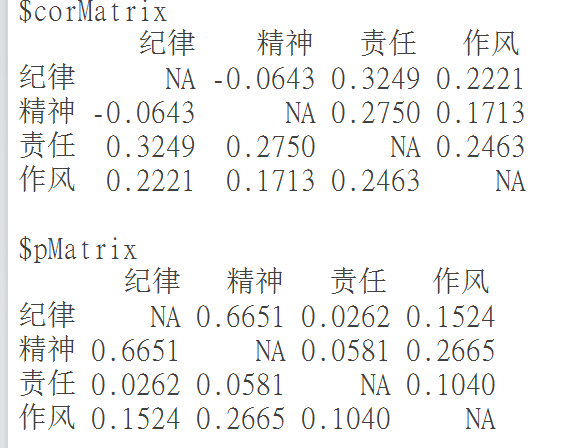 #嗯,出来俩表,上边谁人是相干系数,下边是p值。我们可以用p值卡一下,假如一个回归系数的p值在0.2以就,就让它消失。word_cor(dtm, word=c(“作风”, “规律”, “责任”, “精力”), p=0.2) # 再举个跟样例无关的例子。如果你此刻有时间跨度为10年的一批论文,然后你已经用LDA之类的模子确定了它们的种别。那么怎么判定他们随年份变革的趋势呢,可能说,奈何求一个根基的话题热度指数? ## 先把随便造点儿数据set.seed(123)year=sample(2007: 2016, 500, replace=TRUE)set.seed(1234)topic=sample(c(“经济学”, “文学”, “法学”, “打点学”, “艺术”, “心理学”, “社会学”), 500, replace=TRUE)topic_trend(year, topic)
#嗯,出来俩表,上边谁人是相干系数,下边是p值。我们可以用p值卡一下,假如一个回归系数的p值在0.2以就,就让它消失。word_cor(dtm, word=c(“作风”, “规律”, “责任”, “精力”), p=0.2) # 再举个跟样例无关的例子。如果你此刻有时间跨度为10年的一批论文,然后你已经用LDA之类的模子确定了它们的种别。那么怎么判定他们随年份变革的趋势呢,可能说,奈何求一个根基的话题热度指数? ## 先把随便造点儿数据set.seed(123)year=sample(2007: 2016, 500, replace=TRUE)set.seed(1234)topic=sample(c(“经济学”, “文学”, “法学”, “打点学”, “艺术”, “心理学”, “社会学”), 500, replace=TRUE)topic_trend(year, topic)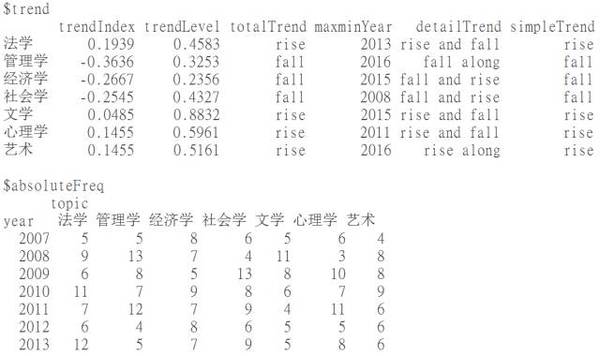
好吧,就先先容到这儿了。更具体的辅佐和更多的函数,还请看中英文手册。
接待插手本站果真乐趣群贸易智能与数据阐明群乐趣范畴包罗各类让数据发生代价的步伐,实际应用案例分享与接头,阐明东西,ETL东西,数据客栈,数据挖掘东西,报表系统等全方位常识QQ群:81035754
