在R语言中对回归树模子、装袋算法与随机丛林之间的简朴较量
在R语言中对回归树模型、装袋算法与随机森林之间的简单比较
回归树模型在之前的博客文章中已有介绍。而装袋算法与随机森林相对而言会生成多个树模型,再进行组合预测,其效果远大于单个树模型。装袋算法(bagging)采取自助法的思路,从样本中随机抽样,形成多个训练样本,生成多个树模型。然后以多数投票的方式来预测结果。随机森林则(randomForest)更进一步,不仅对样本进行抽样,还对变量进行抽样。下面来横向对比一下各算法。
首先读入必要的程序包
library(DMwR)
library(rpart)
library(ipred)
library(randomForest)
前二种算法可以计算缺失数据,但随机森林不行,所以还需将数据进行清洗整理
data(algae)
algae <- algae[-manyNAs(algae), ]
clean.algae <- knnImputation(algae,k=10)
回归树模型计算
model.tree=rpart(a1 ~ ., data = clean.algae[, 1:12])
pre.tree <- predict(model.tree, clean.algae)
plot(pre.tree~clean.algae$a1)
nmse1 <- mean((pre.tree- clean.algae[,’a1′])^2)/
mean((mean(clean.algae[,’a1′])- clean.algae[,’a1′])^2)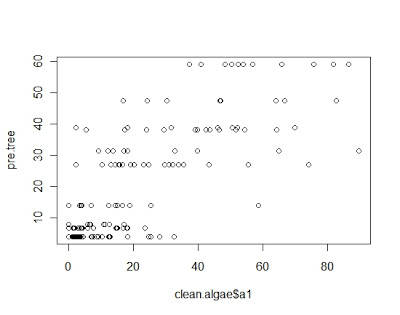
装袋算法计算
model.bagging <- bagging(
a1 ~ ., data = clean.algae[, 1:12], nbagg=1000)
pre.bagging=predict(model.bagging,clean.algae)
plot(pre.bagging~clean.algae$a1)
nmse2 <- mean((pre.bagging- clean.algae[,’a1′])^2)/
mean((mean(clean.algae[,’a1′])- clean.algae[,’a1′])^2)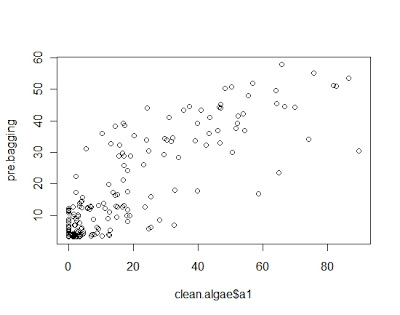
随机森林计算
model.forest <-randomForest(a1 ~ ., data = clean.algae)
#若有缺失数据需加入: na.action=na.omit
pre.forest=predict(model.forest, clean.algae)
plot(pre.forest~ clean.algae$a1)
(nmse3 <- mean((pre.forest- clean.algae[,’a1′])^2)/
mean((mean( clean.algae[,’a1′])- clean.algae[,’a1′])^2)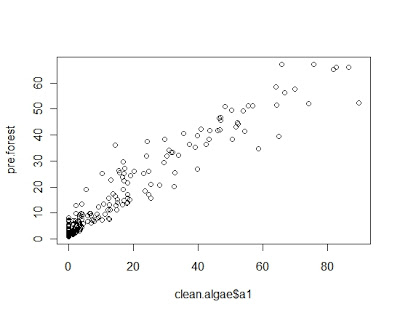
print(c(nmse1,nmse2,nmse3))
用预测值与真值之间的相对离差平方和来作为测量误差的指标,其结果分别为:0.3541180 0.3103366 0.1002235 可以看出随机森林是最有效的。
再来看看处理分类数据的表现,利用iris数据来判断花的种类
library(randomForest)
model.forest <-randomForest(Species ~ ., data = iris)
pre.forest=predict(model.forest, iris)
table(pre.forest,iris$Species)
pre.forest setosa versicolor virginica
setosa 50 0 0
versicolor 0 50 0
virginica 0 0 50
library(rpart)
model.tree=rpart(Species ~ ., data = iris,method=’class’)
pre.tree=predict(model.tree, data = iris,type=’class’)
table(pre.tree,iris$Species)
pre.tree setosa versicolor virginica
setosa 50 0 0
versicolor 0 49 5
virginica 0 1 45
随机森林算法预测全对,而分类树模型则有六处错误。
