MapReduce简介和入门
MapReduce 是适合海量数据处理惩罚的编程模子。Hadoop是可以或许运行在利用各类语言编写的MapReduce措施: Java, Ruby, Python, and C++. MapReduce措施是平行性的,因此可利用多台呆板集群执行大局限的数据阐明很是有用的。
MapReduce措施的事情分两个阶段举办:
-
Map阶段
-
Reduce 阶段
输入到每一个阶段均是键 – 值对。另外,每一个措施员需要指定两个函数:map函数和reduce函数
整个进程要经验三个阶段执行,即
MapReduce如何事情
让我们用一个例子来领略这一点 –
假设有以下的输入数据到 MapReduce 措施,统计以下数据中的单词数量:
Welcome to Hadoop Class
Hadoop is good
Hadoop is bad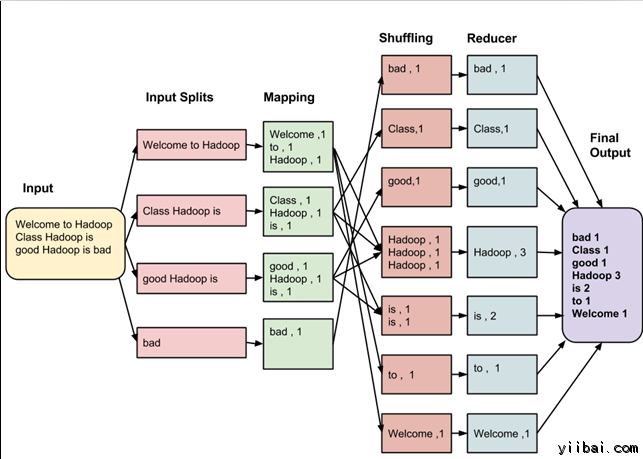

MapReduce 任务的最终输出是:
|
bad |
1 |
|
Class |
1 |
|
good |
1 |
|
Hadoop |
3 |
|
is |
2 |
|
to |
1 |
|
Welcome |
1 |
这些数据颠末以下几个阶段
输入拆分:
输入到MapReduce事情被分别成牢靠巨细的块叫做 input splits ,输入折分是由单个映射消费输入块。
映射 – Mapping
#p#分页标题#e#
这是在 map-reduce 措施执行的第一个阶段。在这个阶段中的每个支解的数据被通报给映射函数来发生输出值。在我们的例子中,映射阶段的任务是计较输入支解呈现每个单词的数量(更多具体信息有关输入支解在下面给出)并体例以某一形式列表<单词,呈现频率>
重排
这个阶段耗损映射阶段的输出。它的任务是归并映射阶段输出的相关记录。在我们的例子,同样的词汇以及它们各自呈现频率。
Reducing
在这一阶段,从重排阶段输出值汇总。这个阶段团结来自重排阶段值,并返回一个输出值。总之,这一阶段汇总了完整的数据集。
在我们的例子中,这个阶段汇总来自重排阶段的值,计较每个单词呈现次数的总和。
具体的整个进程
映射的任务是为每个支解建设在支解每笔记录执行映射的函数。
有多个支解是长处的, 因为处理惩罚一个支解利用的时间对比整个输入的处理惩罚的时间要少, 当支解较量小时,处理惩罚负载均衡是较量好的,因为我们正在并行地处理惩罚支解。
然而,也不但愿支解的局限太小。当支解太小,打点支解和映射建设任务的超负荷开始慢慢节制总的功课执行时间。
对付大大都功课,最好是支解成巨细便是一个HDFS块的巨细(这是64 MB,默认环境下)。
map任务执行功效到输出写入到当地磁盘的各个节点上,而不是HDFS。
之所以选择当地磁盘而不是HDFS是因为,制止复制个中产生 HDFS 存储操纵。
映射输出是由淘汰任务处理惩罚以发生最终的输出中间输出。
一旦任务完成,映射输出可以扔掉了。所以,复制并将其存储在HDFS变得大材小用。
在节点妨碍的映射输出之前,由 reduce 任务耗损,Hadoop 从头运行另一个节点在映射上的任务,并从头建设的映射输出。
MapReduce如何组织事情?
Hadoop 分别事情为任务。有两种范例的任务:
-
Map 任务 (支解及映射)
-
Reduce 任务 (重排,还原)
如上所述
完整的执行流程(执行 Map 和 Reduce 任务)是由两种范例的实体的节制,称为
-
Jobtracker : 就像一个主(认真提交的功课完全执行)
-
多任务跟踪器 : 充当脚色就像从机,它们每个执行事情
对付每一项事情提交执行在系统中,有一个 JobTracker 驻留在 Namenode 和 Datanode 驻留多个 TaskTracker。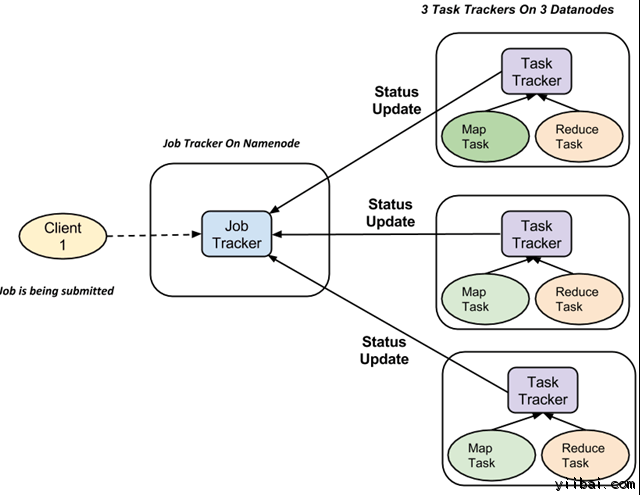
#p#分页标题#e#

功课被分成多个任务,然后运行到集群中的多个数据节点。
JobTracker的责任是协调勾当调治任务来在差异的数据节点上运行。
单个任务的执行,然后由 TaskTracker 处理惩罚,它位于执行事情的一部门,在每个数据节点上。
TaskTracker 的责任是发送进度陈诉到JobTracker。
另外,TaskTracker 周期性地发送“心跳”信号信息给 JobTracker 以便通知系统它的当前状态。
这样 JobTracker 就可以跟踪每项事情的总体进度。在任务失败的环境下,JobTracker 可以在差异的 TaskTracker 从头调治它。
