用R语言阐明我和男友的谈天记录
这篇文章或许在好几个月前就存在在脑海中。最开始是看了《迟到的恋人节礼品:做一个与她微信谈天的词云吧》,以为作者写的很好玩,谁人时候因为事情的原因刚开始进修R语言,一窍不通,我就想着那就用R学着同样阐明一遍好了,应该能收获不少。于是,我开始阐明和男友的微信谈天记录,只不外正如原文作者所说,阐明着,恋人节变恋人劫怎么办?Anyway, 本日是来交功课的。
获取数据源首先《迟到的恋人节礼品:做一个与她微信谈天的词云吧》一文中的作者已经写的很是具体了,我也完全凭据原文章中的步调操纵。不外在这里给各人两小提示:1)网上有种种提取微信谈天记录的软件或攻略,每个mac版都试过,都不行行,最后只有iMazing可以乐成提取。2)iMazing, 必然要下载正版,我就是因为误下盗版,差点把手机毁掉,到此刻手机感受照旧有点坏坏的(后遗症)。这个软件成果强大,用欠好的话IPhone变板砖。
原文是用Python写,下面是我的R代码,略有差异。本人代码本领为0,太巨大轮回算法都写不了,只能凭据本身的思路一点点拼出来。library(RSQLite)library(plyr)//毗连SQLitle数据库
conn <- dbConnect(dbDriver(“SQLite”), dbname=”MM.sqlite”)//配置毗连函数
doCountQuery <- function(conn,table){ query <- paste(“SELECT COUNT(name) FROM “,table,sep =””) t <- dbGetQuery(conn,query) return(t)}
table_name <- dbGetQuery(conn, “SELECT name FROM sqlite_master where type=’table’ and name like ‘Chat_%’ order by name”)//取出所有表名,由于不会遍历,只能凭据最笨的步伐,计较哪个表的数据量最多,等于和男盆友的谈天记录表,假如不是和男盆友的谈天表,此要领是找不出来
counts <- numeric(0)for (i in 1:length(table_name) ){ count <- doCountQuery(conn,table_name[i]) counts[i] <-count[[1]] }//计较表长table_count <- data.frame(counts)
//排序,表长较大的表,等于和男伴侣的谈天记录表table_count1 <- table_count[order(table_count$counts,decreasing=TRUE),]
//提取到谈天内容message <- dbGetQuery(conn, “SELECT * FROM Chat_XXXXXXXXXX “)文天职析拿到数据后就是举办文天职割,由于数据量实在复杂,我的电脑已经跑死好屡次。厥后,在完全不懂,也不知如何求解的环境下,靠部门代码和部门Excel相互切换,获得了想要的功效。library(jiebaRD)library(jiebaR)
library(data.table)library(stringr)
cutter=worker()wechat_content =messagewechat_content <- as.character(wechat_word$V1)///由于数据量过大,不知道为什么只用cuter无法把所有数据都遍历到,无奈只能写简朴的函数每一条遍历切割
cut_y <- function (y){ y=gsub(“\\.”,””,y) cutter[as.character(y)]}//遍历切割每一条谈天内容y.out <- sapply(wechat_content,cut_y,USE.NAMES = F)
//去除数字y.out<-gsub(“[0-9]+?”,””,y.out)
// 去除遏制词s <- read.csv(‘stopwords.csv’)stopwords <- c(NULL)for (i in 1:length(s)){ stopwords[i] <- s[i]}y.out <- filter_segment(y.out,stopwords)
//遍历计数后再组合到一起wechat_content_whole <- as.array(0)for (i in 1:length(y.out)){ table_content <- count(y.out[[i]]) wechat_content_whole <- rbind(wechat_content_whole,table_content)}
//最后计数wechat_content_whole <- count(wechat_content_whole,”x”)
//从大到小分列wechat_content_whole<- wechat_content_whole[order(wechat_content_whole$freq,decreasing=TRUE),]
//提取前1000条做词云wechat_words_final <- table_content_whole_final[1:1000,]
//颜色从粉到白函数clufunc <- colorRampPalette(c(“pink”,”white”))
//形成词云 wordcloud2(wechat_words_final, fontFamily = “HYTangTangCuTiJ”, figPath = “love.jpg”, size=1, color=clufunc(1000))功效
一年零三个月344442行17万+
这次的阐明一共收集了一年零三个月的谈天记录,总提取34442行数据,17万+个分词,下面的图就是最后提取的前1000个高频词的词云。
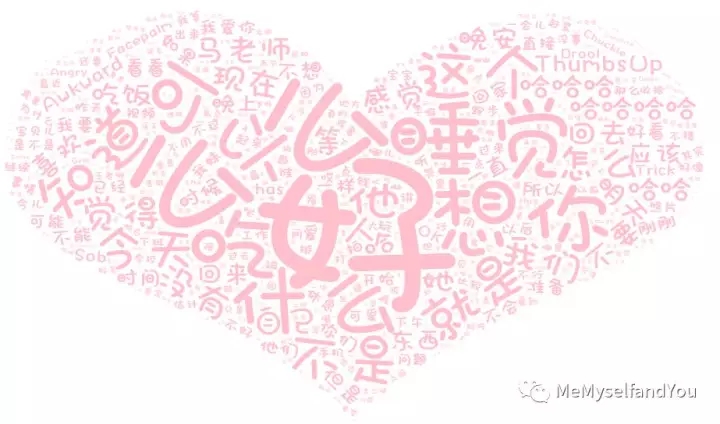
在进程中也发明白一些别样的对象:

“马老师”的字眼重复呈现,这毫不是补习班的老师,更不是礼服诱惑,马老师,一起加油
别的,在我们的谈天内容中,最常用的十大emoji竟是它们:
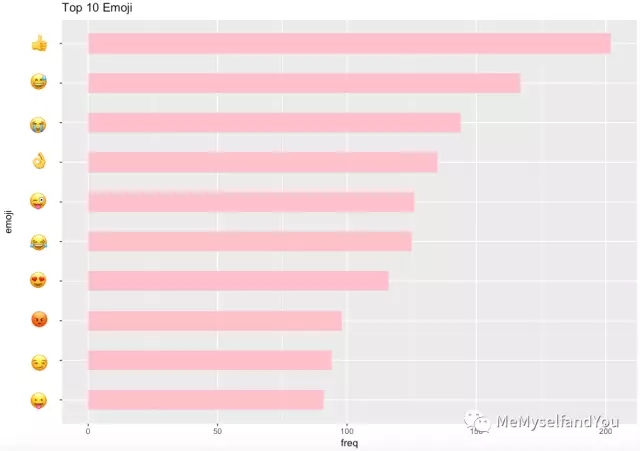
点赞最多,看来我们相互很承认对方,可是生气为啥也那么多?
另外,我还挑出已往N次打骂的谈天记录,做了下面的图。恋人之间的打骂或许都大同小异吧,没有安详感,相互拒绝着对方,说着伤人的话。

后话这个一次次丢掉又捡起来的小进修功课终于划上了一个句号。阐明的进程简直疾苦,一方面要进修各类语法,另一方面,掀开谈天记录就像扒开本身的肉一样疼,回想一幕幕,开心惆怅百感交集。这之间有本身的苍茫,有学术的蒙昧,也有恋爱的探索,幸好,我们依旧,联袂走在一起。
这个小阐明同时也是一个起点,这几个月在R语言上收获颇多。没想到开始的机遇巧合燃起了对R的热情。进修进程,不像学校里的课程讲课,险些都是想实现一个成果,于是去查找,找到一个语法,接洽到更多的常识,接洽,接洽,最后再串起来。
记得从最一开始rJava包在我的电脑上没法安装,在Google上翻过所有的问答,StackOverflow成了我泡得最多的网站,远在英国的同学也资助解答。。。每一次重复调代码的时候,都是深夜破晓,可当调好的瞬间又那么欣喜如狂。
再转头看,这个小功课很简朴,可是从中已经学到了R语言里险些所有的基本语法,固然中间部门的算法还很缭乱,至少为本身感想自满。此刻可以任意用ggplot画一个大度的统计图,而不是千篇一律的Excel。虽然,假如有大神能拯救我以上混乱的算法,接待指导进修,也但愿下一个进修项目能分享和发明更多有趣的对象。
接待插手本站果真乐趣群贸易智能与数据阐明群乐趣范畴包罗各类让数据发生代价的步伐,实际应用案例分享与接头,阐明东西,ETL东西,数据客栈,数据挖掘东西,报表系统等全方位常识QQ群:81035754
