同时用R语言和Python爬取知乎美图
作者:杜雨,EasyCharts团队成员,R语言中文社区专栏作者,乐趣偏向为:Excel商务图表,R语言数据可视化,地理信息数据可视化。
进修Python已有两月有余,是时候检讨下进修结果了,之前操练了不少R语言数据爬取,Python的爬虫模块还没有来得及当真入门,乱拼乱凑就慌忙的开始了,本日就实验着利用R+Python来举办图片爬取,完成一个简朴得小爬虫。
方针网址在这里:https://www.zhihu.com/question/35931586/answer/206258333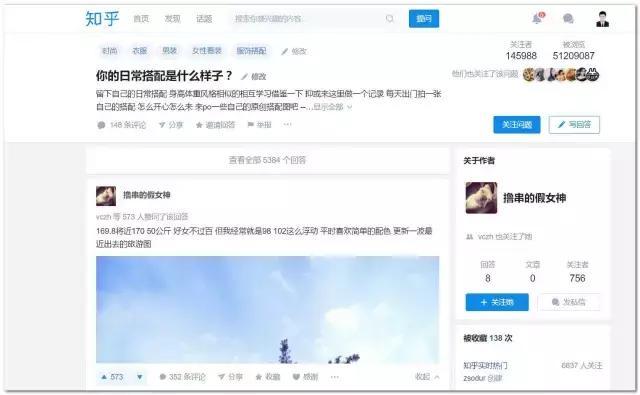
R语言版:library(rvest)library(downloader)url<-“https://www.zhihu.com/question/35931586/answer/206258333”
link<- read_html(url)%>% html_nodes(“div.RichContent-inner>span”)%>%html_nodes(“img”)%>%html_attr(“data-original”)%>%na.omit #借助Chrome的审查元素成果,借助其路径copy成果精准定位图片地址节点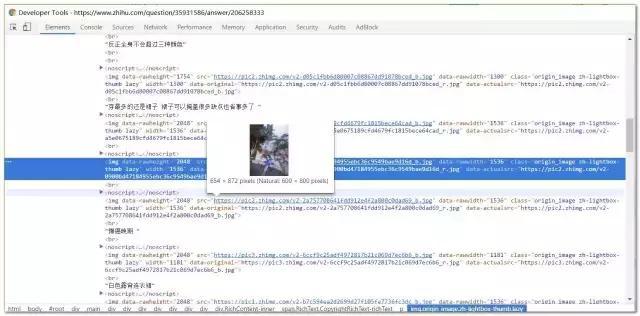
link<-link[seq(1,length(link),by=2)] #剔除无效网址Name<-sub(“https://pic\\d.zhimg.com/v2-“,””,link) #提取图片名称dir.create(“D:/R/Image/zhihu/zhihu0807”) #成立存储文件夹setwd(“D:/R/Image/zhihu/zhihu0807”) #锁定姑且目次for(i in 1:length(link)){download(link[i],Name[i], mode = “wb”)} #下载进程:
———–Python:———
import requestsfrom bs4 import BeautifulSoupimport osimport reimport urllib
方针网址:url=”https://www.zhihu.com/question/35931586/answer/206258333″
header = {‘User-Agent’: ‘Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.104 Safari/537.36′}page=requests.get(url,headers=header) #读取网址soup=BeautifulSoup(page.text,’lxml’) #理会地点
link_list=soup.select(“div[class=’RichContent-inner’] span img”)[::2]#利用CSS选择器提取图片 地点地址节点os.makedirs(“D:/Python/Image/zhihu0807″)os.chdir(‘D:/Python/Image/zhihu0807’)for link in link_list: mylink=link.get(‘data-original’) #利用get要领提取图片地点: name=re.findall(r”v2-.*?\.jpg”,mylink)[0] #匹配图片名称 urllib.request.urlretrieve(mylink,name) #下载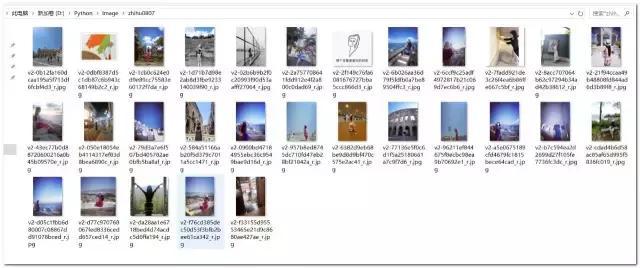 完整代码:
完整代码:
R语言版:library(rvest)library(downloader)url<-“https://www.zhihu.com/question/35931586/answer/206258333″link<- read_html(url)%>% html_nodes(“div.RichContent-inner>span”)%>%html_nodes(“img”)%>%html_attr(“data-original”)%>%na.omit link<-link[seq(1,length(link),by=2)] #剔除无效网址Name<-sub(“https://pic\\d.zhimg.com/v2-“,””,link) #提取图片名称dir.create(“D:/R/Image/zhihu/zhihu0807”) #成立存储文件夹setwd(“D:/R/Image/zhihu/zhihu0807”) #锁定姑且目次for(i in 1:length(link)){download(link[i],Name[i], mode = “wb”)} #下载进程:
Python版:import requestsfrom bs4 import BeautifulSoupimport osimport reimport urllib url=”https://www.zhihu.com/question/35931586/answer/206258333″header = {‘User-Agent’: ‘Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.104 Safari/537.36′}page=requests.get(url,headers=header)soup=BeautifulSoup(page.text,’lxml’)link_list=soup.select(“div[class=’RichContent-inner’] span img”)[::2]os.makedirs(“D:/Python/Image/zhihu0807″)os.chdir(‘D:/Python/Image/zhihu0807’)for link in link_list: mylink=link.get(‘data-original’) name=re.findall(r”v2-.*?\.jpg”,mylink)[0] urllib.request.urlretrieve(mylink,name)
接待插手本站果真乐趣群贸易智能与数据阐明群乐趣范畴包罗各类让数据发生代价的步伐,实际应用案例分享与接头,阐明东西,ETL东西,数据客栈,数据挖掘东西,报表系统等全方位常识QQ群:81035754
