此帖子显示如何使用非常相似的结果使用GGPLT2.

数据导入
上赛季美国 NBA 篮球统计中使用的流量数据databasebasketball.com可直接从其网站下载具有该数据的 CSV 文件。
> nba <- read.csv (http://datasets.flowingdata.com/ppg2008.csv |
玩家按得分排序,名字变量转换为确保情节正确排序的因素。
> nba$Name <- with(nba, reorder(Name, PTS)) |
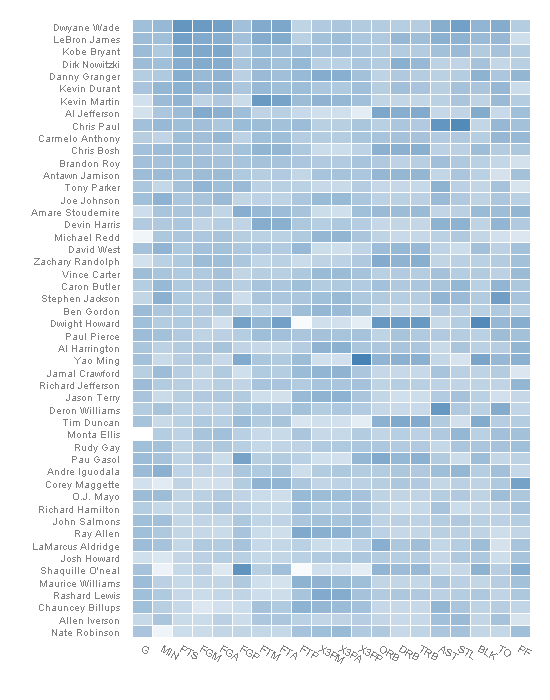
同时 FlowingData 使用热图功能统计信息-需要绘制的值为矩阵格式的包,GGPLT2使用数据文件进行操作。为了便于处理,数据文件 RAME 从宽格式转换为长格式。
游戏统计具有非常不同的范围,使得它们能够比较所有的个体统计信息。
> library(ggplot2) |
> nba.m <- melt(nba) > nba.m <- ddply(nba.m, .(variable), transform, + rescale = rescale(value)) |
绘图
没有特定的热图绘图功能GGPLT2但结合了Geom _ tile用平滑的梯度填充很好地完成工作。
> (p <- ggplot(nba.m, aes(variable, Name)) + geom_tile(aes(fill = rescale), + colour = "white") + scale_fill_gradient(low = "white", + high = "steelblue")) |
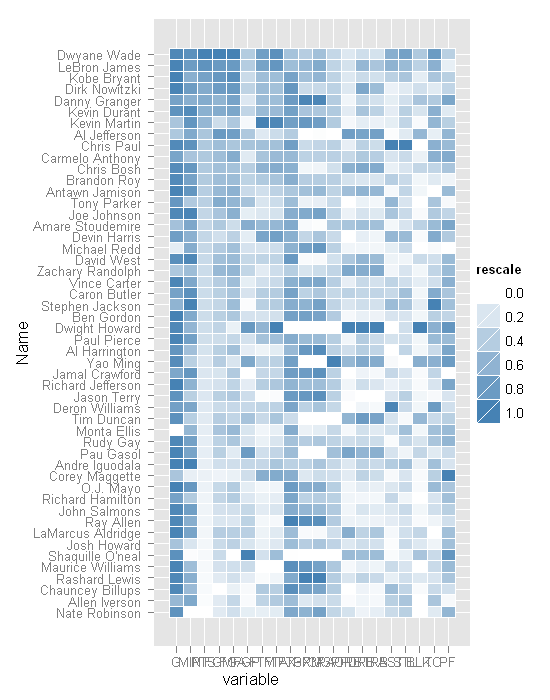
对格式化进行了少量整理,并准备了 “热贴图” 图以进行演示。
> base_size <- 9 > p + theme_grey(base_size = base_size) + labs(x = "", + y = "") + scale_x_discrete(expand = c(0, 0)) + + scale_y_discrete(expand = c(0, 0)) + opts(legend.position = "none", + axis.ticks = theme_blank(), axis.text.x = theme_text(size = base_size * + 0.8, angle = 330, hjust = 0, colour = "grey50")) |
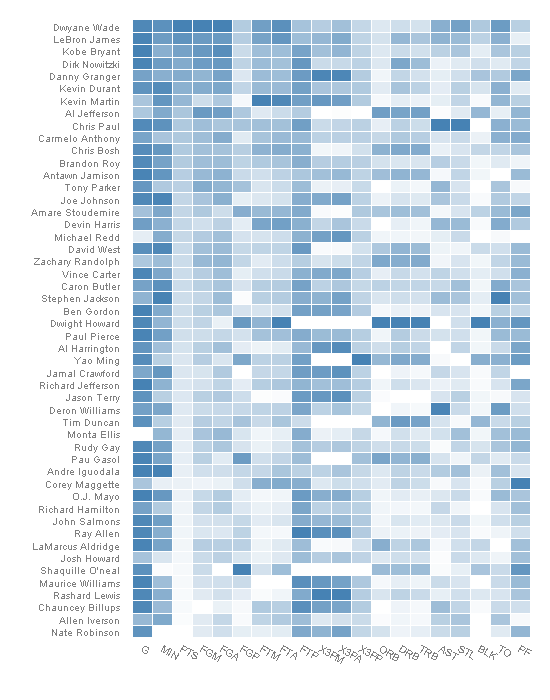
更新更新
在制备上述图的数据时,所有的变量都被随机化,以便它们在0和1之间。
吉姆在评论中正确地指出(而我并不知道这一点)热图-函数使用不同的缩放方法,因此曲线不相同。下面是热贴图的更新版本,它看起来更类似于原始贴图。
> nba.s <- ddply(nba.m, .(variable), transform, + rescale = scale(value)) |
> last_plot() %+% nba.s |