R语言教程之NLP(自然语言处理) 标记化
NLP(自然语言处理)中的一个常见任务是标记化。“令牌”通常是单个词(至少在像英语这样的语言中),“标记化”是将文本或一组文本分解成单个词。然后将这些令牌用作其他类型分析或任务的输入,如解析(自动标记单词之间的语法关系)。
在本教程中,您将学习如何:
-
将文本读入R
-
只选择某些行
-
使用tidytext软件包对文本进行标记
-
计算令牌频率(每个令牌在数据集中出现的频率)
-
编写可重复使用的功能来完成上述所有操作,并使您的工作具有可重复性
在本教程中,我们将使用双语儿童英语口语的转录语音。您可以在此数据集中找到更多信息并在此处下载。
这个孩子的演讲数据集非常酷,但它有点怪异的文件格式。这些文件是由CLAN制作的, CLAN是一个录制儿童言语的专门程序。然而,它们只是带有一些额外格式的文本文件。通过一些文本处理,我们可以将它们视为纯文本文件。
让我们这样做,并找出不同的孩子多长时间使用不同的流利程度(像“呃”或“呃”这样的词)和他们接触英语的时间之间是否存在关系。
|
1
2
3
4
五
6
7
8
9
|
# load in libraries we'll needlibrary(tidyverse) #keepin' things tidy
library(tidytext) #package for tidy text analysis (Check out Julia Silge's fab book!)
library(glue) #for pasting strings
library(data.table) #for rbindlist, a faster version of rbind
# now let's read in some data & put it in a tibble (a special type of tidy dataframe)file_info <- as_data_frame(read.csv("../input/guide_to_files.csv"))
head(file_info)
|
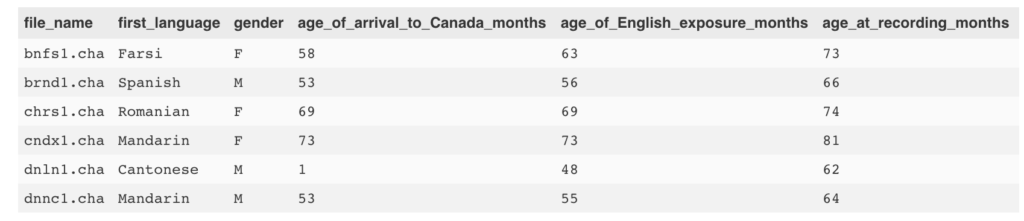
好吧,这一切看起来不错。现在,让我们以该.csv中的文件名称并将其中一个读入R.
|
1
2
3
4
五
6
7
8
9
10
|
# stick together the path to the file & 1st file name from the information file
|