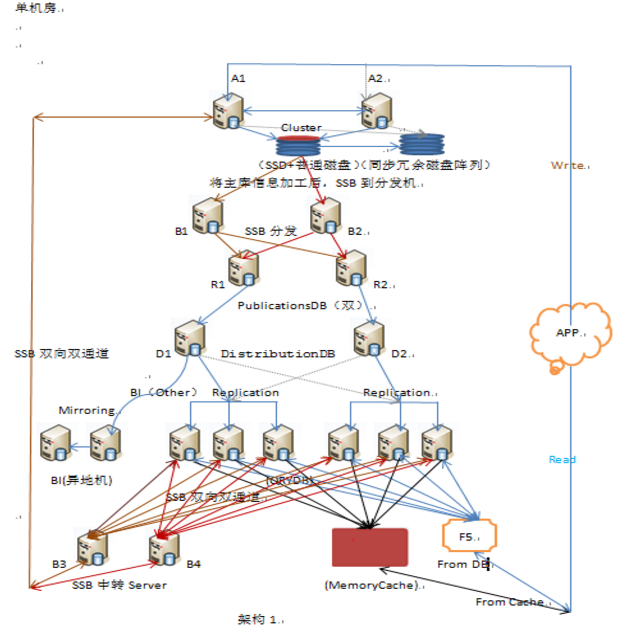
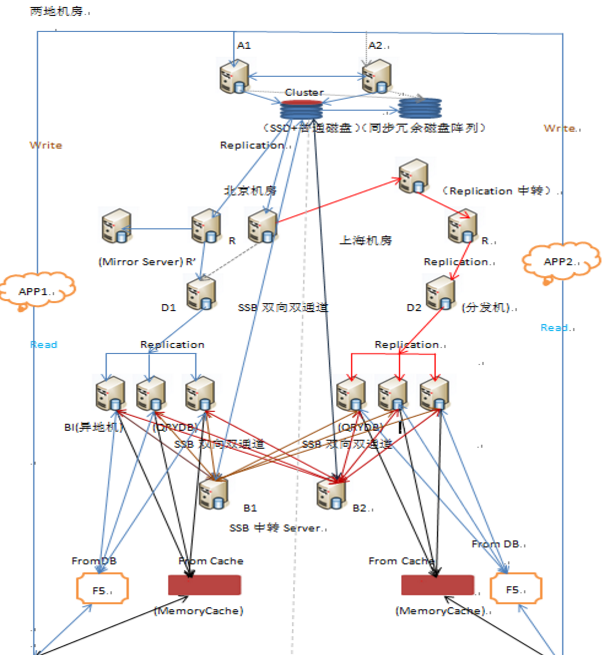
数据库架构美在哪里?
一度DBA被误读为是一个夕阳职业,究其原因是十年之前,有专职DBA的公司可以说少之又少,早期的DBA都是从开发转过来的,做的人多了,也就有专职DBA这个概念,进而很多不愿意写代码的人也纷纷投身其中。各个公司也出于系统安全和精细分工的考虑,开始禁止DBA了解、熟悉业务,禁止DBA访问业务数据等,以至于现在很多DBA没有开发能力,也不懂得业务应用,仅仅是一个数据库技术的支持者。
早期的DBA为什么能备受**,不仅仅是因为物以稀为贵,更多的是因为有开发背景,了解业务流程,具备复合能力,这才是最可贵的。可以说不懂得DBA技能的开发不是好开发,不懂得开发的DBA不是好DBA。
可喜的是,随着时间的发展,大家都开始意识到这个问题,于是数据库架构师的概念应运而生,他们是一群复合能力的拥有者,是开发人员和DBA之间的桥梁。然而,复合能力也是有较强的行业依赖性的,没有可以跨行业的万能复合,也没有能完全跨行业实现的万能数据库架构。
数据库架构需要考虑的问题:
①数据可靠和一致性;
②数据容灾;
③当数据量和访问压力变大时,方便扩充;
④高度可用,出问题时能及时恢复,无单点故障;
⑤不应因为某一台机器出现问题,导致整网性能的急剧下降;
⑥方便维护;
数据库架构一般从简单到复杂的过程:
1、一主一从
由一台主库和一台从库组成,从库只用作备份和容灾,当主库出现故障时,从库就手动变成主库
随着压力的增加,加上了memcached
单主机
最开始网站一般都是由典型的LAMP架构演变而来的,一般都是一台Linux主机,一台apache服务器,php执行环境以及MySQL服务器,一般情况下,这些都在一台虚拟主机上,简称单主机模式。
单主机模式缺点:
1web服务器和mysql服务器公用一台主机,共享硬件资源,可能存在某一方资源征用太大,导致整个应用产生瓶颈
2当业务增长之后,没有办法做到横向扩展。
3容错性太差,一旦主机存在问题,整个应用不可用
2、一主多从
通过添加多个从库来分流查询压力
独立主机
随着业务的发展,可以把mysql服务器和web服务器主机分开,分别部署,就是独立主机模式。
独立主机模式下,web服务器和mysql不再共享硬件资源,分别部署。没有把鸡蛋放在一个篮子里面,增加了容错性。如果只是mysql服务器故障,那么对于web上不访问服务器的应用是不会受到影响的。而且web服务器可以做到横向扩展,如果web服务器性能不够,可以增加多台web服务器,进行负载均衡,分散web服务器的压力。
3、随着数据量的增加,读写压力都迅速增加,
进行数据库拆分,将数据存放到不同的数据库服务器中
独立主机模式缺点:
1.可扩展性问题:虽然web服务器可以做到横向扩展,但是mysql服务器是没有办法做到横向扩展的。
2.可用性问题:mysql服务器存在单点问题,一旦mysql服务器宕机,对影响的影响很大
3.性能问题:单台mysql服务器能够支撑的服务是有限的。
数据库拆分
一般可以按两个纬度来拆分数据:
(1)垂直拆分
按功能模块拆分,多个数据库之间的表结构不同
(2)水平拆分
将同一个表的数据进行分块保存到不同的数据库中,数据库中的表结构相同
读写分离
随着业务的不断发展,数据库的压力会越来越大,单数据库慢慢的就不能满足需求了,一些网站对数据实时性要求不高,就会慢慢发展读写分离模式,对于普通的查询请求,分配到读库(也可以说是备库),对于修改请求,在主库上完成。对于读库,由于是无状态的,可以做到横向扩展。对于写库,还只能是单台主机
这种模式其实有限制的,要根据业务的类型来考虑。主库的数据是最新的,但是同步到读库会有时延,所以应用必须能够容忍短暂的不一致性。对于一致性要求非常高的场景是不适合的。
这种模式的存在的问题:
1.可扩展性:虽然读库可以做到横向扩展,但是写库还不行,读库不能够横向扩展
2.可用性:读库成为单点,一旦故障,影响所有的写操作业务拆分规则
常见的拆分方式是对表中某列值的范围或者hash值拆分,比如ID在0-10000之间的用户对应到数据库A,ID在10000-20000这个范围的对应到数据库B
#p#分页标题#e#
这种方法实现起来比较方便高效,但是不能满足后续的伸缩性要求,如果需要增加数据库节点,必需调整算法或移动很大的数据集,比较难做到在不停止服务的前提下进行扩充数据库节点
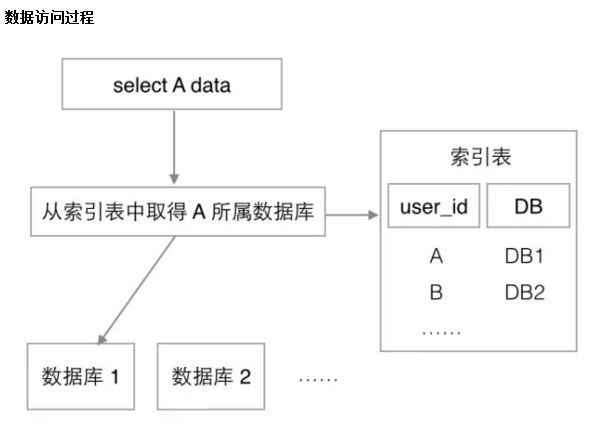
采用的拆分方法有:映射表
①这种方法是指建立一个索引表,保存每个用户ID和数据库ID的对应关系,每次读写用户数据时先从这个表获取对应数据库,新用户注册后,在所有可用的数据库中随机挑选一个为其建立索引
②把索引表进行缓存,提高检索性能
数据迁移
如果需要平衡各个节点的压力,需要进行数据的迁移
例如要迁移用户A的数据
(1)将A状态置为迁移数据中,这个状态的用户不能进行写操作,并在页面上进行提示
(2)然后将用户A的数据全部复制到新增加的节点上
(3)更新映射表
(4)将用户A的状态置为正常
(5)将原数据库上的数据删除
数据访问过程
拆分带来的问题
(1)跨库关联查询
如果需要查询的数据分布于不同的数据库,不便于通过JOIN的方式查询获得
比如要获得好友的最新照片,不能保证所有好友的数据都在同一个数据库里,需要通过多次查询,再进行聚合
有些需求可以通过保存多份数据来解决,例如用户A、用户B的数据库分别是DB1、DB2,当A评论了B作品时
先在B所在DB2中photo_comments表插入记录,记录B的哪个作品被谁评论了什么内容
然后在A所在DB1中user_comments表插入记录,记录A给哪个作者的哪个作品发表过评论
这样可以通过photo_comments得到B的某张照片的所有评论,也可以通过user_comments获得A发布过的所有评论
(2)不能保证数据的一致/完整性
跨库的数据没有外键约束,也没有事务保证,比如上面评论照片的例子,很可能出现成功插入photo_comments表,但是插入user_comments表时却出错了
可以在两个库上都开启事务,然后先插入photo_comments,再插入user_comments,然后提交两个事务,但不能完全保证这个操作的原子性
(3)自增ID
增加了一个专门用来生成ID的数据库,表结构很简单,只有一个自增字段id
例如要插入评论时,先在ID库的photo_comments表里插入一条空的记录,以获得一个唯一的评论ID
定期清理ID库的数据,以保证获取新ID的效率
小编结语:
更多内容尽在课课家教育~~
