Java理论与实践: 构建一个更好的HashMap
副标题#e#
ConcurrentHashMap 是 Doug Lea的 util.concurrent 包的一部门,它提供 比Hashtable 可能 synchronizedMap 更高水平的并发性。并且,对付大大都成 功的 get() 操纵它会设法制止完全锁定,其功效就是使得并发应用措施有着非 常好的吞吐量。这个月,BrianGoetz 仔细阐明白 ConcurrentHashMap的代码, 并探讨 Doug Lea 是如安在不损失线程安详的环境下取得这么骄人后果的。
在7月份的那期 Java理论与实践(“ Concurrent collections classes”) 中,我们简朴地回首了可伸缩性的瓶颈,并接头了怎么用共享数据布局的要领获 得更高的并发性和吞吐量。有时候进修的最好要领是阐明专家的成就,所以这个 月我们将阐明 Doug Lea的 util.concurrent 包中的 ConcurrentHashMap的实现 。JSR 133 将指定 ConcurrentHashMap的一个版本,该版本针对 Java 内存模子 (JMM)作了优化,它将包括在JDK 1.5的 java.util.concurrent 包中。 util.concurrent 中的版本在老的和新的内存模子中都已通过线程安详审核。
针对吞吐量举办优化
ConcurrentHashMap 利用了几个能力来得到高水平的并发以及制止锁定,包 括为差异的 hash bucket(桶)利用多个写锁和利用 JMM的不确定性来最小化锁 被保持的时间――可能基础制止获取锁。对付大大都一般用法来说它是颠末优化 的,这些用法往往会检索一个很大概在map 中已经存在的值。事实上,大都乐成 的 get() 操纵基础不需要任何锁定就能运行。(告诫:不要本身试图这样做! 想比 JMM 智慧不像看上去的那么容易。 util.concurrent 类是由并发专家编写 的,而且在JMM 安详性方面颠末尾严格的同行评审。)
多个写锁
我们可以追念一下,Hashtable(可能替代方案 Collections.synchronizedMap )的可伸缩性的主要障碍是它利用了一个 map 范畴(map-wide)的锁,为了担保插入、删除可能检索操纵的完整性必需保持这 样一个锁,并且有时候甚至还要为了担保迭代遍历操纵的完整性保持这样一个锁 。这样一来,只要锁被保持,就从基础上阻止了其他线程会见 Map,纵然处理惩罚器 有空闲也不能会见,这样大大地限制了并发性。
ConcurrentHashMap 摒弃了单一的 map 范畴的锁,取而代之的是由 32 个锁 构成的荟萃,个中每个锁认真掩护 hash bucket的一个子集。锁主要由变革性操 作( put() 和remove() )利用。具有 32 个独立的锁意味着最多可以有 32 个 线程可以同时修改 map。这并不必然是说在并发地对 map 举办写操纵的线程数 少于 32 时,别的的写操纵不会被阻塞――32 对付写线程来说是理论上的并发 限制数目,可是实际上大概达不到这个值。可是,32 依然比 1 要好得多,并且 对付运行于今朝这一代的计较机系统上的大大都应用措施来说已经足够了。  
map 范畴的操纵
有 32 个独立的锁,个中每个锁掩护 hash bucket的一个子集,这样需要独 占会见 map的操纵就必需得到所有32个锁。一些 map 范畴的操纵,好比说 size() 和isEmpty(), 也许可以或许不消一次锁整个 map(通过适内地限定这些操 作的语义),可是有些操纵,好比 map 重排(扩大 hash bucket的数量,跟着 map的增长从头漫衍元素),则必需担保独有会见。Java 语言不提供用于获取可 变巨细的锁荟萃的轻便要领。必需这么做的环境很少见,一旦遇到这种环境,可 以用递归要领来实现。
JMM概述
在进入 put() 、 get() 和remove()的实现之前,让我们先简朴地看一下 JMM。JMM 掌管着一个线程对内存的行动(读和写)影响其他线程对内存的行动 的方法。由于利用处理惩罚器寄存器和预处理惩罚 cache 来提高内存会见速度带来的性 能晋升,Java 语言类型(JLS)答允一些内存操纵并差池于所有其他线程当即可 见。有两种语言机制可用于担保跨线程内存操纵的一致性―― synchronized 和 volatile。
凭据 JLS的说法,“在没有显式同步的环境下,一个实现可以自由地更新主 存,更新时所采纳的顺序大概是出人意表的。”其意思是说,假如没有同步的话 ,在一个给定线程中某种顺序的写操纵对付别的一个差异的线程来说大概泛起出 差异的顺序, 而且对内存变量的更新从一个线程流传到别的一个线程的时间是 不行预测的。
固然利用同步最常见的原因是担保对代码要害部门的原子会见,但实际上同 步提供三个独立的成果――原子性、可见性温顺序性。原子性很是简朴――同步 实施一个可重入的(reentrant)互斥,防备多于一个的线程同时执行由一个给 定的监督器掩护的代码块。不幸的是,大都文章都只存眷原子性方面,而忽略了 其他方面。可是同步在JMM 中也饰演着很重要的脚色,会引起 JVM 在得到和释 放监督器的时候执行内存壁垒(memory barrier)。
#p#分页标题#e#
一个线程在得到一个监督器之后,它执行一个 读屏障(read barrier)―― 使得缓存在线程局部内存(好比说处理惩罚器缓存可能处理惩罚器寄存器)中的所有变量 都失效,这样就会导致处理惩罚器从头从主存中读取同步代码块利用的变量。与此类 似,在释放监督器时,线程会执行一个 写屏障(write barrier)――将所有修 悔改的变量写回主存。互斥独有和内存壁垒团结利用意味着只要您在措施设计的 时候遵循正确的同步法例(也就是说,每当写一个后头大概被其他线程会见的变 量,可能读取一个大概最后被另一个线程修改的变量时,都要利用同步),每个 线程城市获得它所利用的共享变量的正确的值。
假如在会见共享变量的时候没有同步的话,就会产生一些奇怪的工作。一些 变革大概会通过线程当即反应出来,而其他的则需要一些时间(这由关联缓存的 本质所致)。功效,假如没有同步您就不能担保内存内容肯定一致(相关的变量 彼此间大概会纷歧致),可能不能获得当前的内存内容(一些值大概是过期的) 。制止这种危险环境的常用要领(也是推荐利用的要领)虽然是正确地利用同步 。然而在有些环境下,好比说在像 ConcurrentHashMap 之类的一些利用很是广 泛的库类中,在开拓进程傍边还需要一些特另外专业技术和尽力(大概比一般的 开拓要多出许多倍)来得到较高的机能。
#p#副标题#e#
ConcurrentHashMap 实现
如前所述, ConcurrentHashMap 利用的数据布局与 Hashtable 或 HashMap 的实现雷同,是 hash bucket的一个可变数组,每个 ConcurrentHashMap 都由 一个 Map.Entry 元素链组成,如清单1所示。与 Hashtable 和HashMap 差异的 是, ConcurrentHashMap 没有利用单一的荟萃锁(collection lock),而是使 用了一个牢靠的锁池,这个锁池形成了bucket 荟萃的一个分区。
清单1. ConcurrentHashMap 利用的 Map.Entry 元素
protected static class Entry implements Map.Entry {
protected final Object key;
protected volatile Object value;
protected final int hash;
protected final Entry next;
...
}
不消锁定遍历数据布局
与 Hashtable 可能典范的锁池 Map 实现差异, ConcurrentHashMap.get() 操纵不必然需要获取与相关bucket 相关联的锁。假如不利用锁定,那么实现必 须有本领处理惩罚它用到的所有变量的过期的可能纷歧致的值,好比说列表头指针和 Map.Entry 元素的域(包罗构成每个 hash bucket 条目标链表的链接指针)。
大多并发类利用同步来担保独有式会见一个数据布局(以及保持数据布局的 一致性)。 ConcurrentHashMap 没有回收独有性和一致性,它利用的链表是经 过经心设计的,所以其实现可以 检测 到它的列表是否一致可能已颠末期。假如 它检测到它的列表呈现纷歧致可能过期,可能爽性就找不到它要找的条目,它就 会对适当的bucket 锁举办同步并再次搜索整个链。这样做在一般的环境下可以 优化查找,所谓的一般环境是指大大都检索操纵是乐成的而且检索的次数多于插 入和删除的次数。
利用稳定性
纷歧致性的一个重要来历是可以制止得,其要领是使 Entry 元素靠近稳定性 ――除了值字段(它们是易变的)之外,所有字段都是 final的。这就意味着不 能将元素添加到 hash 链的中间或末端,可能从 hash 链的中间或末端删除元素 ――而只能从 hash 链的开头添加元素,而且删除操纵包罗克隆整个链或链的一 部门并更新列表的头指针。所以说只要有对某个 hash 链的一个引用,纵然大概 不知道有没有对列表头节点的引用,您也可以知道列表的其余部门的布局不会改 变。并且,因为值字段是易变的,所以可以或许当即看到对值字段的更新,从而大大 简化了编写可以或许处理惩罚内存潜在过期的 Map的实现。
新的 JMM 为 final 型变量提供初始化安详,而老的 JMM 不提供,这意味着 另一个线程看到的大概是 final 字段的默认值,而不是工具的结构要领提供的 值。实现必需可以或许同时检测到这一点,这是通过担保 Entry 中每个字段的默认 值不是有效值来实现的。这样结构好列表之后,假如任何一个 Entry 字段有其 默认值(零或空),搜索就会失败,提示同步 get() 并再次遍历链。
检索操纵
检索操纵首先为方针 bucket 查找头指针(是在不锁定的环境下完成的,所 以说大概是过期的),然后在不获取 bucket 锁的环境下遍历 bucket 链。假如 它不能发明要查找的值,就会同步并试图再次查找条目,如清单2所示:
清单2. ConcurrentHashMap.get() 实现
#p#分页标题#e#
public Object get(Object key) {
int hash = hash(key); // throws null pointer exception if key is null
// Try first without locking...
Entry[] tab = table;
int index = hash & (tab.length - 1);
Entry first = tab[index];
Entry e;
for (e = first; e != null; e = e.next) {
if (e.hash == hash && eq(key, e.key)) {
Object value = e.value;
// null values means that the element has been removed
if (value != null)
return value;
else
break;
}
}
// Recheck under synch if key apparently not there or interference
Segment seg = segments[hash & SEGMENT_MASK];
synchronized(seg) {
tab = table;
index = hash & (tab.length - 1);
Entry newFirst = tab[index];
if (e != null || first != newFirst) {
for (e = newFirst; e != null; e = e.next) {
if (e.hash == hash && eq(key, e.key))
return e.value;
}
}
return null;
}
}
删除操纵
因为一个线程大概看到 hash 链中链接指针的过期的值,简朴地从链中删除 一个元素不敷以担保其他线程在举办查找的时候不继承看到被删除的值。相反, 从清单3我们可以看到,删除操纵分两个进程――首先找到适当的 Entry 工具并 把其值字段设为 null ,然后对链中从新元素到要删除的元素的部门举办克隆, 再毗连到要删除的元素之后的部门。因为值字段是易变的,假如别的一个线程正 在过期的链中查找谁人被删除的元素,它会当即看到一个空值,并知道利用同步 从头举办检索。最终,原始 hash 链中被删除的元素将会被垃圾收集。
清单3. ConcurrentHashMap.remove() 实现
protected Object remove(Object key, Object value) {
/*
Find the entry, then
1. Set value field to null, to force get() to retry
2. Rebuild the list without this entry.
All entries following removed node can stay in list, but
all preceding ones need to be cloned. Traversals rely
on this strategy to ensure that elements will not be
repeated during iteration.
*/
int hash = hash(key);
Segment seg = segments[hash & SEGMENT_MASK];
synchronized(seg) {
Entry[] tab = table;
int index = hash & (tab.length-1);
Entry first = tab[index];
Entry e = first;
for (;;) {
if (e == null)
return null;
if (e.hash == hash && eq(key, e.key))
break;
e = e.next;
}
Object oldValue = e.value;
if (value != null && !value.equals(oldValue))
return null;
e.value = null;
Entry head = e.next;
for (Entry p = first; p != e; p = p.next)
head = new Entry(p.hash, p.key, p.value, head);
tab[index] = head;
seg.count--;
return oldValue;
}
}
图1为删除一个元素之前的 hash 链:
图1. Hash链

图2为删除元素3之后的链:
图2. 一个元素的删除进程
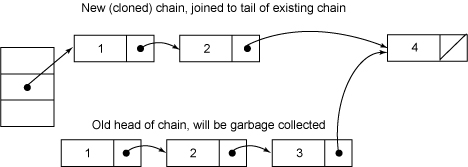
插入和更新操纵
put()的实现很简朴。像 remove() 一样, put() 会在执行期间保持 bucket 锁,可是由于 put() 并不是都需要获取锁,所以这并不必然会阻塞其他读线程 的执行(也不会阻塞其他写线程会见此外 bucket)。它首先会在适当的 hash 链中搜索需要的键值。假如可以或许找到, value 字段(易变的)就直接被更新。 假如没有找到,新会建设一个用于描写新 map的新 Entry 工具,然后插入到 bucket 列表的头部。
弱一致的迭代器
由 ConcurrentHashMap 返回的迭代器的语义又差异于 ava.util 荟萃中的迭 代器;并且它又是 弱一致的(weakly consistent)而非 fail-fast的(所谓 fail-fast 是指,当正在利用一个迭代器的时候,如何底层的荟萃被修改,就会 抛出一个异常)。当一个用户挪用 keySet().iterator() 去迭代器中检索一组 hash 键的时候,实现就简朴地利用同步来担保每个链的头指针是当前值。 next() 和hasNext() 操纵以一种明明的方法界说,即遍历每个链然后转到下一 个链直到所有的链都被遍历。弱一致迭代器大概会也大概不会反应迭代器迭代过 程中的插入操纵,可是必然会反应迭代器还没有达到的键的更新或删除操纵,并 且对任何值最多返回一次。 ConcurrentHashMap 返回的迭代器不会抛出 ConcurrentModificationException 异常。
动态调解巨细
#p#分页标题#e#
跟着 map 中元素数目标增长,hash 链将会变长,因此检索时间也会增加。 从某种意义上说,增加 bucket的数目和重排个中的值长短常重要的。在有些像 Hashtable 之类的类中,这很简朴,因为保持一个应用到整个 map的独有锁是可 能的。在ConcurrentHashMap 中,每次一个条目插入的时候,假如链的长度高出 了某个阈值,链就被标志为需要调解巨细。当有足够多的链被标志为需要调解大 小今后, ConcurrentHashMap 就利用递归获取每个 bucket 上的锁并重排每个 bucket 中的元素到一个新的、更大的 hash 表中。大都环境下,这是自动产生 的,而且对换用者透明。
不锁定?
要说不消锁定就可以乐成地完成 get() 操纵好像有点言过其实,因为 Entry 的 value 字段是易变的,这是用来检测更新和删除的。在呆板级,易变的和同 步的内容凡是在最后会被翻译成沟通的缓存一致原语,所以这里会有 一些 锁定 ,固然只是细粒度的而且没有调治,可能没有获取和释放监督器的 JVM 开销。 可是,除语义之外,在许多通用的环境下,检索的次数大于插入和删除的次数, 所以说由 ConcurrentHashMap 取得的并发性是相当高的。
竣事语
ConcurrentHashMap 对付许多并发应用措施来说是一个很是有用的类,并且 对付领略 JMM 何故取得较高机能的微妙细节是一个很好的例子。 ConcurrentHashMap 是编码的经典,需要深刻领略并发和JMM 才气够写得出。使 用它,从中学到对象,享受个中的兴趣――可是除非您是Java 并发方面的专家 ,不然的话您本身不该该这
