dySE:一个Java搜索引擎的实现,第2部门 网页预处理惩罚
副标题#e#
在 上一部门 中,您相识到如何编写一个 spider 措施来举办网页的爬取, 作为 spider 的爬取功效,我们得到了一个凭据必然名目存储的原始网页库,原 始网页库也是我们第二部门网页预处理惩罚的数据基本。网页预处理惩罚的主要方针是将 原始网页通过一步步的数据处理惩罚酿成可利便搜索的数据形式。下面就让我们慢慢 先容网页预处理惩罚的设计和实现。
预处理惩罚模块的整体布局
预处理惩罚模块的整体布局如下:
图 1. 预处理惩罚模块的整体布局
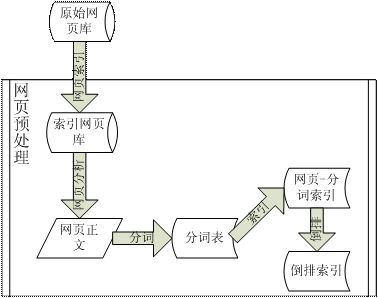
通过 spider 的收集,生存下来的网页信息具有较好的信息存储名目,可是 照旧有一个缺点,就是不能凭据网页 URL 直接定位到所指向的网页。所以,在 第一个流程中,需要先成立网页的索引,如此通过索引,我们可以很利便的从原 始网页库中得到某个 URL 对应的页面信息。之后,我们处理惩罚网页数据,对付一 个网页,首先需要提取其网页正文信息,其次对正文信息举办分词,之后再按照 分词的环境成立索引和倒排索引,这样,网页的预处理惩罚也全部完成。大概读者对 于个中的某些专业术语会有一些不大白之处,在后续详述各个流程的时候会给出 相应的图可能例子来辅佐各人领略。
成立索引网页库
原始网页库是凭据名目存储的,这对付网页的索引成立提供了利便,下图给 出了一条网页信息记录:
清单 1. 原始网页库中的一条网页记录
xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx // 之前的记录
version:1.0 // 记录头部
url:http://ast.nlsde.buaa.edu.cn/
date:Mon Apr 05 14:22:53 CST 2010
IP:218.241.236.72
length:3981
<!DOCTYPE …… // 记录数据部门
<html> …… </html>
xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx // 之后的记录
xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
#p#副标题#e#
我们回收“网页库名—偏移”的信息对来定位库中的某条网页记录。由于数 据量较量大,这些索引网页信息需要一种生存的要领,dySE 利用数据库来生存 这些信息。数据库们回收 mysql,共同 SQL-Front 软件可以轻松举办图形界面 的操纵。我们用一个表来记录这些信息,表的内容如下:url、content、offset 、raws。URL 是某笔记录对应的 URL,因为索引数据库成立之后,我们是通过 URL 来确定需要的网页的;raws 和 offset 别离暗示网页库名和偏移值,这两 个属性独一确定了某笔记录,content 是网页内容的摘要,网页的数据量一般较 大,把网页的全部内容放入数据库中显得不是很实际,所以我们将网页内容的 MD5 摘要放入到 content 属性中,该属性相当于一个校验码,在实际运用中, 当我们按照 URL 得到某个网页信息是,可以将得到的网页做 MD5 摘要然后与 content 中的值做一个匹配,假如一样则网页获取乐成,假如纷歧样,则说明网 页获取呈现问题。
这里简朴先容一下 mySql 的安装以及与 Java 的毗连:
安装 mySql,最好需要三个组件,mySql,mySql-front,mysql-connector- java-5.1.7-bin.jar,别离可以在网络中下载。留意:安装 mySql 与 mySql- front 的时候要版本对应,MySql5.0 + MySql-Front3.2 和 MySql5.1 + MySql -Front4.1,这个组合是不能乱的,可以按拍照应的版本号来下载,不然会爆“ ‘ 10.000000 ’ ist kein gUltiger Integerwert ”的错误。
导入 mysql-connector-java-5.1.7-bin.jar 到 eclipse 的项目中,打开 eclipse,右键点需要导入 jar 包的项 目名,选属性(properties),再选 java 构建路径(java Build Path),后在右侧点 (libraries),选 add external JARs,之后选择你要导入的 jar 包确定。
接着就可以用代码来测试与 mySql 的毗连了,代码见本文附带的 testMySql.java 措施,这里限于篇幅就不在赘述。
对付数据库的操纵,我们最好举办必然的封装,以提供统一的数据库操纵支 持,而不需要在其他的类中显示的举办数据库毗连操纵,并且这样也就不需要建 立大量的数据库毗连从而造成资源的挥霍,代码详见 DBConnection.java。主要 提供的操纵是:成立毗连、执行 SQL 语句、返回操纵功效。
先容了数据库的相关操纵时候,此刻我们可以来完成网页索引库的成立进程 。这里要说明的是,第一笔记录的偏移是 0,所以在当前记录 record 处理惩罚之前 ,该记录的偏移是已经计较出来的,处理惩罚 record 的意义在于得到下一个记录在 网页库中的偏移。假设当前 record 的偏移为 offset,定位于头部的第一条属 性之前,我们通过读取记录的头部和记录的数据部门来获得该记录的长度 length,从而,offset+length 即为下一笔记录的偏移值。读取头部和读取记录 都是通过数据间的空行来标识的,其伪代码如下:
清单 2. 索引网页库成立
#p#分页标题#e#
For each record in Raws do
begin
读取 record 的头部和数据,从新部中抽取 URL;
计较头部和数据的长度,加到当前偏移值上获得新的偏移;
从 record 中数据中计较其 MD5 摘要值;
将数据插入数据库中,包罗:URL、偏移、数据 MD5 摘要、Raws;
end;
您大概会对 MD5 摘要算法有些迷惑,这是什么?这有什么用? Message Digest Algorithm MD5(中文名为动静摘要算法第五版)为计较机安详规模遍及 利用的一种散列函数,用以提供动静的完整性掩护。MD5 的典范应用是对一段信 息 (Message) 发生一个 128 位的二进制信息摘要 (Message-Digest),即为 32 位 16 进制数字串,以防备被改动。对付我们来说,好比通过 MD5 计较,某个 网页数据的摘要是 00902914CFE6CD1A959C31C076F49EA8,假如我们任意的改变 这个网页中的数据,通过计较之后,该摘要就会改变,我们可以将信息的 MD5 摘要视作为该信息的指纹信息。所以,存储该摘要可以验证之后获取的网页信息 是否与原始网页一致。
对 MD5 算法扼要的论述可觉得:MD5 以 512 位分组来处理惩罚输入的信息,且 每一分组又被分别为 16 个 32 位子分组,颠末尾一系列的处理惩罚后,算法的输出 由四个 32 位分组构成,将这四个 32 位分组级联后将生成一个 128 位散列值 。个中“一系列的处理惩罚”即为计较流程,MD5 的计较流程较量多,可是不难,同 时也不难实现,您可以直接利用网上现有的 java 版本实现可能利用本教程提供 的源码下载中的 MD5 类。对付 MD5,我们知道其成果,能利用就可以,详细的 每个步调的意义不需要深入领略。
分词
中文分词是指将一个汉字序列切分成一个一个单独的词,从而到达计较机可 以自动识此外结果。中文分词主要有三种要领:第一种基于字符串匹配,第二种 基于语义领略,第三种基于统计。由于第二和第三种的实现需要大量的数据来支 持,所以我们回收的是基于字符串匹配的要领。
基于字符串匹配的要领又叫做机器分词要领,它是凭据必然的计策将待阐明 的汉字串与一个“充实大的”呆板辞书中的词条举办配,若在辞书中找到某个字 符串,则匹配乐成(识别出一个词)。凭据扫描偏向的差异,串匹配分词要领可 以分为正向匹配和逆向匹配;凭据差异长度优先匹配的环境,可以分为最大(最 长)匹配和最小(最短)匹配。常用的几种机器分词要领如下:
正向减字最大匹配法(由左到右的偏向);
逆向减字最大匹配法(由右到左的偏向);
最少切分(使每一句中切出的词数最小);
双向最大减字匹配法(举办由左到右、由右到左两次扫描);
我们回收个中的正向最大匹配法。算法描写如下:输入值为一其中文语句 S ,以及最大匹配词
取 S 中前 n 个字,按照辞书对其举办匹配,若匹配乐成,转 3,不然转 2 ;
n = n – 1:假如 n 为 1,转 3;不然转 1;
将 S 中的前 n 个字作为分词功效的一部门,S 撤除前 n 个字,若 S 为空 ,转 4;不然,转 1;
算法竣事。
需要说明的是,在第三步的起始,n 假如不为 1,则意味着有匹配到的词; 而假如 n 为 1,我们默认 1 个字是应该进入分词功效的,所以第三步可以将前 n 个字作为一个词而支解开来。尚有需要留意的是对付停用词的过滤,停用词即 汉语中“的,了,和,么”等字词,在搜索引擎中是忽略的,所以对付分词后的 功效,我们需要在用停用词列表举办一下停用词过滤。
您也许有疑问,如何得到分词字典可能是停用词字典。停用词字典较量好办 ,由于中文停用词数量有限,可以从网上得到停用词列表,从而本身建一个停用 词字典;然而对付分词字典,固然网上有很多知名的汉字分词软件,可是很少有 分词的字典提供,这里我们提供一些在 dySE 中利用的分词字典给您。在措施使 用进程中,分词字典可以放入一个荟萃中,这样就可以较量利便的举办比对事情 。
分词的功效对付搜索的精准性有着至关重要的影响,好的分词计策常常是由 若干个简朴算法拼接而成的,所以您也可以试着实现双向最大减字匹配法来提高 分词的精确率。而假如碰着歧义词组,可以通过字典中附带的词频来抉择哪种分 词的功效更好。
倒排索引
#p#分页标题#e#
这个章节我们为您讲授预处理惩罚模块的最后两个步调,索引的成立和倒排索引 的成立。有了分词的功效,我们就可以得到一个正向的索引,即某个网页以及其 对应的分词功效。如下图所示:
图 2. 正向索引
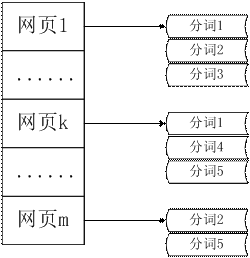
图 3. 倒排索引
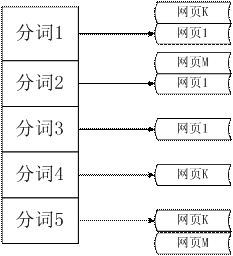
在本文的开头,我们成立了索引网页库,用于通过 URL 可以直接定位到原始 网页库中该 URL 对应的数据的位置;而此刻的正向索引,我们可以通过某个网 页的 URL 获得该网页的分词信息。得到正向索引看似对付我们的即将举办的查 询操纵没有什么实际的辅佐,因为查询处事是通过要害词来得到网页信息,而正 向索引并不能通过度词功效反查网页信息。其实,我们成立正向索引的目标就是 通过翻转的操纵成立倒排索引。所谓倒排就是相对付正向索引中网页——分词结 果的映射方法,回收分词——对应的网页这种映射方法。与图 2 相对应的倒排 索引如上图 3 所示。
接下来我们阐明如何从正向索引来获得倒排索引。算法进程如下:
对付网页 i,获取其分词列表 List;
对付 List 中的每个词组,查察倒排索引中是否含有这个词组,假如没有, 将这个词组插入倒排索引的索引项,并将网页 i 加到其索引值中;假如倒排索 引中已经含有这个词组,直接将网页 i 加到其索引值中;
假如尚有网页尚未阐明,转 1;不然,竣事
成立倒排索引的算法不难实现,主要是个中数据布局的选用,在 dySE 中, 正向索引和倒排索引都是回收 HashMap 来存储,映射中正向索引的键是回收网 页 URL 对应的字符串,而倒排索引是回收分词词组,映射中的值,前者是一个 分词列表,后者是一个 URL 的字符串列表。这里可以回收一个优化,别离成立 两个表,凭据标号存储分词列表和 URL 列表,这样,索引中的值就可以利用整 型变量列表来节减空间。
劈头尝试
到今朝为止,固然我们还没有正式的查询输入界面以及功效返回页面,但这 丝绝不影响我们来对我们的搜索引擎举办劈头的尝试。在倒排索引成立今后,我 们在措施中得到一个倒排索引的实例,然后界说一个搜索的字符串,直接在倒排 索引中遍历这个字符串,然后返回该词组所指向的倒排索引中的 URL 列表即可 。
小结
网页的预处理惩罚是搜索引擎的焦点部门,成立索引网页库是为了网页数据更方 便的从原始网页库中获取,而抽取正文信息是后续操纵的基本。从分词开始就正 式涉及到搜索引擎中文本数据的处理惩罚,分词的优劣以及效率很洪流平上抉择着搜 索引擎的准确性,长短常需要存眷的一点,而倒排索引时按照分词的功效成立的 一个“词组——对应网页列表”映射,倒排索引是网页搜索的最要害数据布局, 搜索引擎执行的速度与倒排索引的成立以及倒排索引的搜索方法息息相关。
后续内容
在本系列的第三部门中,您将相识到如何从建设网页,从网页中输入查询信 息通过倒排索引的搜索完成功效的返回,而且完成网页排名的成果。
