Map/Reduce Task JVM堆的巨细配置优化
前一阵子发明用户提交的hive query和hadoop job会导致集群的load很是高,经查察设置,发明许多用户擅自将mapred.child.java.opts配置的很是大,好比-Xmx4096m(我们默认配置是-Xmx1024m), 导致了tasktracker上内存资源耗尽,进而开始不绝swap磁盘上数据,load飙升
TaskTracker在spawn一个map/reduce task jvm的时候,会按照用户JobConf内里的值设定jvm的参数,然后写入一个taskjvm.sh文件中,然后挪用linux呼吁"bin/bash -c taskjvm.sh"来执行task,
mapred.child.java.opts就是设定jvm的参数之一,在新版本中已经标注Deprecateded,取而代之的是区分Map task和Reduce task的jvm opts,mapred.map.child.java.opts和mapred.reduce.child.java.opts(默认值为-Xmx200m)
当用户在不设该值环境下,会以最大1G jvm heap size启动task,有大概导致OutOfMemory,所以最简朴的做法就是设大参数,而且由于这个值不是final,所以用户在本身的mapred-site.xml中可以包围默认值。可是假如许多用户都无限度配置的话,high load问题就来了。
其实在结构JVM Args的进程中,是有别的一个admin参数可以包围用户端配置的mapreduce.admin.map.child.java.opts, mapreduce.admin.reduce.child.java.opts
经测试,假如沟通的jvm arg假如写在后头,好比"-Xmx4000m -Xmx1000m",后头的会包围前面的,“-Xmx1000m”会最终生效,通过这种方法,我们就可以有限度的节制heap size了
最终在mapred-site.xml中加上
<property>
<name>mapreduce.admin.map.child.java.opts</name>
<value>-Xmx1024m</value>
</property>
<property>
<name>mapreduce.admin.reduce.child.java.opts</name>
<value>-Xmx1536m</value>
</property>
结构child java opts的call stack:
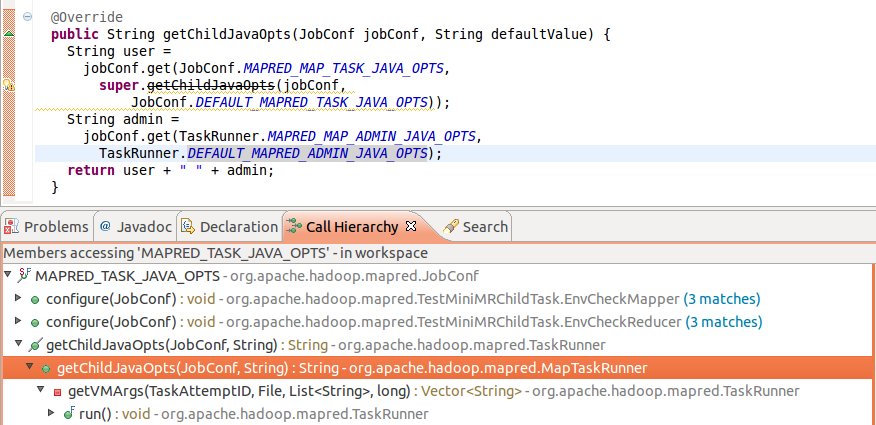
不外这种方法只是限定了task的jvm heap最大限制,假如用户hive query优化不足好照旧会抛出OOM,其实是把问题抛给了用户,
接下来还要和用户一起看下到底是哪些query会占用如此大memory,看看有没有进一步优化的空间
From:csdn博客 拉拉过者
