在前面的文章中已经是给大家进行讲解了什么是Hadoop,简单的来说有很多服务器存储了很多文件。想要从这些文件里面查找想要的内容,把任务描述清楚,它就把结果返回给你了,最简单的理解就是架构系统,其中有各式各样的组件。
再来看看hadoop生态圈的一个解释:
我们知道所谓的大数据本身是个很宽泛的概念,Hadoop生态圈(或者泛生态圈)实际上都是为了处理超过单机尺度的数据处理而诞生的。更加直白一点的理解就是:可以把它比作一个厨房所需要的各种工具。锅碗瓢盆,这些工具是各有各的一个用处,而互相之间又有重合。当然你可以用汤锅直接当碗吃饭喝汤,又或者你可以用小刀或者刨子去皮。你会发现每个工具有自己的特性,虽然组合在一起也是可以去工作,但未必是最佳的一个选择。
下图是一个hadoop生态圈的分布图:
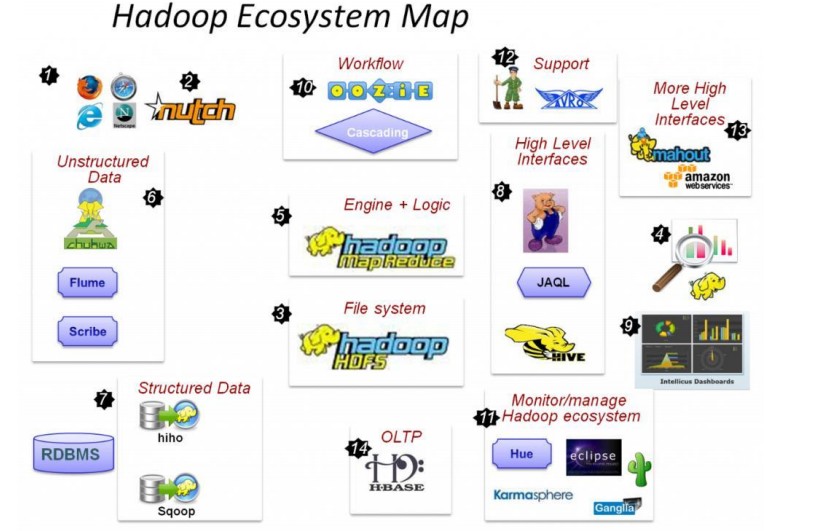
1.Nutch,互联网数据及Nutch搜索引擎应用
2.HDFS,Hadoop的分布式文件系统
3.MapReduce,是一个分布式计算框架
4.Flume、Scribe,Chukwa是属于数据的收集,收集非结构化数据的一些工具。
5.Hiho、Sqoop,讲关系数据库中的数据导入HDFS的工具
6.Hive表示的是数据仓库,pig分析数据的工具
7.Oozie一个基于工作流引擎的开源框架。
8.Hue,Hadoop自己的监控管理工具
9.Avro是一个数据序列化工具
10.mahout数据挖掘工具,用于数据的深入挖掘。
11.Hbase是一个高可靠性、高性能、面向列、可伸缩分布式的面向列的开源数据库
Hadoop生态系统的主要的特点是什么?
(1)支持开放的源代码
(2)社区是比较活跃、参与者比较多
(3)涉及分布式存储和计算的方方面面
(4)它是已经得到企业界的一个验证
以上是带大家对hadoop生态圈简单的一个理解,我们在学习生物的时候就已经了解过生态系统的多样性的特点,在接下里的教程文章中,我们将继续对Hadoop生态系统的各组成部分进行详解,甘兴趣的朋友们可以关注一下。
