欢迎大家阅读本篇文章,本篇文章讲述了Apache Hadoop最全生态系统,课课教育平台提醒您:本篇文章纯干货,但文章中有许多的小细节,因此大家一定要认真阅读本篇文章哦~
1. HDFS
HDFS(Hadoop Distributed File System,Hadoop分布式文件系统)是Hadoop体系中数据存储管理的基础。它是一个高度容错的系统,能检测和应对硬件故障,用于在低成本的通用硬件上运行。HDFS简化了文件的一致性模型,通过流式数据访问,提供高吞吐量应用程序数据访问功能,适合带有大型数据集的应用程序。
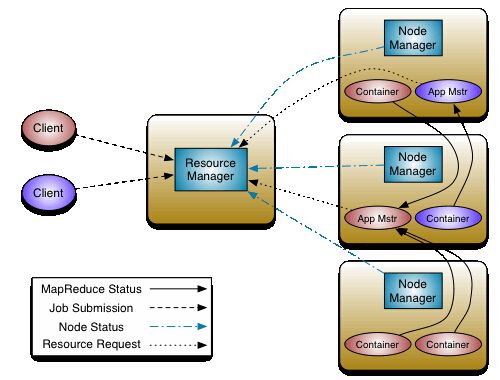
2. MapReduce
MapReduce是一种计算模型,用以进行大数据量的计算。Hadoop的MapReduce实现,和Common、HDFS一起,构成了Hadoop发展初期的三个组件。MapReduce将应用划分为Map和Reduce两个步骤,其中Map对数据集上的独立元素进行指定的操作,生成键-值对形式中间结果。Reduce则对中间结果中相同“键”的所有“值”进行规约,以得到最终结果。MapReduce这样的功能划分,非常适合在大量计算机组成的分布式并行环境里进行数据处理。
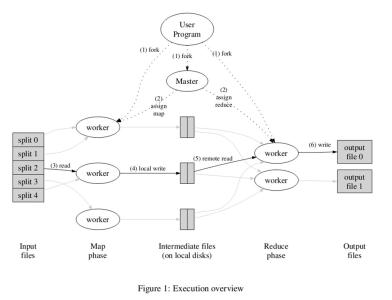
3. Hive
Hive是Hadoop中的一个重要子项目,最早由Facebook设计,是建立在Hadoop基础上的数据仓库架构,它为数据仓库的管理提供了许多功能,包括:数据ETL(抽取、转换和加载)工具、数据存储管理和大型数据集的查询和分析能力。Hive提供的是一种结构化数据的机制,定义了类似于传统关系数据库中的类SQL语言:Hive QL,通过该查询语言,数据分析人员可以很方便地运行数据分析业务。
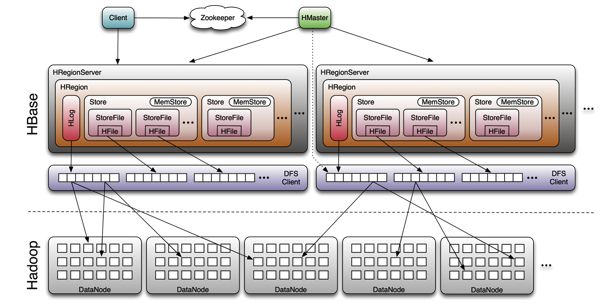
4. HBase
Google发表了BigTable系统论文后,开源社区就开始在HDFS上构建相应的实现HBase。HBase是一个针对结构化数据的可伸缩、高可靠、高性能、分布式和面向列的动态模式数据库。和传统关系数据库不同,HBase采用了BigTable的数据模型:增强的稀疏排序映射表(Key/Value),其中,键由行关键字、列关键字和时间戳构成。HBase提供了对大规模数据的随机、实时读写访问,同时,HBase中保存的数据可以使用MapReduce来处理,它将数据存储和并行计算完美地结合在一起。
5. Pig
Pig运行在Hadoop上,是对大型数据集进行分析和评估的平台。它简化了使用Hadoop进行数据分析的要求,提供了一个高层次的、面向领域的抽象语言:Pig Latin。通过Pig Latin,数据工程师可以将复杂且相互关联的数据分析任务编码为Pig操作上的数据流脚本,通过将该脚本转换为MapReduce任务链,在Hadoop上执行。和Hive一样,Pig降低了对大型数据集进行分析和评估的门槛。
6. Hadoop Common
从Hadoop 0.20版本开始,原来Hadoop项目的Core部分更名为Hadoop Common。Common为Hadoop的其他项目提供了一些常用工具,主要包括系统配置工具Configuration、远程过程调用RPC、序列化机制和Hadoop抽象文件系统FileSystem等。它们为在通用硬件上搭建云计算环境提供基本的服务,并为运行在该平台上的软件开发提供了所需的API。
7. ZooKeeper
在分布式系统中如何就某个值(决议)达成一致,是一个十分重要的基础问题。ZooKeeper作为一个分布式的服务框架,解决了分布式计算中的一致性问题。在此基础上,ZooKeeper可用于处理分布式应用中经常遇到的一些数据管理问题,如统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等。ZooKeeper常作为其他Hadoop相关项目的主要组件,发挥着越来越重要的作用。
原理
#p#分页标题#e#
ZooKeeper是以Fast Paxos算法为基础的,Paxos 算法存在活锁的问题,即当有多个proposer交错提交时,有可能互相排斥导致没有一个proposer能提交成功,而Fast Paxos作了一些优化,通过选举产生一个leader (领导者),只有leader才能提交proposer,具体算法可见Fast Paxos。因此,要想弄懂ZooKeeper首先得对Fast Paxos有所了解。
8. Avro
Avro由Doug Cutting牵头开发,是一个数据序列化系统。类似于其他序列化机制,Avro可以将数据结构或者对象转换成便于存储和传输的格式,其设计目标是用于支持数据密集型应用,适合大规模数据的存储与交换。Avro提供了丰富的数据结构类型、快速可压缩的二进制数据格式、存储持久性数据的文件集、远程调用RPC和简单动态语言集成等功能。
9. Mahout
Mahout起源于2008年,最初是Apache Lucent的子项目,它在极短的时间内取得了长足的发展,现在是Apache的顶级项目。Mahout的主要目标是创建一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序。Mahout现在已经包含了聚类、分类、推荐引擎(协同过滤)和频繁集挖掘等广泛使用的数据挖掘方法。除了算法,Mahout还包含数据的输入/输出工具、与其他存储系统(如数据库、MongoDB 或Cassandra)集成等数据挖掘支持架构。
主要特性
虽然在开源领域中相对较为年轻,但 Mahout 已经提供了大量功能,特别是在集群和 CF 方面。Mahout 的主要特性包括:
Taste CF。Taste 是 Sean Owen 在 SourceForge 上发起的一个针对 CF 的开源项目,并在 2008 年被赠予 Mahout。
一些支持 Map-Reduce 的集群实现包括 k-Means、模糊 k-Means、Canopy、Dirichlet 和 Mean-Shift。
Distributed Naive Bayes 和 Complementary Naive Bayes 分类实现。
针对进化编程的分布式适用性功能。
Matrix 和矢量库。
10. X-RIME
X-RIME是一个开源的社会网络分析工具,它提供了一套基于Hadoop的大规模社会网络/复杂网络分析工具包。X-RIME在MapReduce 的框架上对十几种社会网络分析算法进行了并行化与分布式化,从而实现了对互联网级大规模社会网络/复杂网络的分析。它包括HDFS存储系统上的一套适合大规模社会网络分析的数据模型、基于MapReduce实现的一系列社会网络分析分布式并行算法和X-RIME处理模型,即X-RIME工具链等三部分。
11. Crossbow
Crossbow是在Bowtie和SOAPsnp基础上,结合Hadoop的可扩展工具,该工具能够充分利用集群进行生物计算。其中,Bowtie是一个快速、高效的基因短序列拼接至模板基因组工具;SOAPsnp则是一个重测序一致性序列建造程序。它们在复杂遗传病和肿瘤易感的基因定位,到群体和进化遗传学研究中发挥着重要的作用。Crossbow利用了Hadoop Stream,将Bowtie、SOAPsnp上的计算任务分布到Hadoop集群中,满足了新一代基因测序技术带来的海量数据存储及计算分析要求。
12. Chukwa
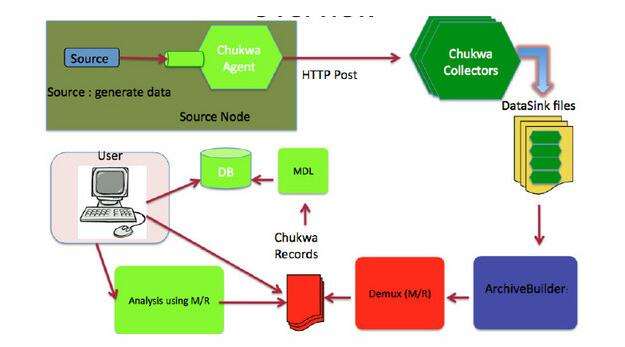
Chukwa是开源的数据收集系统,用于监控大规模分布式系统(2000+以上的节点, 系统每天产生的监控数据量在T级别)。它构建在Hadoop的HDFS和MapReduce基础之上,继承了Hadoop的可伸缩性和鲁棒性。Chukwa包含一个强大和灵活的工具集,提供了数据的生成、收集、排序、去重、分析和展示等一系列功能,是Hadoop使用者、集群运营人员和管理人员的必备工具。
概述
Apache 的开源项目 hadoop, 作为一个分布式存储和计算系统,已经被业界广泛应用。很多大型企业都有了各自基于 hadoop 的应用和相关扩展。当 1000+ 以上个节点的 hadoop 集群变得常见时,集群自身的相关信息如何收集和分析呢?针对这个问题, Apache 同样提出了相应的解决方案,那就是 chukwa。chukwa 的官方网站是这样描述自己的: chukwa 是一个开源的用于监控大型分布式系统的数据收集系统。这是构建在 hadoop 的 hdfs 和 map/reduce 框架之上的,继承了 hadoop 的可伸缩性和鲁棒性。Chukwa 还包含了一个强大和灵活的工具集,可用于展示、监控和分析已收集的数据。
在一些网站上,甚至声称 chukwa 是一个“日志处理/分析的full stack solution”。
13. Flume
#p#分页标题#e#
Flume是Cloudera开发维护的分布式、可靠、高可用的日志收集系统。它将数据从产生、传输、处理并最终写入目标的路径的过程抽象为数据流,在具体的数据流中,数据源支持在Flume中定制数据发送方,从而支持收集各种不同协议数据。同时,Flume数据流提供对日志数据进行简单处理的能力,如过滤、格式转换等。此外,Flume还具有能够将日志写往各种数据目标(可定制)的能力。总的来说,Flume是一个可扩展、适合复杂环境的海量日志收集系统。
14. Sqoop
Sqoop是SQL-to-Hadoop的缩写,是Hadoop的周边工具,它的主要作用是在结构化数据存储与Hadoop之间进行数据交换。Sqoop可以将一个关系型数据库(例如MySQL、Oracle、PostgreSQL等)中的数据导入Hadoop的HDFS、Hive中,也可以将HDFS、Hive中的数据导入关系型数据库中。Sqoop充分利用了Hadoop的优点,整个数据导入导出过程都是用MapReduce实现并行化,同时,该过程中的大部分步骤自动执行,非常方便。
特征
Sqoop是一个用来将Hadoop和关系型数据库中的数据相互转移的工具,可以将一个关系型数据库(例如 : MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。对于某些NoSQL数据库它也提供了连接器。Sqoop,类似于其他ETL工具,使用元数据模型来判断数据类型并在数据从数据源转移到Hadoop时确保类型安全的数据处理。Sqoop专为大数据批量传输设计,能够分割数据集并创建Hadoop任务来处理每个区块。
15. Oozie
在Hadoop中执行数据处理工作,有时候需要把多个作业连接到一起,才能达到最终目的。针对上述需求,Yahoo开发了开源工作流引擎Oozie,用于管理和协调多个运行在Hadoop平台上的作业。在Oozie中,计算作业被抽象为动作,控制流节点则用于构建动作间的依赖关系,它们一起组成一个有向无环的工作流,描述了一项完整的数据处理工作。Oozie工作流系统可以提高数据处理流程的柔性,改善Hadoop集群的效率,并降低开发和运营人员的工作量。
16. Karmasphere
Karmasphere包括Karmasphere Analyst和Karmasphere Studio。其中,Analyst提供了访问保存在Hadoop里面的结构化和非结构化数据的能力,用户可以运用SQL或其他语言,进行即时查询并做进一步的分析。Studio则是基于NetBeans的MapReduce集成开发环境,开发人员可以利用它方便快速地创建基于Hadoop的MapReduce应用。同时,该工具还提供了一些可视化工具,用于监控任务的执行,显示任务间的输入输出和交互等。需要注意的是,在上面提及的这些项目中,Karmasphere是唯一不开源的工具。
17.JaqlJaql 针对半结构化大数据量的查询语言应运而生,运用Jaql 语言,程序员并不需要关心 MapReduce 框架原理而只需要应用更容易理解和人性化的脚本语言。
小结:相信最后大家阅读完毕本篇文章后,学到了不少Apache Hadoop知识吧,其实大家私下还得多多自学,才能学习的更加深入,更加透彻,当然如果大家还想了解更多相关方面的详细内容的话呢,课课家教育平台欢迎大家哦~
