课课教育平台提出:现在的企业都提大数据,但是真正做好的不多。大数据包含两部分,第一是大数据的存储和管理,就是数据仓库。第二是把准备好的数据,进行分析,提炼数据中有商业价值的信息,第一阶段做数据仓库比较容易,第二个做好的太少,做好第二个要有很深的业务知识。没有业务知识,只是看数据分析挖掘里面的聚类、分类结果要 么只能得出表面现象,得不到真是的内在原因。或者得出很偏离现实的一些因素。今天要为大家讲解Hive数据存储的各种模式全面详解,大家要认真学了喽~
Hive定义:
Hive是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 HQL,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。

Hive 没有专门的数据格式。 Hive 可以很好的工作在 Thrift 之上,控制分隔符,也允许用户指定数据格式。
Hive的数据分为表数据和元数据,表数据是Hive中表格(table)具有的数据;而元数据是用来存储表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。下面分别来介绍。
一、Hive的数据存储:
在让你真正明白什么是hive 博文中我们提到Hive是基于Hadoop分布式文件系统的,它的数据存储在Hadoop分布式文件系统中。Hive本身是没有专门的数据存储格式,也没有为数据建立索引,只需要在创建表的时候告诉Hive数据中的列分隔符和行分隔符,Hive就可以解析数据。所以往Hive表里面导入数据只是简单的将数据移动到表所在的目录中(如果数据是在HDFS上;但如果数据是在本地文件系统中,那么是将数据复制到表所在的目录中)。
Hive中主要包含以下几种数据模型:Table(表),External Table(外部表),Partition(分区),Bucket(桶)(本博客会专门写几篇博文来介绍分区和桶)。
1、表:Hive中的表和关系型数据库中的表在概念上很类似,每个表在HDFS中都有相应的目录用来存储表的数据,这个目录可以通过${HIVE_HOME}/conf/hive-site.XML配置文件中的 hive.metastore.warehouse.dir属性来配置,这个属性默认的值是/user/hive/warehouse(这个目录在 HDFS上),我们可以根据实际的情况来修改这个配置。如果我有一个表wyp,那么在HDFS中会创建/user/hive/warehouse/wyp 目录(这里假定hive.metastore.warehouse.dir配置为/user/hive/warehouse);wyp表所有的数据都存放在这个目录中。这个例外是外部表。
2、外部表:Hive中的外部表和表很类似,但是其数据不是放在自己表所属的目录中,而是存放到别处,这样的好处是如果你要删除这个外部表,该外部表所指向的数据是不会被删除的,它只会删除外部表对应的元数据;而如果你要删除表,该表对应的所有数据包括元数据都会被删除。
3、分区:在Hive中,表的每一个分区对应表下的相应目录,所有分区的数据都是存储在对应的目录中。比如wyp 表有dt和city两个分区,则对应dt=20131218,city=BJ对应表的目录为/user/hive/warehouse /dt=20131218/city=BJ,所有属于这个分区的数据都存放在这个目录中。
4、桶:对指定的列计算其hash,根据hash值切分数据,目的是为了并行,每一个桶对应一个文件(注意和分区的区别)。比如将wyp表id列分散至16个桶中,首先对id列的值计算hash,对应hash值为0和16的数据存储的HDFS目录为:/user /hive/warehouse/wyp/part-00000;而hash值为2的数据存储的HDFS 目录为:/user/hive/warehouse/wyp/part-00002。
来看下Hive数据抽象结构图:
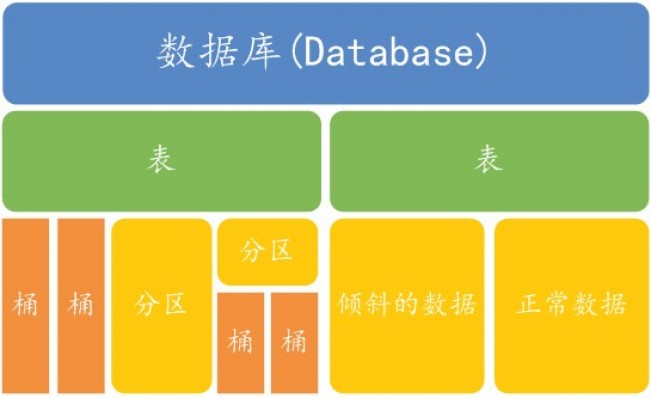
从上图可以看出,表是在数据库下面,而表里面又要分区、桶、倾斜的数据和正常的数据等;分区下面也是可以建立桶的。
二、Hive的元数据:
Hive中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。 由于Hive的元数据需要不断的更新、修改,而HDFS系统中的文件是多读少改的,这显然不能将Hive的元数据存储在HDFS中。目前Hive将元数据存储在数据库中,如MySQL、Derby中。我们可以通过以下的配置来修改Hive元数据的存储方式
#p#分页标题#e#
javax.jdo.option.ConnectionURL jdbc:mysql://localhost:3306/hive_hdp?characterEncoding=UTF-8 &createDatabaseIfNotExist=true JDBC connect string for a JDBC metastore javax.jdo.option.ConnectionDriverName com.mysql.jdbc.Driver Driver class name for a JDBC metastore javax.jdo.option.ConnectionUserName root username to use against metastore database javax.jdo.option.ConnectionPassword 123456 password to use against metastore database
当然,你还需要将相应数据库的启动复制到${HIVE_HOME}/lib目录中,这样才能将元数据存储在对应的数据库中。
小结:以上内容是一个大概Hive数据存储的各种模式解析,非常的容易明白与理解,学到了吧?如果大家还想了解更多相关方面的详细内容的话呢,欢迎关注课课家教育平台!
