本篇文章讲述了DIY Hadoop大数据环境的务必了解的5大圈套,其中有许多的小细节容易忽略,希望大认真阅读本篇文章哦~
虽然Hadoop可以运行在廉价的商品计算机硬件,且用户很容易添加节点,但是它有一些细节是很昂贵的,尤其是你在生产环境中运行Hadoop。

甲骨文公司大数据产品经理Jean-Pierre Dijck称:“IT部门认为‘我已经有服务器,我还可以买到便宜的服务器,我也有人员,所以我们不用花多少钱就可以构建自己的Hadoop集群’,这当然是一件好事,但是IT部门在部署时会发现这里会有很多他们没有预料到的额外开销。”
分享:
Hadoop这个名字不是一个缩写,它是一个虚构的名字。该项目的创建者,Doug Cutting如此解释Hadoop的得名:”这个名字是我孩子给一个棕黄色的大象样子的填充玩具命名的。我的命名标准就是简短,容易发音和拼写,没有太多的意义,并且不会被用于别处。小孩子是这方面的高手。”[Hadoop: The Definitive Guide]
Hadoop由 Apache Software Foundation 公司于 2005 年秋天作为Lucene的子项目Nutch的一部分正式引入。它受到最先由 Google Lab 开发的 Map/Reduce 和 Google File System(GFS) 的启发。2006 年 3 月份,Map/Reduce 和 Nutch Distributed File System (NDFS) 分别被纳入称为 Hadoop 的项目中。
Hadoop 是最受欢迎的在 Internet 上对搜索关键字进行内容分类的工具,但它也可以解决许多要求极大伸缩性的问题。例如,如果您要 grep 一个 10TB 的巨型文件,会出现什么情况?在传统的系统上,这将需要很长的时间。但是 Hadoop 在设计时就考虑到这些问题,采用并行执行机制,因此能大大提高效率。
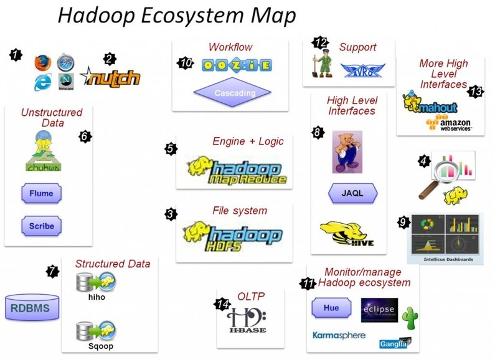
大数据结构如下:
大数据就是互联网发展到现今阶段的一种表象或特征而已,没有必要神话它或对它保持敬畏之心,在以云计算为代表的技术创新大幕的衬托下,这些原本很难收集和使用的数据开始容易被利用起来了,通过各行各业的不断创新,大数据会逐步为人类创造更多的价值。
其次,想要系统的认知大数据,必须要全面而细致的分解它,我着手从三个层面来展开:

第一层面是理论,理论是认知的必经途径,也是被广泛认同和传播的基线。在这里从大数据的特征定义理解行业对大数据的整体描绘和定性;从对大数据价值的探讨来深入解析大数据的珍贵所在;洞悉大数据的发展趋势;从大数据隐私这个特别而重要的视角审视人和数据之间的长久博弈。
第二层面是技术,技术是大数据价值体现的手段和前进的基石。在这里分别从云计算、分布式处理技术、存储技术和感知技术的发展来说明大数据从采集、处理、存储到形成结果的整个过程。
第三层面是实践,实践是大数据的最终价值体现。在这里分别从互联网的大数据,政府的大数据,企业的大数据和个人的大数据四个方面来描绘大数据已经展现的美好景象及即将实现的蓝图。
Dijcks列举了IT领导在DIY Hadoop集群时的5个常见错误:
1.他们试图以廉价的方式构建Hadoop:
很多IT部门不清楚Hadoop集群应该完成什么使命(除了分析某些类型的数据),所以他们会购买尽可能便宜的服务器。
“Hadoop被认为是可自愈的,所以当服务器的一个节点出现故障,构不成大问题,”Dijcks称,“但如果你购买廉价的服务器,很多节点出现故障那么你就要花更多时间来修复硬件,如果一大堆节点都不运行了,这就会造成大问题。”
如果你的Hadoop集群只是实验,那么以上这些可能不是问题。然而,很多实验性项目通常最后都会进入生产环境。IT部门认为,“我们已经投入了大量的时间,我们已经做了很多工作,现在我们需要将其投入生产,”Dijcks说道,“在实验期间,如果环境出现问题,只要重新启动即可,但在生产环境,集群需要能够抵御硬件故障、人为交互故障以及任何可能发生的事情。”
#p#分页标题#e#
Forrester公司在其2016年第二季度报告“大数据Hadoop优化系统”中指出,我们需要大量时间和精力用于安装、配置、调试、升级和监控通用Hadoop平台的基础设施,而预配置Hadoop优化系统可提供更快的时间价值、降低成本、最小化管理工作以及模块化扩展功能。
2.太多“厨师”(比喻):
大多数IT部门将自己分为软件、硬件和网络组,而Hadoop集群跨越了这些分组,所以DIY Hadoop集群最终会成为很多有说服力的“厨师”的产物。
Dijcks称:“在这种情况中,你有一个食谱来参考,但负责不同领域的人并不会完全遵循食谱,因为他们喜欢与食谱要求略有不同的做法。“所以最终,Hadoop集群不会按照预期那样运行。
在进行故障排除后,系统应该能够启动以及让IT运营人员在生产环境中运行,但Dijcks称:“这是另一个学习曲线开始的地方,他们可能不熟悉Hadoop集群,你会看到很多人为错误、停机时间等一系列问题。”
3.他们没有意识到Hadoop DIY项目是特洛伊木马:
在Hadoop集群转移到生产环境后,企业通常会发现他们需要安排专门的工作人员来保持其运行。Dijcks称:“当然,这个工作人员的大部分时间花费在维护上,而不是创新。”此外,这名工作人员还需要了解Hadoop系统。
他警告道:“你不能期望人们在很短时间内变成Hadoop专家。”即使你雇佣经验丰富的工作人员,但IT环境差异性很大–DIY Hadoop集群组件也是如此。因此,在你特定环境中的所有配置、连接和相互关系都需要花时间来了解。
4. 他们低估了更新的复杂性和频率:
新版Hadoop(例如来自Cloudera和Hortonworks)每三个月发布一次,这些通常包含新特性、新功能、更新、漏洞修复等。
“除了保持Hadoop集群运行所需的所有人类操作外,每三个月都会有新的升级版本,”Dijcks称,“你完成升级的那一刻,你必须开始规划下一次升级。这相当复杂,所以有些人开始跳过更新。”即使你跳过几次更新,最终你还是会需要更新,例如从5.4升级到5.7。
虽然Cloudera和Hortonworks会尝试测试尽可能多的场景,“他们不能测试你特定操作系统版本或者对特定工作操作的影响,”Dijcks称,“你的环境可能有思科路由器或者Red Hat操作系统或者IBM硬件,同时,如果这个集群正用于大数据生产项目,而你需要更新时,就有可能会制造出明显的停机时间。”
5. 他们没有准备好应对安全挑战:
在Hadoop早期,安全没有被视为一个大问题,因为集群仍位于防火墙后面。而现在,安全已经成为最大的问题。
目前Kerberos身份验证已经内置到Hadoop来解决这些问题,但有些IT企业不知道如何处理此协议,“整合Kerberos到企业的Active Directory非常复杂,”他表示,“你需要在Active Directory和一系列组件之间进行非常多集成工作。且这方面的文档非常少,最要命的是这涉及到安全管理员和IT其他团队,这些人员几乎是使用完全不同的语言。”
有些IT部门最终会与Cloudera、Hortonworks或其他第三方签署合同以保护他们的DIY Hadoop集群。“这需要一些时间才能完成设置、测试等工作,”Dijcks称,“然后每过三个月,你都需要重新做一次,以确保应用和配置等一切的正常运行。”
小结:相信大家阅读完毕本篇文章后,收获不小吧?当然如果大家想要了解更多相关的详细内容的话,请登录课课家教育平台资讯~
