Hadoop集群配置详细教程的讲解
在众多学习中,文章也许不起眼,但是重要的下面我们就来讲解一下!!
1. Hadoopcommon:为其他项目提供基础设施
2. HDFS 分布式的文件系 统
3. MapReduce : A software framework for distributed processing of large data sets on compute clusters 。一个 简化分布式编程的框架。
4. 其他工程包含: Avro( 序列化系 统 ) ,Cassandra( 数据 库项目 ) 等
Hadoop,以 Hadoop 分布式文件系统( HDFS ,Hadoop Distributed Filesystem )和 MapReduce ( Google MapReduce 的开源实现)为核心的 Hadoop 为用户提供了系统底层细节透明的分布式基础架构。
对于 Hadoop 的集群来讲,可以分成两大类角色: Master 和 Salve 。一个 HDFS 集群是由一个 NameNode 和若干个 DataNode 组成的。其中 NameNode 作为主服务器,管理文件系统的命名空间和客户端对文件系统的访问操作;集群中的DataNode 管理存储的数据。 MapReduce 框架是由一个 单独运行在主节点上的 JobTracker 和 运行在每个集群从节点的 TaskTracker 共同 组成的。主节点负责调度构成一个作业的所有任务,这些任务分布在不同的从节点上。主节点监控它们的执行情况,并且重新执行之前的失败任务;从节点仅负责由主节点指派的任务。当一个 Job 被提交时, JobTracker 接收到提交作 业和配置信息之后,就会将配置信息等分发给从节点,同时调度任务并监控 TaskTracker 的执行。
从上面的介绍可以看出, HDFS 和 MapReduce 共同 组成了Hadoop分布式系 统体系结构的核心。HDFS 在集群上 实现分布式文件系统, MapReduce 在集群上实现了分布式计算和任务处理。 HDFS 在 MapReduce 任 务处理过程中提供了文件操作和存储等支持, MapReduce在HDFS的基 础上实现了任务的分发、跟踪、执行等工作,并收集结果,二者相互作用,完成了 Hadoop 分布式集群的主要任 务。
为什么要使用2.0版本(来自董的博客)
该版本提供了一些新的、重要的功能,包括:
•HDFS HA ,当前只能 实现人工切换。
Hadoop HA 分支 merge 进了该版本,并支持热切,主要特性包括:
( 1 ) NN 配置文件有改变,使得配置更加简单
( 2 ) NameNode 分 为两种角色: active NN 与 standby NN , active NN 对外提供读写服务,一旦出现故障,便切换到 standby NN 。
( 3 ) 支持 Client 端重定向,也就是 说,当 active NN 切 换到 standby NN 过程中, Client 端所有的 进行时操作都可以无缝透明重定向到 standby NN 上, Client 自己感 觉不到切换过程。
( 4 ) DN 同 时向 active NN 和 standby NN 汇报 block 信息。
具体 设计文档参考:
当前 Hadoop HA 只能 实现人工切换,该功能在某些情况下非常有用,比如,对 NN 进行升级时,先将 NN 切 换到 standby NN ,并 对之前的 active NN 进行升级,升级完成后,再将 NN 切 换至升级后的 NN 上,然后 对 standby NN 进行升级。
•Yarn,下一代 MapReduce 这是一套资源统一管理和调度平台,可管理各种计算框架,包括 MapReduce 、 Spark、 MPI 等。
YARN 是一套 资源统一管理和调度平台,可管理各种计算框架,包括 MapReduce , Spark , MPI 等。尽管它是完全重写而成,但其思想是从 MapReduce 衍化而来的,并克服了它在 扩展性和容错性等方面的众多不足。具体参考:
http://hadoop.apache.org/common/docs/r0.23.0/hadoop-yarn/hadoop-yarn-site/YARN.html
•HDFS Federation ,允 许 HDFS 中存在多个 NameNode ,且每个 NameNode 分管一部分目 录,而 DataNode 不 变,进而缩小了故障带来的影响范围,并起到一定的隔离作用。
传统 HDFS 是 master/slave 结构,其中, master (也就是 NameNode )需要存 储所有文件系统的元数据信息,且所有文件存储操作均需要访问多次 NameNode ,因而 NameNode 成 为制约扩展性的主要瓶颈所在。为了解决该问题,引入了 HDFS Federation ,允 许 HDFS 中存在多个 NameNode ,且每个 NameNode 分管一部分目 录,而 DataNode 不 变,也就是 “ 从中央集权 **变为各个地方自治 ” , 进而缩小了故障带来的影响范围,并起到一定的隔离作用。具体参考:
http://dongxicheng.org/mapreduce-nextgen/nextgen-mapreduce-introduction/
•基准性能测试
该版本中为 HDFS 和 YARN 添加了性能的基准 测试集,其中 HDFS 测试包括:
( 1 ) dfsio 基准 测试 HDFS I/O 读写性能
( 2 ) slive 基准 测试 NameNode 内部操作的性能
( 3 ) scan 基准 测试 MapReduce 作 业访问 HDFS 的 I/O 性能
( 4 ) shuffle 基准 测试 shuffle 阶段性能
( 5 ) compression 基准 测试 MapReduce 作 业中间结果和最终结果的压缩性能
( 6 ) gridmix-V3 基准 测试集群吞吐率
YARN 测试包括 :
( 1 ) ApplicationMaster 扩展性基准测试
主要 测试调度 task/container 的性能。与 1.0 版本比 较,大约快 2 倍。
( 2 ) ApplicationMaster 恢复性基准 测试
测试 YARN 重 启后,作业恢复速度。稍微解释一下 ApplicationMaster 恢复作 业的功能:在作业执行过程中, Application Master 会不断地将作 业运行状态保存到磁盘上,比如哪些任务运行完成,哪些未完成等,这样,一旦集群重启或者 master 挂掉,重 启后,可复原各个作业的状态,并只需重新运行未运行完成的哪些任务。
( 3 ) ResourceManager 扩展性基准测试
通 过不断向 Hadoop 集群中添加 节点测试 RM 的 扩展性。
( 4 ) 小作 业基准测试
专门测试批量小作业的吞吐率Oracle培训
具体参考:
http://hortonworks.com/blog/delivering-on-hadoop-next-benchmarking-performance/
•通过 protobufs 来提供HDFS 和YARN 的兼容性
Wire-compatibility for both HDFS & YARN
Hadoop RPC采用了Hadoop自己的一套序列化框架 对 各种 对 象 进 行序列化反序列,但存在一个 问题 : 扩 展性差,很 难 添加新的数据类型同 时 保 证 版本兼容性。 为 此,Hadoop 2.0将数据类型模 块 从RPC中独立出来,成 为 一个独立的可插拔模 块 , 这样 允 许 用 户 根据个人 爱 好使用各种序列化/反序列化框架,比如thrift,arvo,protocal Buffer等,默 认 情况采用Protocal Buffer。
http://hortonworks.com/blog/rpc-improvements-and-wire-compatibility-in-apache-hadoop/
除了以上五个特性外, 还 有两个非常重要的特性正在研 发 中,分别是:
•HDFS快照
用 户 可在任意 时间对 HDFS做快照, 这样 ,在HDFS出 现 故障 时 ,可将数据恢复到某个 时间 点的状 态 。具体参考:
http://hortonworks.com/blog/snapshots-for-hdfs/
•HDFS HA自动 切换
前面介 绍 的第一个功能“HDFS HA”当前只能 实现 人工切 换 ,也就是 说 ,管理 员运 行某个命令,使得acitve NN切 换 到standby NN上。以后将支持自 动 切 换 ,也就是 说 , 监 控模 块 可 检测 出active NN何 时 出 现 故障,并自 动 将之切 换 到standby NN上, 这样 可大大 较 小Hadoop集群 运维 人 员 的工作量。具体参考:
http://s.apache.org/hdfs-autofailover
准备
机器准备
物理机器 总 共4台,想配置基于物理机的hadoop集群中包括 4 个 节点: 1 个 Master , 3 个 Salve , 节点之间局域网连接,可以相互 ping 通
Ip分布 为
192.168.1.201 hadoop1
192.168.1.202 hadoop2
192.168.1.203 hadoop3
192.168.1.204 hadoop4
操作系 统为 CentOS 5.6 64bit
Master机器主要配置NameNode和JobTracker的角色, 负责总 管分布式数据和分解任 务 的 执 行;3个Salve机器配置DataNode和TaskTracker的角色, 负责 分布式数据存 储 以及任 务 的 执 行。其 实应该还应该 有1个Master机器,用来作 为备 用,以防止Master服 务 器宕机, 还 有一个 备 用 马 上 启 用。后 续经验积 累一定 阶 段后 补 上一台 备 用Master机器。
创建账户
使用root登 陆 所有机器后,所有的机器都 创建 hadoop 用 户
useradd hadoop
passwd hadoop
此 时 在 /home/ 下就会生成一个 hadoop 目 录 ,目 录 路径 为 /home/hadoop
创建相关的目录
定 义 需要数据及目 录 的存放路径
定 义 代 码及工具 存放的路径
- mkdir -p /home/hadoop/source
- mkdir -p /home/hadoop/tools
#p#分页标题#e#
定 义 数据 节 点存放的路径到跟目 录 下的hadoop文件夹, 这 里是数据 节 点存放目 录 需要有足够的空 间 存放
- mkdir -p /hadoop/hdfs
- mkdir -p /hadoop/tmp
- mkdir -p /hadoop/log
设 置可写权限
- chmod -R 777 /hadoop
定 义 Java安装程序路径
- mkdir -p /usr/java
安装
安装JDK
在以上 连接 下 载 下的 jdk 的安装文件: jdk-6u32-linux-x64.bin
1 ,将下 载好的 jdk-6u32-linux-x64.bin 通 过 SSH 上 传到 /usr/java 下
scp -r ./jdk-6u32-linux-x64.bin root@hadoop1:/usr/java
2 , 进入 JDK 安装目 录 cd /usr/java 并且 执行 chmod +x jdk-6u32-linux-x64.bin
3 , 执行 ./jdk-6u32-linux-x64.bin
4 ,配置 环境变量,执行 cd /etc 命令后 执行 vi profile ,在行末尾添加
export JAVA_HOME=/usr/java/jdk1.6.0_32
export CLASSPATH=.:$JAVA_HOME/lib/tools.jar:/lib/dt.jar
export PATH=$JAVA_HOME/bin:$PATH
5 , 执行 chmod +x profile 将其 变成可执行文件oracle视频教程
6 , 执行 source profile 使其配置立即生效
source /etc/profile
7 , 执行 java -version 查看是否安装成功
这个步骤所有机器都必须安装
- [root@hadoop1 bin]# java -version
- java version “1.6.0_32”
- Java(TM) SE Runtime Environment (build 1.6.0_32-b05)
- Java HotSpot(TM) 64-Bit Server VM (build 20.7-b02, mixed mode)
#p#分页标题#e#
修改主机名
修改主机名,所有 节点均一样配置
1 , 连接到主节点 192.168.1.201 ,修改 network , 执行 vim /etc/sysconfig/network ,修改 HOSTNAME=hadoop1
2 ,修改 hosts 文件, 执行 cd /etc 命令后 执行 vi hosts ,在行末尾添加 :
192.168.1.201 hadoop1
192.168.1.202 hadoop2
192.168.1.203 hadoop3
192.168.1.204 hadoop4
3 , 执行 hostname hadoop1
4 , 执行 exit 后重新 连接可看到主机名以修改 OK
其他 节点 也修改主机名后添加 Host, 或者 host 文件可以在后面 执行 scp 覆盖操作
配置SSH无密码登陆
SSH 无密 码原理简介 :
首先在 hadoop1 上生成一个密 钥对,包括一个公钥和一个私钥,并将公钥复制到所有的 slave(hadoop2-hadoop4) 上。
然后当 master 通 过 SSH 连接 slave 时, slave 就会生成一个随机数并用 master 的公 钥对随机数进行加密,并发送给 master 。
最后 master 收到加密数之后再用私 钥解密,并将解密数回传给 slave , slave 确 认解密数无误之后就允许 master 不 输入密码进行连接了
2 ,具体步 骤(在root用户和hadoop用户登陆情况下执行)
1 、 执行命令 ssh-keygen -t rsa 之后一路回 车,查看刚生成的无密码钥对: cd .ssh 后 执行 ll
2 、把 id_rsa.pub 追加到授权的 key 里面去。 执行命令 cat ~/.ssh/id_rsa.pub >>~/.ssh/authorized_keys
3 、修改权限: 执行 chmod 600 ~/.ssh/authorized_keys
4 、确保 cat /etc/ssh/sshd_config 中存在如下内容
RSAAuthentication yes
PubkeyAuthentication yes
AuthorizedKeysFile .ssh/authorized_keys
如需修改, 则在修改后执行重启 SSH 服 务命令使其生效 :service sshd restart
5 、将公 钥复制到所有的 slave 机器上 :scp ~/.ssh/id_rsa.pub 192.168.1.203 : ~/ 然后 输入 yes ,最后 输入 slave 机器的密 码
6 、在 slave 机器上 创建 .ssh 文件夹 :mkdir ~/.ssh 然后 执行 chmod 700 ~/.ssh (若文件夹以存在 则不需要创建)
7 、追加到授权文件 authorized_keys 执行命令 :cat ~/id_rsa.pub >> ~/.ssh/authorized_keys 然后 执行 chmod 600 ~/.ssh/authorized_keys
8 、重复第 4 步
9 、 验证命令 : 在 master 机器上 执行 ssh 192.168.1.203 发现主机名由 hadoop1 变成 hadoop3 即成功,最后 删除 id_rsa.pub 文件 :rm -r id_rsa.pub
按照以上步 骤分别配置 hadoop1,hadoop2,hadoop3,hadoop4 ,要求每个都可以无密 码登录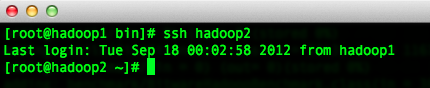
源码下载
HADOOP 版本
最新版本 hadoop-2.0.0-alpha 安装包 为 hadoop-2.0.0-alpha.tar.gz
下 载官网地址 :http://www.apache.org/dyn/closer.cgi/hadoop/common/
下 载到 /home/hadoop/source 目录下
wget http://ftp.riken.jp/net/apache/hadoop/common/hadoop-2.0.0-alpha/hadoop-2.0.0-alpha.tar.gz
解压目录
tar zxvf hadoop-2.0.0-alpha.tar.gz
创建软连接
cd /home/hadoop
ln -s /home/hadoop/source/hadoop-2.0.0-alpha/ ./hadoop
源码配置修改
/etc/profile
配置 环境变量: vim /etc/profile
添加
- export HADOOP_DEV_HOME=/home/hadoop/hadoop
- export PATH=$PATH:$HADOOP_DEV_HOME/bin
- export PATH=$PATH:$HADOOP_DEV_HOME/sbin
- export HADOOP_MAPARED_HOME=${HADOOP_DEV_HOME}
- export HADOOP_COMMON_HOME=${HADOOP_DEV_HOME}
- export HADOOP_HDFS_HOME=${HADOOP_DEV_HOME}
- export YARN_HOME=${HADOOP_DEV_HOME}
- export HADOOP_CONF_DIR=${HADOOP_DEV_HOME}/etc/hadoop
- export HDFS_CONF_DIR=${HADOOP_DEV_HOME}/etc/hadoop
- export YARN_CONF_DIR=${HADOOP_DEV_HOME}/etc/hadoop
创建并配置hadoop-env.sh
- vim /usr/hadoop/hadoop-2.0.0-alpha/etc/hadoop/hadoop-env.sh
- 在末尾添加 export JAVA_HOME=/usr/java/jdk1.6.0_27
- core-site.xml
#p#分页标题#e#
在 configuration 节点 里面添加属性
- hadoop.tmp.dir
- /hadoop/tmp
- A base for other temporary directories.
- fs.default.name
- hdfs://192.168.1.201:9000
添加 httpfs 的 选项
- hadoop.proxyuser.root.hosts
- 192.168.1.201
- hadoop.proxyuser.root.groups
- *
slave配置
vim /home/hadoop/hadoop/etc/hadoop/slaves
添加 slave 的 IP
192.168.1.202
192.168.1.203oracle教程
高尔夫球的数据分析
192.168.1.204
配置hdfs-site.xml
趋势一:数据的资源化
何为资源化,是指大数据成为企业和社会关注的重要战略资源,并已成为大家争相抢夺的新焦点。因而,企业必须要提前制定大数据营销战略计划,抢占市场先机。
趋势二:与云计算的深度结合
大数据离不开云处理,云处理为大数据提供了弹性可拓展的基础设备,是产生大数据的平台之一。自2013年开始,大数据技术已开始和云计算技术紧密结合,预计未来两者关系将更为密切。除此之外,物联网、移动互联网等新兴计算形态,也将一齐助力大数据革命,让大数据营销发挥出更大的影响力。
趋势三:科学理论的突破
随着大数据的快速发展,就像计算机和互联网一样,大数据很有可能是新一轮的技术革命。随之兴起的数据挖掘、机器学习和人工智能等相关技术,可能会改变数据世界里的很多算法和基础理论,实现科学技术上的突破。
趋势四:数据科学和数据联盟的成立
未来,数据科学将成为一门专门的学科,被越来越多的人所认知。各大高校将设立专门的数据科学类专业,也会催生一批与之相关的新的就业岗位。与此同时,基于数据这个基础平台,也将建立起跨领域的数据共享平台,之后,数据共享将扩展到企业层面,并且成为未来产业的核心一环。
趋势五:数据泄露泛滥
未来几年数据泄露事件的增长率也许会达到100%,除非数据在其源头就能够得到安全保障。可以说,在未来,每个财富500强企业都会面临数据攻击,无论他们是否已经做好安全防范。而所有企业,无论规模大小,都需要重新审视今天的安全定义。在财富500强企业中,超过50%将会设置首席信息安全官这一职位。企业需要从新的角度来确保自身以及客户数据,所有数据在创建之初便需要获得安全保障,而并非在数据保存的最后一个环节,仅仅加强后者的安全措施已被证明于事无补。
- vim /home/hadoop/hadoop/etc/hadoop/hdfs-site.xml
添加 节点
- dfs.replication
- 3
- dfs.namenode.name.dir
- file:/hadoop/hdfs/name
- true
- dfs.federation.nameservice.id
- ns1
- dfs.namenode.backup.address.ns1
- 192.168.1.201:50100
- dfs.namenode.backup.http-address.ns1
- 192.168.1.201:50105
- dfs.federation.nameservices
- ns1
- dfs.namenode.rpc-address.ns1
- 192.168.1.201:9000
- dfs.namenode.rpc-address.ns2
- 192.168.1.201:9000
- dfs.namenode.http-address.ns1
- 192.168.1.201:23001
- dfs.namenode.http-address.ns2
- 192.168.1.201:13001
- dfs.dataname.data.dir
- file:/hadoop/hdfs/data
- true
- dfs.namenode.secondary.http-address.ns1
- 192.168.1.201:23002
- dfs.namenode.secondary.http-address.ns2
- 192.168.1.201:23002
- dfs.namenode.secondary.http-address.ns1
- 192.168.1.201:23003
- dfs.namenode.secondary.http-address.ns2
- 192.168.1.201:23003
#p#分页标题#e#
配置yarn-site.xml
添加 节点
- yarn.resourcemanager.address
- 192.168.1.201:18040
- yarn.resourcemanager.scheduler.address
- 192.168.1.201:18030
- yarn.resourcemanager.Webappaddress
- 192.168.1.201:18088
- yarn.resourcemanager.resource-tracker.address
- 192.168.1.201:18025
- yarn.resourcemanager.admin.address
- 192.168.1.201:18141
- yarn.nodemanager.aux-services
- mapreduce.shuffle
配置httpfs-site.xml
同步代码到其他机器
1.同步配置代 码
先在 slaves 的机器上也 创 建
mkdir -p /home/hadoop/source
部署hadoop代 码 , 创 建 软连接 ,然后只要同步修改 过 的etc/hadoop下的配置文件即可
2.同步 /etc/profile
3.同步 /etc/hosts
scp -r /etc/profile root@hadoop2:/etc/profile
scp -r /etc/hosts root@hadoop2:/etc/hosts
其他机器以此操作
Hadoop启动
格式化集群
hadoop namenode -format -clusterid clustername
启动hdfs
执行
start-dfs.sh
开 启 hadoop dfs服 务
启动Yarn
开 启 yarn 资 源管理服 务
start-yarn.sh
启动httpfs
开 启 httpfs 服 务
httpfs.sh start
使得 对外 可以提高 http 的restful接口服 务
测试oracle数据库教程
安装结果验证
验证hdfs
在各台机器 执行 jps 看 进程 是否都已 经启动 了
- [root@hadoop1 hadoop]# jps
- 7396 NameNode
- 24834 Bootstrap
- 7594 SecondaryNameNode
- 7681 ResourceManager
- 32261 Jps
- [root@hadoop2 ~]# jps
- 8966 Jps
- 31822 DataNode
- 31935 NodeManager
进程启动 正常
验证 是否可以登 陆
- hadoop fs -ls hdfs://192.168.1.201:9000/
- hadoop fs -mkdir hdfs://192.168.1.201:9000/testfolder
- hadoop fs -copyFromLocal ./xxxx hdfs://192.168.1.201:9000/testfolder
- hadoop fs -ls hdfs://192.168.1.201:9000/ testfolder
看以上 执行 是否正常
验证map/reduce
在 master1 上, 创建输入目录 :hadoop fs -mkdir hdfs://192.168.1.201:9000/input
将 /usr/hadoop/hadoop-2.0.1-alpha/ 目 录下的所有 txt 文件复制到 hdfs 分布式文件系 统的目录里,执行以下命令
hadoop fs -put /usr/hadoop/hadoop-2.0.1-alpha/*.txt hdfs://192.168.1.201:9000/input
在 hadoop1 上, 执行 HADOOP 自 带的例子, Wordcount 包,命令如下
- cd /usr/hadoop/hadoop-2.0.1-alpha/share/hadoop/mapreduce
- hadoop jar hadoop-mapreduce-examples-2.0.1-alpha.jar wordcount hdfs://192.168.1.201:9000/input hdfs://192.168.1.201:9000/output
- hadoop fs -put /usr/hadoop/hadoop-2.0.1-alpha/*.txt hdfs://192.168.1.201:9000/input
在 hadoop1 上, 查看结果命令如下 :
- [root@master1 hadoop]# hadoop fs -ls hdfs://192.168.1.201:9000/output
- Found 2 items
- -rw-r–r– 2 root supergroup 0 2012-06-29 22:59 hdfs://192.168.1.201:9000/output/_SUCCESS
- -rw-r–r– 2 root supergroup 8739 2012-06-29 22:59 hdfs://192.168.1.201:9000/output/part-r-00000
- [root@hadoop1 hadoop]# hadoop fs -cat hdfs://192.168.1.201:9000/output/part-r-00000
即可看到每个 单词的数量
验证httpfs
HTTPFS操作:
OPEN,GETFILESTATUS,LISTSTATUS,GETHOMEDIRECTORY,GETCONTENTSUMMARY,GETFILECHECKSUM,GETDELEGATIONTOKEN,GETFILEBLOCKLOCATIONS,INSTRUMENTATION
GETHOMEDIRECTORY 路径无关,返回根 节点路径
- http://192.168.1.201:14000/webhdfs/v1/yxq?op=GETHOMEDIRECTORY&user.name=root
- Path: “/user/root”
- http://192.168.1.201:14000/webhdfs/v1/yxq/bitfoldersub0/bitwaretestfile0.bt?op=GETHOMEDIRECTORY&user.name=root
打开 / 下 载一个文件
http://192.168.1.201:14000/webhdfs/v1/yxq/bitfoldersub0/bitwaretestfile0.bt?op=open&user.name=root
LISTSTATUS 现实目录状态
- http://192.168.1.201:14000/webhdfs/v1/yxq/bitfoldersub0?op=LISTSTATUS&user.name=root
- http://192.168.1.201:14000/webhdfs/v1/yxq/bitfoldersub0/bitwaretestfile0.bt?op=LISTSTATUS&user.name=root
GETFILESTATUS 显示文件的状态
- http://192.168.1.201:14000/webhdfs/v1/yxq/bitfoldersub0/bitwaretestfile0.bt?op=GETFILESTATUS&user.name=root
#p#分页标题#e#
如果是路径 则现实路径信息
- http://192.168.1.201:14000/webhdfs/v1/yxq/bitfoldersub0/?op=GETFILESTATUS&user.name=root
- http://192.168.1.201:14000/webhdfs/v1/yxq/bitfoldersub0/bitwaretestfile0.bt?op=GETFILESTATUS&user.name=root
GETCONTENTSUMMARY 获取路径下的信息
- http://192.168.1.201:14000/webhdfs/v1/yxq?op=GETCONTENTSUMMARY&user.name=root
GETFILECHECKSUM 获取文件的校验值
以下 实现 方法 还 有 错误现 在:
- ———————————————————————————————————————————————————————————————————-
- GETDELEGATIONTOKEN ERROR
- http://192.168.1.201:14000/webhdfs/v1/yxq/bitfoldersub0/bitwaretestfile0.bt?op=GETDELEGATIONTOKEN&user.name=root
- GETFILEBLOCKLOCATIONS error
- http://192.168.1.201:14000/webhdfs/v1/yxq/bitfoldersub0/bitwaretestfile0.bt?op=GETFILEBLOCKLOCATIONS&user.name=root
- INSTRUMENTATION error
- http://192.168.1.201:14000/webhdfs/v1/yxq/bitfoldersub0/bitwaretestfile0.bt?op=INSTRUMENTATION&user.name=root

更多视频课程文章的课程,可到课课家官网查看。我在等你哟!!!
