在众多学习中,文章也许不起眼,但是重要的下面我们就来讲解一下!!
最近做了一个项目,要求找出二度人脉的一些关系,就好似新浪微博的“你可能感兴趣的人” 中,间接关注推荐;简单描述:即你关注的人中有N个人同时都关注了 XXX 。
在程序的实现上,其实我们要找的是:若 User1 follow了10个人 {User3,User4,User5,… ,User12}记为集合UF1,那么 UF1中的这些人,他们也有follow的集合,分别是记为: UF3(User3 follow的人),UF4,UF5,…,UF12;而在这些集合肯定会有交集,而由最多集合求交产生的交集,就是我们要找的:感兴趣的人。
我在网上找了些,关于二度人脉算法的实现,大部分无非是通过广度搜索算法来查找,犹豫深度已经明确了2以内;这个算法其实很简单,第一步找到你关注的人;第二步找到这些人关注的人,最后找出第二步结果中出现频率最高的一个或多个人,即完成。
但如果有千万级别的用户,那在运算时,就肯定会把这些用户的follow 关系放到内存中,计算的时候依次查找;先说明下我没有明确的诊断对比oracle数据库教程,这样做的效果一定没 基于Hadoop实现的好;只是自己,想用hadoop实现下,最近也在学;若有不足的地方还请指点。
首先,我的初始数据是文件,每一行为一个follow 关系 ida+‘\\\\t’+idb;表示 ida follow idb。其次,用了2个Map/Reduce任务。
Map/Reduce 1:找出 任意一个用户 的 follow 集合与 被 follow 的集合。如图所示: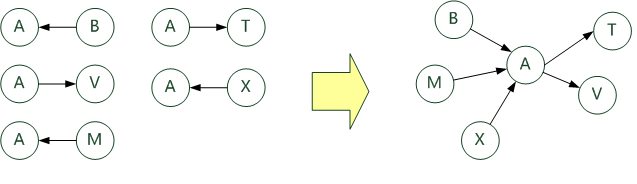
代码如下:
Map任务: 输出时 key :间接者 A 的ID ,value:follow 的人的ID 或 被follow的人的ID
- public void map(Text key, IntWritable values, Context context) throws IOException,InterruptedException{
- int value = values.get();
- //切分出两个用户id
- String[] _key = Separator.CONNECTORS_Pattern.split(key.toString());
- if(_key.length ==2){
- //”f”前缀表示 follow;”b” 前缀表示 被follow
- context.write(new Text(_key[0]), new Text(“f”+_key[1]));
- context.write(new Text(_key[1]), new Text(“b”+_key[0]));
- }
- }
Reduce任务: 输出时 key :间接者 A 的ID , value为 两个String,第一个而follow的所有人(用分割符分割),第二个为 被follow的人(同样分割)
- protected void reduce(Text key, Iterable pairs, Context context) Oracle培训
- throws IOException,InterruptedException{
- StringBuilder first_follow = new StringBuilder();
- StringBuilder second_befollow = new StringBuilder();
- for(TextPair pair: pairs){
- String id = pair.getFirst().toString();
- String value = pair.getSecond().toString();
- if(id.startsWith(“f”)){
- first_follow.append(id.substring(1)).append(Separator.TABLE_String);
- } else if(id.startsWith(“b”)){
- second_befollow.append(id.substring(1)).append(Separator.TABLE_String);
- }
- }
- context.write(key, new TextPair(first_follow.toString(),second_befollow.toString()));
- }
有人把数据比喻为蕴藏能量的煤矿。煤炭按照性质有焦煤、无烟煤、肥煤、贫煤等分类,而露天煤矿、深山煤矿的挖掘成本又不一样。与此类似,大数据并不在“大”,而在于“有用”。价值含量、挖掘成本比数量更为重要。对于很多行业而言,如何利用这些大规模数据是成为赢得竞争的关键。
大数据的价值体现在以下几个方面:1)对大量消费者提供产品或服务的企业可以利用大数据进行精准营销;2) 做小而美模式的中长尾企业可以利用大数据做服务转型;3) 面临互联网压力之下必须转型的传统企业需要与时俱进充分利用大数据的价值。
不过,“大数据”在经济发展中的巨大意义并不代表其能取代一切对于社会问题的理性思考,科学发展的逻辑不能被湮没在海量数据中。著名经济学家路德维希·冯·米塞斯曾提醒过:“就今日言,有很多人忙碌于资料之无益累积,以致对问题之说明与解决,丧失了其对特殊的经济意义的了解。”这确实是需要警惕的。
#p#分页标题#e#
其中Separator.TABLE_String为自定义的分隔符;TextPair为自定义的 Writable 类,让一个key可以对应两个value,且这两个value可区分。
Map/Reduce 2:在上一步关系中,若B follow A,而 A follow T ,则可以得出 T 为 B 的二度人脉,且 间接者为A ,于是找出 相同二度人脉的不同间接人。如图所示: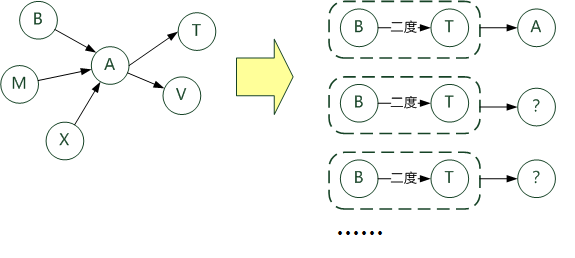
代码如下:
Map 任务:输出时 key 为 由两个String 记录的ID表示的 二度人脉关系,value 为 这个二度关系产生的间接人的IDoracle视频教程
- public void map(Text key, TextPair values, Context context) throws IOException,InterruptedException{
- Map<String, String> first_follow = new HashMap<String, String>();
- Map<String, String> second_befollow = new HashMap<String, String>();
- String _key = key.toString();
- String[] follow = values.getFirst().toString().split(Separator.TABLE_String);
- String[] second = values.getSecond().toString().split(Separator.TABLE_String);
- for(String sf : follow){
- first_follow.put(sf , _key );
- }
- for(String ss : second){
- second_befollow.put(ss , _key );
- }
- for(Entry<String, String> f : first_follow.entrySet()){
- for(Entry<String, String> b : second_befollow.entrySet()){
- context.write(new TextPair(f.getKey() ,b.getKey()), new Text(key));
- }
- }
- }
Reduce任务:输出时 key 仍然为二度人脉关系, value 为所有间接人 的ID以逗号分割。oracle教程
- protected void reduce(TextPair key, Iterable values, Context context)
- throws IOException, InterruptedException {
- StringBuilder resutl = new StringBuilder();
- for (Text text : values){
- resutl.append(text.toString()).append(“,”);
- }
- context.write(key, new Text(resutl.toString()));
- }
#p#分页标题#e#
到这步,二度人脉关系基本已经挖掘出来,后续的处理就很简单了,当然也基于二度人脉挖掘三度,四度:)
更多视频课程文章的课程,可到课课家官网查看。我在等你哟!!!
