采用Spark分析大数据
在众多学习中,文章也许不起眼,但是重要的下面我们就来讲解一下!!
Spark是一个基于内存计算的开源的集群计算系统(点此下载),目的是让数据分析更加快速。Spark非常小巧玲珑,由加州伯克利大学AMP实验室的Matei为主的小团队所开发。使用的语言是Scala,项目的core部分的代码只有63个Scala文件,非常短小精悍。与Hadoop不同的是,Spark和Scala紧密集成,Scala像管理本地collective对象那样管理分布式数据集。大数据概念oracle教程
Edwin认为:”MapReduce或hadoop任务都是批处理,所以启动一项Hadoop任务,或等待结果返回都需要等待很长时间,这一点很难改变,因为Hadoop天生就是一个批处理系统,你无法在上面运行互动分析。不过Hadoop对于分析海量数据还是很有用的。”
Spark开发之初是为了两个能被内存计算提速的应用:互动算法(常见于机器学习中,例如Google的PR)和互动数据挖掘(Hiveon Spark)。在这两个应用中,Spark的速度是Hadoop MapReduce的30倍!这是因为运行Spark系统时,服务器可以把中间数据存储在RAM内存中,而无需经常从头加载。这意味着分析结果的返回速度大大加快,足以胜任互动分析工作。(见下图)
下面我们将继续学习有深度的。
Oracle培训
趋势一:数据的资源化
何为资源化,是指大数据成为企业和社会关注的重要战略资源,并已成为大家争相抢夺的新焦点。因而,企业必须要提前制定大数据营销战略计划,抢占市场先机。
趋势二:与云计算的深度结合
大数据离不开云处理,云处理为大数据提供了弹性可拓展的基础设备,是产生大数据的平台之一。自2013年开始,大数据技术已开始和云计算技术紧密结合,预计未来两者关系将更为密切。除此之外,物联网、移动互联网等新兴计算形态,也将一齐助力大数据革命,让大数据营销发挥出更大的影响力。
趋势三:科学理论的突破oracle视频教程
随着大数据的快速发展,就像计算机和互联网一样,大数据很有可能是新一轮的技术革命。随之兴起的数据挖掘、机器学习和人工智能等相关技术,可能会改变数据世界里的很多算法和基础理论,实现科学技术上的突破。
趋势四:数据科学和数据联盟的成立
未来,数据科学将成为一门专门的学科,被越来越多的人所认知。各大高校将设立专门的数据科学类专业,也会催生一批与之相关的新的就业岗位。与此同时,基于数据这个基础平台,也将建立起跨领域的数据共享平台,之后,数据共享将扩展到企业层面,并且成为未来产业的核心一环。
趋势五:数据泄露泛滥
未来几年数据泄露事件的增长率也许会达到100%,除非数据在其源头就能够得到安全保障。可以说,在未来,每个财富500强企业都会面临数据攻击,无论他们是否已经做好安全防范。而所有企业,无论规模大小,都需要重新审视今天的安全定义。在财富500强企业中,超过50%将会设置首席信息安全官这一职位。企业需要从新的角度来确保自身以及客户数据,所有数据在创建之初便需要获得安全保障,而并非在数据保存的最后一个环节,仅仅加强后者的安全措施已被证明于事无补。
趋势六:数据管理成为核心竞争力
数据管理成为核心竞争力,直接影响财务表现。当“数据资产是企业核心资产”的概念深入人心之后,企业对于数据管理便有了更清晰的界定,将数据管理作为企业核心竞争力,持续发展,战略性规划与运用数据资产,成为企业数据管理的核心。数据资产管理效率与主营业务收入增长率、销售收入增长率显著正相关;此外,对于具有互联网思维的企业而言,数据资产竞争力所占比重为36.8%,数据资产的管理效果将直接影响企业的财务表现。
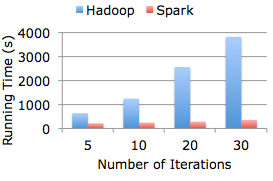 大数据分析oracle数据库教程
大数据分析oracle数据库教程
在Spark的出生地——加州伯克利大学的AMP实验室,研究人员用Spark分析垃圾邮件过滤、自然语言处理以及交通路况预测等任务。Spark还被用来给Conviva、Klout和Quantifind等公司的数据分析服务提速。无疑,Spark处理分布式数据集的框架不仅是有效的,而且是高效的(通过简洁的Scala脚本)。Spark和Scala目前都还尚处于开发中。尽管如此,随着加入更多的关键互联**性,它越来越从有趣的开源软件过渡为基础的web技术。
更多视频课程文章的课程,可到课课家官网查看。我在等你哟!!!
