查看HBase表在HDFS中的文件结构
在众多学习中,文章也许不起眼,但是重要的下面我们就来讲解一下!!
在Hbase中建立一张表结构如下:
- {NAME => 'USER_TEST_TABLE',
- MEMSTORE_FLUSHSIZE => '67108864',
- MAX_FILESIZE => '1073741824',
- FAMILIES => [
- {NAME => 'info', BLOOMFILTER => 'NONE', REPLICATION_SCOPE => '0',
- COMPRESSION => 'NONE', VERSIONS => '1', TTL => '2147483647',
- BLOCKSIZE => '65536', IN_MEMORY => 'false', BLOCKCACHE => 'true'
- },
- {NAME => 'info2', BLOOMFILTER => 'NONE', REPLICATION_SCOPE => '0',
- COMPRESSION => 'NONE', VERSIONS => '1', TTL => '2147483647',
- BLOCKSIZE => '65536', IN_MEMORY => 'false', BLOCKCACHE => 'true'
- } oracle教程
- ]
- }
结构图如下, 往下表插入测试数据, 下面查看此表在HDFS中文件的存储方式.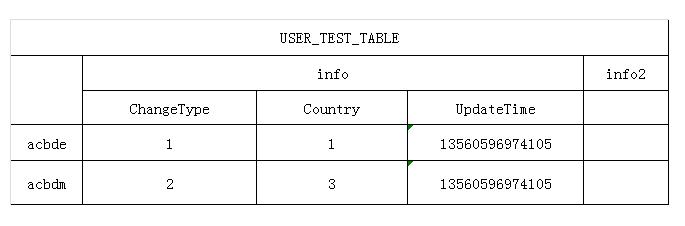
由于在HBase服务器配置文件中指定的存储HBase文件的HDFS地址为:
hdfs://HadoopCLUS01:端口/hbase
登录到namenode服务器,这里为HADOOPCLUS01, 用hadoop命令查看hbase在hdfs中此表的文件.
1. 查看Hbase根目录.
oracle视频教程
- [[email protected] bin]$ hadoop fs -ls hadoop fs -ls /hbase
- Found 37 items
- drwxr-xr-x – hadoop cug-admin 0 2013-03-27 09:29 /hbase/-ROOT-
- drwxr-xr-x – hadoop cug-admin 0 2013-03-27 09:29 /hbase/.META.
- drwxr-xr-x – hadoop cug-admin 0 2013-03-26 13:15 /hbase/.corrupt
- drwxr-xr-x – hadoop cug-admin 0 2013-03-27 09:48 /hbase/.logs
- drwxr-xr-x – hadoop cug-admin 0 2013-03-30 17:49 /hbase/.oldlogs
- drwxr-xr-x – hadoop cug-admin 0 2013-03-30 17:49 /hbase/splitlog
- drwxr-xr-x – hadoop cug-admin 0 2013-03-30 17:49 /hbase/USER_TEST_TABLE
可以看到所有表的信息. 在hdfs中的建立的目录. 一个表对应一个目录.
-ROOT-表和.META.表也不例外, -ROOT-表和.META.表都有同样的表结构, 关于两表的表结构和怎么对应HBase整个环境的表的HRegion, 可以查看上篇转载的文章.
splitlog和.corrupt目录分别是log split进程用来存储中间split文件的和损坏的日志文件的。
.logs和.oldlogs目录为HLog的存储.
.oldlogs为已经失效的HLog(Hlog对HBase数据库写Put已经全部完毕), 后面进行删除.
HLog File 是一个Sequence File,HLog File 由一条条的 HLog.Entry构成。可以说Entry是HLog的基本组成部分,也是Read 和Write的基本单位。
Entry由两个部分组成:HLogKey和WALEdit。
2. 查看建立表hdfs目录内容:
- [[email protected] bin]$ hadoop fs -ls /hbase/USER_TEST_TABLE
- Found 2 items
- drwxr-xr-x – hadoop cug-admin 0 2013-03-28 10:18 /hbase/USER_TEST_TABLE/03d99a89a256f0e09d0222709b1d0cbe
- drwxr-xr-x – hadoop cug-admin 0 2013-03-28 10:18 /hbase/USER_TEST_TABLE/68b8ad74920040ba9f39141e908c67ce
有两个目录, 说明此表已经**成两个HRegion.
3. 在查看其中一个HRegion的文件目录.
- [[email protected] bin]$ hadoop fs -ls /hbase/USER_TEST_TABLE/68b8ad74920040ba9f39141e908c67ce
- Found 4 items
- -rw-r–r– 3 hadoop cug-admin 1454 2013-03-28 10:18 /hbase/USER_TEST_TABLE/68b8ad74920040ba9f39141e908c67ce/.regioninfo
- drwxr-xr-x – hadoop cug-admin 0 2013-03-29 15:21 /hbase/USER_TEST_TABLE/68b8ad74920040ba9f39141e908c67ce/.tmp
- drwxr-xr-x – hadoop cug-admin 0 2013-03-29 15:21 /hbase/USER_TEST_TABLE/68b8ad74920040ba9f39141e908c67ce/info
- drwxr-xr-x – hadoop cug-admin 0 2013-03-28 10:18 /hbase/USER_TEST_TABLE/68b8ad74920040ba9f39141e908c67ce/info2
#p#分页标题#e#
.regioninfo 此HRegion的信息. StartRowKey, EndRowKey. 记录Region在表中的范围信息.
info, info2, 两个ColumnFamily. 为两个目录.
4. 再对.regioninfo文件用cat查看内容:
乱码已经过滤, 存储的信息整理:
经李克强总理签批,2015年9月,国务院印发《促进大数据发展行动纲要》(以下简称《纲要》),系统部署大数据发展工作。
《纲要》明确,推动大数据发展和应用,在未来5至10年打造精准治理、多方协作的社会治理新模式,建立运行平稳、安全高效的经济运行新机制,构建以人为本、惠及全民的民生服务新体系,开启大众创业、万众创新的创新驱动新格局,培育高端智能、新兴繁荣的产业发展新生态。
《纲要》部署三方面主要任务。一要加快政府数据开放共享,推动资源整合,提升治理能力。大力推动政府部门数据共享,稳步推动公共数据资源开放,统筹规划大数据基础设施建设,支持宏观调控科学化,推动政府治理精准化,推进商事服务便捷化,促进安全保障高效化,加快民生服务普惠化。二要推动产业创新发展,培育新兴业态,助力经济转型。发展大数据在工业、新兴产业、农业农村等行业领域应用,推动大数据发展与科研创新有机结合,推进基础研究和核心技术攻关,形成大数据产品体系,完善大数据产业链。三要强化安全保障,提高管理水平,促进健康发展。健全大数据安全保障体系,强化安全支撑。[11]
2015年9月18日贵州省启动我国首个大数据综合试验区的建设工作,力争通过3至5年的努力,将贵州大数据综合试验区建设成为全国数据汇聚应用新高地、综合治理示范区、产业发展聚集区、创业创新首选地、政策创新先行区。
围绕这一目标,贵州省将重点构建“三大体系”,重点打造“七大平台”,实施“十大工程”。
“三大体系”是指构建先行先试的政策法规体系、跨界融合的产业生态体系、防控一体的安全保障体系;“七大平台”则是指打造大数据示范平台、大数据集聚平台、大数据应用平台、大数据交易平台、大数据金融服务平台、大数据交流合作平台和大数据创业创新平台;“十大工程”即实施数据资源汇聚工程、政府数据共享开放工程、综合治理示范提升工程、大数据便民惠民工程、大数据三大业态培育工程、传统产业改造升级工程、信息基础设施提升工程、人才培养引进工程、大数据安全保障工程和大数据区域试点统筹发展工程。
此外,贵州省将计划通过综合试验区建设,探索大数据应用的创新模式,培育大数据交易新的做法,开展数据交易的市场试点,鼓励产业链上下游之间的数据交换,规范数据资源的交易行为,促进形成新的业态。
国家发展改革委有关专家表示,大数据综合试验区建设不是简单的建产业园、建数据中心、建云平台等,而是要充分依托已有的设施资源,把现有的利用好,把新建的规划好,避免造成空间资源的浪费和损失。探索大数据应用新的模式,围绕有数据、用数据、管数据,开展先行先试,更好地服务国家大数据发展战略。
- [[email protected] bin]$ hadoop fs -cat /hbase/USER_TEST_TABLE/68b8ad74920040ba9f39141e908c67ce/.regioninfo
- USER_TEST_TABLE,AAA-AAA11110UC1,1364437081331.68b8ad74920040ba9f39141e908c67ce.
- AA-AAA11110UC1
- USER_TEST_TABLE
- IS_ROOT false
- IS_META false oracle视频
- MAX_FILESIZE 1073741824
- MEMSTORE_FLUSHSIZ 6710886
- info
- BLOOMFILTER NONE
- REPLICATION_SCOPEVERSIONS 1
- COMPRESSION NONE
- TTL 2147483647
- BLOCKSIZE 65536
- IN_MEMORY false
- BLOCKCACHE true
- info2
- BLOOMFILTER NONE
- REPLICATION_SCOPEVERSIONS 1
- COMPRESSION NONE
- TTL 2147483647
- BLOCKSIZE 65536
- IN_MEMORY false
- BLOCKCACHE true
- REGION => {NAME => 'USER_TEST_TABLE,\\\\x00\\\\x00\\\\x00\\\\x0A\\\\x00\\\\x00\\\\x00\\\\x09AAA-AAA11110UC1\\\\x00\\\\x00\\\\x00\\\\x00,
- 1364437081331.68b8ad74920040ba9f39141e908c67ce.',
- STARTKEY => '\\\\x00\\\\x00\\\\x00\\\\x0A\\\\x00\\\\x00\\\\x00\\\\x09AAA-AAA11110UC1\\\\x00\\\\x00\\\\x00\\\\x00',
- ENDKEY => '',
- ENCODED => 68b8ad74920040ba9f39141e908c67ce,
- TABLE => {{NAME => 'USER_TEST_TABLE', MAX_FILESIZE => '1073741824',
- MEMSTORE_FLUSHSIZE => '67108864',
- FAMILIES => [{NAME => 'info', BLOOMFILTER => 'NONE',
- REPLICATION_SCOPE => '0', VERSIONS => '1', COMPRESSION => 'NONE',
- TTL => '2147483647', BLOCKSIZE => '65536', IN_MEMORY => 'false',
- BLOCKCACHE => 'true'},
- {NAME => 'info2', BLOOMFILTER => 'NONE',
- REPLICATION_SCOPE => '0', VERSIONS => '1', COMPRESSION => 'NONE',
- TTL => '2147483647', BLOCKSIZE => '65536', IN_MEMORY => 'false',
- BLOCKCACHE => 'true'}]}}
- VT102VT102VT102VT102VT102VT102VT102VT102
#p#分页标题#e#
5. 查看info ColumnFamily中信息文件和目录:oracle数据库教程
- [[email protected] bin]$ hadoop fs -ls /hbase/USER_TEST_TABLE/68b8ad74920040ba9f39141e908c67ce/info
- Found 4 items
- -rw-r–r– 3 hadoop cug-admin 547290902 2013-03-28 10:18 /hbase/USER_TEST_TABLE/68b8ad74920040ba9f39141e908c67ce/info/4024386696476133625
- -rw-r–r– 3 hadoop cug-admin 115507832 2013-03-29 15:20 /hbase/USER_TEST_TABLE/68b8ad74920040ba9f39141e908c67ce/info/5184431447574744531
- -rw-r–r– 3 hadoop cug-admin 220368457 2013-03-29 15:13 /hbase/USER_TEST_TABLE/68b8ad74920040ba9f39141e908c67ce/info/6150330155463854827
- -rw-r–r– 3 hadoop cug-admin 24207459 2013-03-29 15:21 /hbase/USER_TEST_TABLE/68b8ad74920040ba9f39141e908c67ce/info/7480382738108050697
6. 查看具体保存HBase数据的HDFS文件信息:
- [[email protected] bin]$ hadoop fs -ls /hbase/USER_TEST_TABLE/68b8ad74920040ba9f39141e908c67ce/info
- Found 4 items
- -rw-r–r– 3 hadoop cug-admin 547290902 2013-03-28 10:18 /hbase/USER_TEST_TABLE/68b8ad74920040ba9f39141e908c67ce/info/4024386696476133625
- -rw-r–r– 3 hadoop cug-admin 115507832 2013-03-29 15:20 /hbase/USER_TEST_TABLE/68b8ad74920040ba9f39141e908c67ce/info/5184431447574744531
- -rw-r–r– 3 hadoop cug-admin 220368457 2013-03-29 15:13 /hbase/USER_TEST_TABLE/68b8ad74920040ba9f39141e908c67ce/info/6150330155463854827
- -rw-r–r– 3 hadoop cug-admin 24207459 2013-03-29 15:21 /hbase/USER_TEST_TABLE/68b8ad74920040ba9f39141e908c67ce/info/7480382738108050697
即是上面图片中插入的其中一部分数据.
在HBase中存储时, 对于每个Qualifer有如下5个属性RowKey, ColumnFamily, Qualifer, TimeStamp, Value.
- AA-AAA11110UDFinfoCountry=1 13560596974000
# AA-AAA11110UDH 部分对应RowKey;
# info对应了ColumnFamily;
# Country对应Qualifer;
# 1对用Value;
# 13560596974000对应TimeStamp.
后面将分析RowKey与AA-AAA11110UDH的对应关系.
7. 使用HTTP查看文件:
在上面命令中, 也可以有Http查看Hdfs中的文件, 配置在hdfs-site.xml下面配置:
- dfs.datanode.http.address
- 0.0.0.0:620
- 更多视频课程文章的课程,可到课课家官网查看。我在等你哟!!!
