HDFS中的Namenode和Datanode的理解
恍惚恍惚又来到了文章的学习,想必大家又有很多问题吧!
HDFS Architecture:
Namoracle视频enode
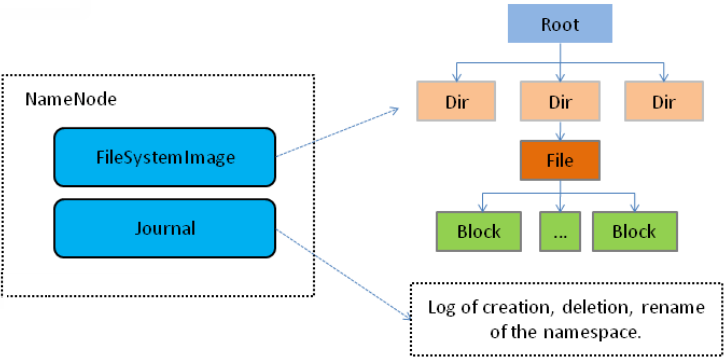
Namenode 管理者文件系统的Namespace。它维护着文件系统树(filesystem tree)以及文件树中所有的文件和文件夹的元数据(metadata)。管理这些信息的文件有两个,分别是Namespace 镜像文件(Namespace image)和操作日志文件(edit log),这些信息被Cache在RAM中,当然,这两个文件也会被持久化存储在本地硬盘。Namenode记录着每个文件中各个块所在的数据节点的位置信息,但是他并不持久化存储这些信息,因为这些信息会在系统启动时从数据节点重建。
Namenode结构图课抽象为如图:
经李克强总理签批,2015年9月,国务院印发《促进大数据发展行动纲要》(以下简称《纲要》),系统部署大数据发展工作。
《纲要》明确,推动大数据发展和应用,在未来5至10年打造精准治理、多方协作的社会治理新模式,建立运行平稳、安全高效的经济运行新机制,构建以人为本、惠及全民的民生服务新体系,开启大众创业、万众创新的创新驱动新格局,培育高端智能、新兴繁荣的产业发展新生态。
《纲要》部署三方面主要任务。一要加快政府数据开放共享,推动资源整合,提升治理能力。大力推动政府部门数据共享,稳步推动公共数据资源开放,统筹规划大数据基础设施建设,支持宏观调控科学化,推动政府治理精准化,推进商事服务便捷化,促进安全保障高效化,加快民生服务普惠化。二要推动产业创新发展,培育新兴业态,助力经济转型。发展大数据在工业、新兴产业、农业农村等行业领域应用,推动大数据发展与科研创新有机结合,推进基础研究和核心技术攻关,形成大数据产品体系,完善大数据产业链。三要强化安全保障,提高管理水平,促进健康发展。健全大数据安全保障体系,强化安全支撑。[11]
2015年9月18日贵州省启动我国首个大数据综合试验区的建设工作,力争通过3至5年的努力,将贵州大数据综合试验区建设成为全国数据汇聚应用新高地、综合治理示范区、产业发展聚集区、创业创新首选地、政策创新先行区。
围绕这一目标,贵州省将重点构建“三大体系”,重点打造“七大平台”,实施“十大工程”。oracle视频教程
“三大体系”是指构建先行先试的政策法规体系、跨界融合的产业生态体系、防控一体的安全保障体系;“七大平台”则是指打造大数据示范平台、大数据集聚平台、大数据应用平台、大数据交易平台、大数据金融服务平台、大数据交流合作平台和大数据创业创新平台;“十大工程”即实施数据资源汇聚工程、政府数据共享开放工程、综合治理示范提升工程、大数据便民惠民工程、大数据三大业态培育工程、传统产业改造升级工程、信息基础设施提升工程、人才培养引进工程、大数据安全保障工程和大数据区域试点统筹发展工程。
此外,贵州省将计划通过综合试验区建设,探索大数据应用的创新模式,培育大数据交易新的做法,开展数据交易的市场试点,鼓励产业链上下游之间的数据交换,规范数据资源的交易行为,促进形成新的业态。
国家发展改革委有关专家表示,大数据综合试验区建设不是简单的建产业园、建数据中心、建云平台等,而是要充分依托已有的设施资源,把现有的利用好,把新建的规划好,避免造成空间资源的浪费和损失。探索大数据应用新的模式,围绕有数据、用数据、管数据,开展先行先试,更好地服务国家大数据发展战略。
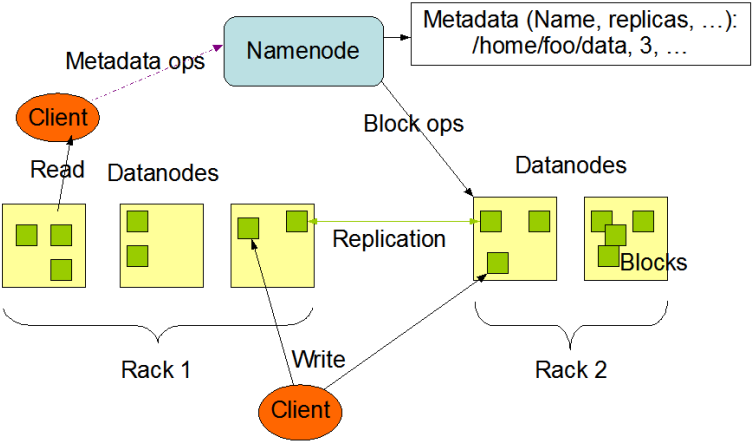
客户端(client)代表用户与namenode和datanode交互来访问整个文件系统。客户端提供了一些列的文件系统接口,因此我们在编程时,几乎无须知道datanode和namenode,即可完成我们所需要的功能。
Datanode
Datanode是文件系统的工作节点,他们根据客户端或者是namenode的调度存储和检索数据,并且定期向namenode发送他们所存储的块(block)的列表。
Namenode容错机制oracle数据库教程
没有Namenode,HDFS就不能工作。事实上,如果运行namenode的机器坏掉的话,系统中的文件将会完全丢失,因为没有其他方法能够将位于不同datanode上的文件块(blocks)重建文件。因此,namenode的容错机制非常重要,Hadoop提供了两种机制。
第一种方式是将持久化存储在本地硬盘的文件系统元数据备份。Hadoop可以通过配置来让Namenode将他的持久化状态文件写到不同的文件系统中。这种写操作是同步并且是原子化的。比较常见的配置是在将持久化状态写到本地硬盘的同时,也写入到一个远程挂载的网络文件系统。
第二种方式是运行一个辅助的Namenode(Secondary Namenode)。 事实上Secondary Namenode并不能被用作Namenode它的主要作用是定期的将Namespace镜像与操作日志文件(edit log)合并,以防止操作日志文件(edit log)变得过大。通常,Secondary Namenode 运行在一个单独的物理机上,因为合并操作需要占用大量的CPU时间以及和Namenode相当的内存。辅助Namenode保存着合并后的Namespace镜像的一个备份,万一哪天Namenode宕机了,这个备份就可以用上了。oracle教程
但是辅助Namenode总是落后于主Namenode,所以在Namenode宕机时,数据丢失是不可避免的。在这种情况下,一般的,要结合第一种方式中提到的远程挂载的网络文件系统(NFS)中的Namenode的元数据文件来使用,把NFS中的Namenode元数据文件,拷贝到辅助Namenode,并把辅助Namenode作为主Namenode来运行。
更多视频课程文章的课程,可到课课家官网查看。我在等你哟!!!
