恍惚恍惚又来到了文章的学习,想必大家又有很多问题吧!
一、读写机制
首先来看文件读取机制:尽管DataNode实现了文件存储空间的水平扩展和多副本机制,但是针对单个具体文件的读取,Hadoop默认的API接口并没有提供多DataNode的并行读取机制。oracle视频基于Hadoop提供的API接口实现的云盘客户端也自然面临同样的问题。Hadoop的文件读取流程如下图所示: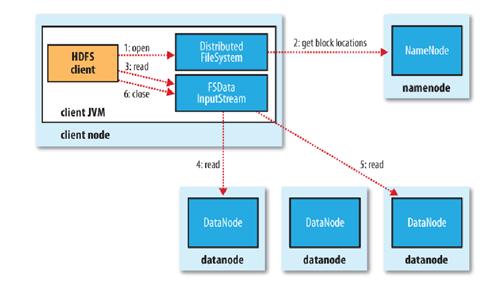
- 使用HDFS提供的客户端开发库,向远程的Namenode发起RPC请求;
- Namenode会视情况返回文件的部分或者全部block列表,对于每个block,Namenode都会返回有该block拷贝的datanode地址;
- 客户端开发库会选取离客户端最接近的datanode来读取block;
- 读取完当前block的数据后,关闭与当前的datanode连接,并为读取下一个block寻找最佳的datanode;oracle教程
- 当读完列表的block后,且文件读取还没有结束,客户端开发库会继续向Namenode获取下一批的block列表。
- 读取完一个block都会进行checksum验证,如果读取datanode时出现错误,客户端会通知Namenode,然后再从下一个拥有该block拷贝的datanode继续读取。
这里需要注意的关键点是:多个Datanode顺序读取。
其次再看文件的写入机制: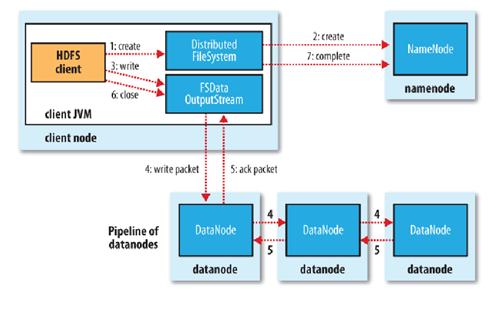
- 使用HDFS提供的客户端开发库,向远程的Namenode发起RPC请求;
- Namenode会检查要创建的文件是否已经存在,创建者是否有权限进行操作,成功则会为文件创建一个记录,否则会让客户端抛出异常;
- 当客户端开始写入文件的时候,开发库会将文件切分成多个packets,并在内部以”data queue”的形式管理这些packets,并向Namenode申请新的blocks,获取用来存储replicas的合适的datanodes列表, 列表的大小根据在Namenode中对replication的设置而定。
- 开始以pipeline(管道)的形式将packet写入所有的replicas中。开发库把packet以流的方式写入第一个 datanode,该datanode把该packet存储之后,再将其传递给在此pipeline中的下一个datanode,直到最后一个 datanode,这种写数据的方式呈流水线的形式。
- 最后一个datanode成功存储之后会返回一个ack packet,在pipeline里传递至客户端,在客户端的开发库内部维护着”ack queue”,成功收到datanode返回的ack packet后会从”ack queue”移除相应的packet。
- 如果传输过程中,有某个datanode出现了故障,那么当前的pipeline会被关闭,出现故障的datanode会从当前的 pipeline中移除,剩余的block会继续剩下的datanode中继续以pipeline的形式传输,同时Namenode会分配一个新的 datanode,保持replicas设定的数量。
-
经李克强总理签批,2015年9月,国务院印发《促进大数据发展行动纲要》(以下简称《纲要》),系统部署大数据发展工作。oracle视频教程
《纲要》明确,推动大数据发展和应用,在未来5至10年打造精准治理、多方协作的社会治理新模式,建立运行平稳、安全高效的经济运行新机制,构建以人为本、惠及全民的民生服务新体系,开启大众创业、万众创新的创新驱动新格局,培育高端智能、新兴繁荣的产业发展新生态。
《纲要》部署三方面主要任务。一要加快政府数据开放共享,推动资源整合,提升治理能力。大力推动政府部门数据共享,稳步推动公共数据资源开放,统筹规划大数据基础设施建设,支持宏观调控科学化,推动政府治理精准化,推进商事服务便捷化,促进安全保障高效化,加快民生服务普惠化。二要推动产业创新发展,培育新兴业态,助力经济转型。发展大数据在工业、新兴产业、农业农村等行业领域应用,推动大数据发展与科研创新有机结合,推进基础研究和核心技术攻关,形成大数据产品体系,完善大数据产业链。三要强化安全保障,提高管理水平,促进健康发展。健全大数据安全保障体系,强化安全支撑。[11]
2015年9月18日贵州省启动我国首个大数据综合试验区的建设工作,力争通过3至5年的努力,将贵州大数据综合试验区建设成为全国数据汇聚应用新高地、综合治理示范区、产业发展聚集区、创业创新首选地、政策创新先行区。
围绕这一目标,贵州省将重点构建“三大体系”,重点打造“七大平台”,实施“十大工程”。
“三大体系”是指构建先行先试的政策法规体系、跨界融合的产业生态体系、防控一体的安全保障体系;“七大平台”则是指打造大数据示范平台、大数据集聚平台、大数据应用平台、大数据交易平台、大数据金融服务平台、大数据交流合作平台和大数据创业创新平台;“十大工程”即实施数据资源汇聚工程、政府数据共享开放工程、综合治理示范提升工程、大数据便民惠民工程、大数据三大业态培育工程、传统产业改造升级工程、信息基础设施提升工程、人才培养引进工程、大数据安全保障工程和大数据区域试点统筹发展工程。
此外,贵州省将计划通过综合试验区建设,探索大数据应用的创新模式,培育大数据交易新的做法,开展数据交易的市场试点,鼓励产业链上下游之间的数据交换,规范数据资源的交易行为,促进形成新的业态。
国家发展改革委有关专家表示,大数据综合试验区建设不是简单的建产业园、建数据中心、建云平台等,而是要充分依托已有的设施资源,把现有的利用好,把新建的规划好,避免造成空间资源的浪费和损失。探索大数据应用新的模式,围绕有数据、用数据、管数据,开展先行先试,更好地服务国家大数据发展战略。
#p#分页标题#e#
关键词:开发库把packet以流的方式写入第一个datanode,该datanode将其传递给pipeline中的下一个datanode,知道最后一个Datanode,这种写数据的方式呈流水线方式。
二、解决方案oracle数据库教程
1.下载效率优化
通过以上读写机制的分析,我们可以发现基于Hadoop实现的云盘客户段下载效率的优化可以从两个层级着手:
1.文件整体层面:采用并行访问多线程(多进程)份多文件并行读取。
2.Block块读取:改写Hadoop接口扩展,多Block并行读取。
2.上传效率优化
上传效率优化只能采用文件整体层面的并行处理,不支持分Block机制的多Block并行读取。
更多视频课程文章的课程,可到课课家官网查看。我在等你哟!!!
