恍惚恍惚又来到了文章的学习,想必大家又有很多问题吧!
因为项目的需要,学习使用了Hadoop,和所有过热的技术一样,“大数据”、“海量”这类词语在互联网上满天乱飞。Hadoop是一个非常优秀的分布式编程框架,设计精巧而且目前没有同级别同重量的替代品。另外也接触到一个内部使用的框架,对于Hadoop做了封装和定制,使得更满足业务需求。我最近也想写一些Hadoop的学习和使用心得,但是看到网上那么泛滥的文章,我觉得再写点笔记一样的东西实在是没有价值。倒不如在漫天颂歌的时候冷静下来看看,有哪些不适合Hadoop解决的难题呢?
oracle数据库教程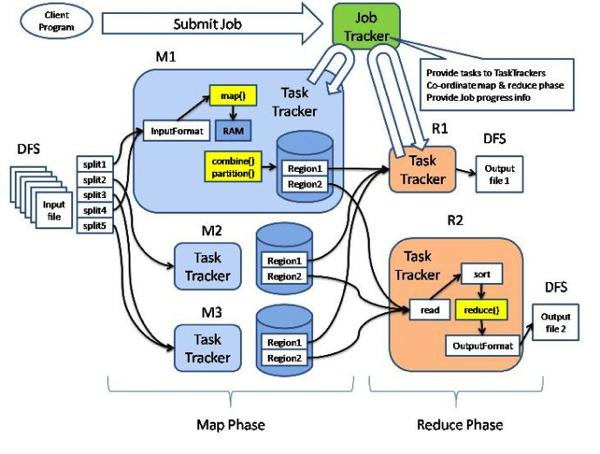
这张图就是Hadoop的架构图,Map和Reduce是两个最基本的处理阶段,之前有输入数据格式定义和数据分片,之后有输出数据格式定义,二者中间还可以实现combine这个本地reduce操作和partition这个重定向mapper输出的策略行为。可以增加的定制和增强包括:
oracle视频教程
大数据的价值体现在以下几个方面:1)对大量消费者提供产品或服务的企业可以利用大数据进行精准营销;2) 做小而美模式的中长尾企业可以利用大数据做服务转型;3) 面临互联网压力之下必须转型的传统企业需要与时俱进充分利用大数据的价值。
不过,“大数据”在经济发展中的巨大意义并不代表其能取代一切对于社会问题的理性思考,科学发展的逻辑不能被湮没在海量数据中。著名经济学家路德维希·冯·米塞斯曾提醒过:“就今日言,有很多人忙碌于资料之无益累积,以致对问题之说明与解决,丧失了其对特殊的经济意义的了解。”[5] 这确实是需要警惕的。
这些定制从某种程度上也反应了Hadoop在实际使用中略感局限或者设计时无暇顾及的地方,但是这些都是小问题,都是通过定制和扩展能够修复的。但是有一些问题,是Hadoop天生无法解决的,或者说,是不适合使用Hadoop来解决的问题。
1、最最重要一点,Hadoop能解决的问题必须是可以MapReduce的。这里有两个特别的含义,一个是问题必须可以拆分,有的问题看起来很大,但是拆分很困难;第二个是子问题必须独立——很多Hadoop的教材上面都举了一个斐波那契数列的例子,每一步数据的运算都不是独立的,都必须依赖于前一步、前二步的结果,换言之,无法把大问题划分成独立的小问题,这样的场景是根本没有办法使用Hadoop的。
2、数据结构不满足key-value这样的模式的。在Hadoop In Action中,作者把Hadoop和关系数据库做了比较,结构化数据查询是不适合用Hadoop来实现的(虽然像Hive这样的东西模拟了ANSI SQL的语法)。即便如此,性能开销不是一般关系数据库可以比拟的,而如果是复杂一点的组合条件的查询,还是不如SQL的威力强大。编写代码调用也是很花费时间的。
3、Hadoop不适合用来处理大批量的小文件。其实这是由namenode的局限性所决定的,如果文件过小,namenode存储的元信息相对来说就会占用过**例的空间,内存还是磁盘开销都非常大。如果一次task的文件处理较大,那么虚拟机启动、初始化等等准备时间和任务完成后的清理时间,甚至shuffle等等框架消耗时间所占的比例就小得多;反之,处理的吞吐量就掉下来了。(有人做了一个实验,参阅:链接)
oracle视频
4、Hadoop不适合用来处理需要及时响应的任务,高并发请求的任务。这也很容易理解,上面已经说了虚拟机开销、初始化准备时间等等,即使task里面什么都不做完整地跑一遍job也要花费几分钟时间。
5、Hadoop要处理真正的“大数据”,把scale up真正变成scale out,两台小破机器,或者几、十几GB这种数据量,用Hadoop就显得粗笨了。异步系统本身的直观性并不像那些同步系统来得好,这是显而易见的。所以基本上来说,维护成本不会低。
更多视频课程文章的课程,可到课课家官网查看。我在等你哟!!!
