Hadoop 2.0:分布式环境搭建安装配置及简介
在众多学习中,文章也许不起眼,但是重要的下面我们就来讲解一下!!
集群环境:
1 NameNode(真实主机):
Linuxyan-Server 3.4.36-gentoo #3 SMP Mon Apr 1 14:09:12 CST 2013 x86_64 AMD Athlon(tm) X4 750K Quad Core Processor AuthenticAMD GNU/Linux
2 DataNode1(虚拟机):
Linux node1 3.5.0-23-generic #35~precise1-Ubuntu SMP Fri Jan 25 17:13:26 UTC 2013 x86_64 x86_64 x86_64 GNU/Linux
3 DataNode2(虚拟机):
Linux node2 3.5.0-23-generic #35~precise1-Ubuntu SMP Fri Jan 25 17:13:26 UTC 2013 x86_64 x86_64 x86_64 GNU/Linux
4 DataNode3(虚拟机):
Linux node3 3.5.0-23-generic #35~precise1-Ubuntu SMP Fri Jan 25 17:13:26 UTC 2013 x86_64 x86_64 x86_64 GNU/Linux
1.安装VirtualBox虚拟机
Gentoo下直接命令编译安装,或者官网下载二进制安装包直接安装:
emerge -av virtualboxoracle教程
2.虚拟机下安装Ubuntu 12.04 LTS
使用Ubuntu镜像安装完成后,然后再克隆另外两台虚拟主机(这里会遇到克隆的主机启动的时候主机名和MAC地址会是一样的,局域网会造成冲突)
主机名修改文件
/etc/hostname
MAC地址修改需要先删除文件
/etc/udev/rules.d/70-persistent-net.rules
然后在启动之前设置VirtualBox虚拟机的MAC地址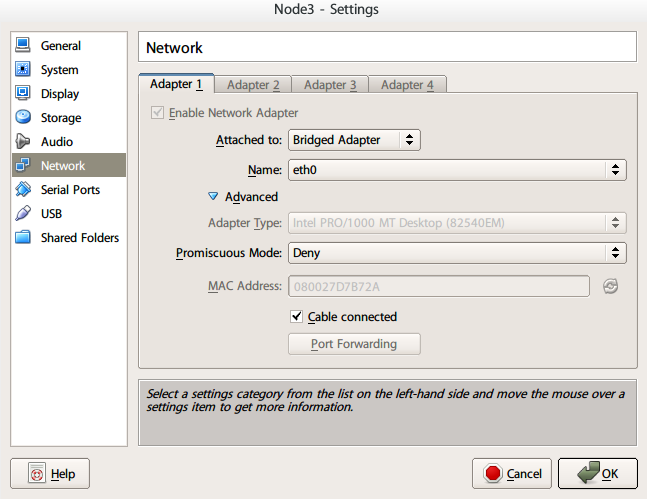
启动后会自动生成删除的文件,配置网卡的MAC地址。
为了更方便的在各主机之间共享文件,可以启动主机yan-Server的NFS,将命令加入/etc/rc.local中,让客户端自动挂载NFS目录。
删除各虚拟机的NetworkManager,手动设置静态的IP地址,例如node2主机的/etc/network/interfaces文件配置如下:
- auto lo
- iface lo inet loopback
- auto eth0
- iface eth0 inet static
- address 192.168.137.202
- gateway 192.168.137.1
- netmask 255.255.255.0
- network 192.168.137.0
- broadcast 192.168.137.255
主机的基本环境设置完毕,下面是主机对应的IP地址
| 类型 | 主机名 | IP |
| NameNode | yan-Server | 192.168.137.100 |
| DataNode | node1 | 192.168.137.201 |
| DataNode | node2 | 192.168.137.202 |
| DataNode | node3 | 192.168.137.203 |
为了节省资源,可以设置虚拟机默认启动字符界面,然后通过主机的TERMINAL ssh远程登录。(SSH已经启动服务,允许远程登录,安装方法不再赘述)
设置方式是修改/etc/default/grub文件将下面的一行解除注释
GRUB_TERMINAL=consoleoracle视频教程
然后update-grub即可。
3.环境的配置
3.1配置JDK环境(之前就做好了,这里不再赘述)
3.2在官网下载Hadoop,然后解压到/opt/目录下面(这里使用的是hadoop-2.0.4-alpha)
然后进入目录/opt/hadoop-2.0.4-alpha/etc/hadoop,配置hadoop文件
修改文件hadoop-env.sh
- export HADOOP_FREFIX=/opt/hadoop-2.0.4-alpha
- export HADOOP_COMMON_HOME=${HADOOP_FREFIX}
- export HADOOP_HDFS_HOME=${HADOOP_FREFIX}
- export PATH=$PATH:$HADOOP_FREFIX/bin
- export PATH=$PATH:$HADOOP_FREFIX/sbin
- export HADOOP_MAPRED_HOME=${HADOOP_FREFIX}
- export Yarn_HOME=${HADOOP_FREFIX}
- export HADOOP_CONF_HOME=${HADOOP_FREFIX}/etc/hadoop
- export YARN_CONF_DIR=${HADOOP_FREFIX}/etc/hadoop
- export Java_HOME=/opt/jdk1.7.0_21
修改文件hdfs-site.xml
- dfs.namenode.name.dir
- file:/opt/hadoop-2.0.4-alpha/workspace/name
- Determines where on the local filesystem the DFS name node should store the
- name table.If this is a comma-delimited list of directories,then name table is
- replicated in all of the directories,for redundancy.
- true
- dfs.datanode.data.dir
- file:/opt/hadoop-2.0.4-alpha/workspace/data
- Determines where on the local filesystem an DFS data node should
- store its blocks.If this is a comma-delimited list of directories,then data will
- be stored in all named directories,typically on different devices.Directories that do not exist are ignored.
- true
- dfs.replication
- 1
- dfs.permission
- false
#p#分页标题#e#
修改文件mapred-site.xml
经李克强总理签批,2015年9月,国务院印发《促进大数据发展行动纲要》(以下简称《纲要》),系统部署大数据发展工作。
《纲要》明确,推动大数据发展和应用,在未来5至10年打造精准治理、多方协作的社会治理新模式,建立运行平稳、安全高效的经济运行新机制,构建以人为本、惠及全民的民生服务新体系,开启大众创业、万众创新的创新驱动新格局,培育高端智能、新兴繁荣的产业发展新生态。
《纲要》部署三方面主要任务。一要加快政府数据开放共享,推动资源整合,提升治理能力。大力推动政府部门数据共享,稳步推动公共数据资源开放,统筹规划大数据基础设施建设,支持宏观调控科学化,推动政府治理精准化,推进商事服务便捷化,促进安全保障高效化,加快民生服务普惠化。二要推动产业创新发展,培育新兴业态,助力经济转型。发展大数据在工业、新兴产业、农业农村等行业领域应用,推动大数据发展与科研创新有机结合,推进基础研究和核心技术攻关,形成大数据产品体系,完善大数据产业链。三要强化安全保障,提高管理水平,促进健康发展。健全大数据安全保障体系,强化安全支撑。[11]
2015年9月18日贵州省启动我国首个大数据综合试验区的建设工作,力争通过3至5年的努力,将贵州大数据综合试验区建设成为全国数据汇聚应用新高地、综合治理示范区、产业发展聚集区、创业创新首选地、政策创新先行区。
围绕这一目标,贵州省将重点构建“三大体系”,重点打造“七大平台”,实施“十大工程”。
“三大体系”是指构建先行先试的政策法规体系、跨界融合的产业生态体系、防控一体的安全保障体系;“七大平台”则是指打造大数据示范平台、大数据集聚平台、大数据应用平台、大数据交易平台、大数据金融服务平台、大数据交流合作平台和大数据创业创新平台;“十大工程”即实施数据资源汇聚工程、政府数据共享开放工程、综合治理示范提升工程、大数据便民惠民工程、大数据三大业态培育工程、传统产业改造升级工程、信息基础设施提升工程、人才培养引进工程、大数据安全保障工程和大数据区域试点统筹发展工程。
此外,贵州省将计划通过综合试验区建设,探索大数据应用的创新模式,培育大数据交易新的做法,开展数据交易的市场试点,鼓励产业链上下游之间的数据交换,规范数据资源的交易行为,促进形成新的业态。
国家发展改革委有关专家表示,大数据综合试验区建设不是简单的建产业园、建数据中心、建云平台等,而是要充分依托已有的设施资源,把现有的利用好,把新建的规划好,避免造成空间资源的浪费和损失。探索大数据应用新的模式,围绕有数据、用数据、管数据,开展先行先试,更好地服务国家大数据发展战略。
- mapreduce.framework.name
- yarn
- mapreduce.job.tracker
- hdfs://yan-Server:9001
- true
- mapreduce.map.memory.mb
- 1536
- mapreduce.map.java.opts
- -Xmx1024M
- mapreduce.reduce.memory.mb
- 3072
- mapreduce.reduce.java.opts
- -Xmx2560M
- mapreduce.task.io.sort.mb
- 512
- mapreduce.task.io.sort.factor
- 100
- mapreduce.reduce.shuffle.parallelcopies
- 50
- oracle视频
- mapred.system.dir
- file:/opt/hadoop-2.0.4-alpha/workspace/systemdir
- true
- mapred.local.dir
- file:/opt/hadoop-2.0.4-alpha/workspace/localdir
- true
#p#分页标题#e#
修改文件yarn-env.xml
- export HADOOP_FREFIX=/opt/hadoop-2.0.4-alpha
- export HADOOP_COMMON_HOME=${HADOOP_FREFIX}
- export HADOOP_HDFS_HOME=${HADOOP_FREFIX}
- export PATH=$PATH:$HADOOP_FREFIX/bin
- export PATH=$PATH:$HADOOP_FREFIX/sbin
- export HADOOP_MAPRED_HOME=${HADOOP_FREFIX}
- export YARN_HOME=${HADOOP_FREFIX}
- export HADOOP_CONF_HOME=${HADOOP_FREFIX}/etc/hadoop
- export YARN_CONF_DIR=${HADOOP_FREFIX}/etc/hadoop
- export JAVA_HOME=/opt/jdk1.7.0_21
修改文件yarn-site.xml
- oracle数据库教程
- yarn.resourcemanager.address
- yan-Server:8080
- yarn.resourcemanager.scheduler.address
- yan-Server:8081
- yarn.resourcemanager.resource-tracker.address
- yan-Server:8082
- yarn.nodemanager.aux-services
- mapreduce.shuffle
- yarn.nodemanager.aux-services.mapreduce.shuffle.class
- org.Apache.hadoop.mapred.ShuffleHandler
将配置好的Hadoop复制到各DataNode(这里DataNode的JDK配置和主机的配置是一致的,不需要再修改JDK的配置)
3.3 修改主机的/etc/hosts,将NameNode加入该文件
192.168.137.100yan-Server
192.168.137.201node1
192.168.137.202node2
192.168.137.203node3
3.4 修改各DataNode的/etc/hosts文件,也添加上述的内容
192.168.137.100yan-Server
192.168.137.201node1
192.168.137.202node2
192.168.137.203node3
3.5 配置SSH免密码登录(所有的主机都使用root用户登录)
主机上运行命令
ssh-kengen -t rsa
一路回车,然后复制.ssh/id_rsa.pub为各DataNode的root用户目录.ssh/authorized_keys文件
然后在主机上远程登录一次
ssh [email protected]
首次登录可能会需要输入密码,之后就不再需要。(其他的DataNode也都远程登录一次确保可以免输入密码登录)
4.启动Hadoop
为了方便,在主机的/etc/profile配置hadoop的环境变量,如下:
- export HADOOP_PREFIX=”/opt/hadoop-2.0.4-alpha”
- export PATH=$PATH:$HADOOP_PREFIX/bin
- export PATH=$PATH:$HADOOP_PREFIX/sbin
- export HADOOP_MAPRED_HOME=${HADOOP_PREFIX}
- export HADOOP_COMMON_HOME=${HADOOP_PREFIX}
- export HADOOP_HDFS_HOME=${HADOOP_PREFIX}
- export YARN_HOME=${HADOOP_PREFIX}
4.1 格式化NameNode
hdfs namenode -format
4.2 启动全部进程
start-all.shVBz003.png”>
在浏览器查看,地址:
http://localhost:8088/
所有数据节点DataNode正常启动。
4.3 关闭所有进程
stop-all.sh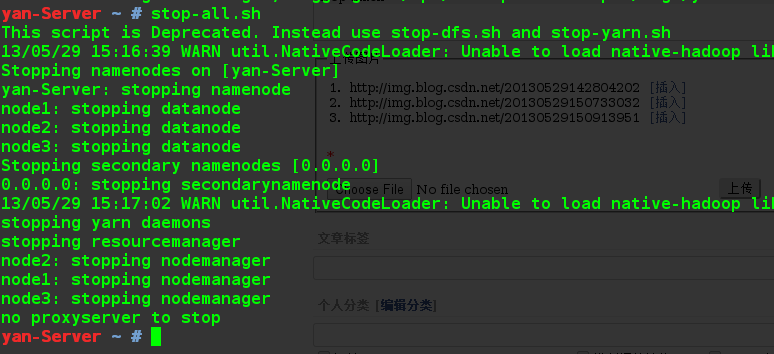
至此,Hadoop环境搭建基本结束。
更多视频课程文章的课程,可到课课家官网查看。我在等你哟!!!
