大数据小白,你对hadoop有了解吗?
大数据它是一个特别有意思的一个词语,要想去学好大数据,在前面的文章中已经是给大家有讲解过,要想学习好除了学习好java编程、Linux操作系统、以及基本的SQL数据库操作之外,这也是必学的基本操作,学习大数据是否会遇到Hadoop、kettle等之类的学习疑惑,这些专业的术语是否阻碍了你的学习路?大数据小白应该要了解清楚。

我们知道Hadoop是属于Apache软件基金会管理的开源软件平台,但很多人或者是不了解Hadoop到底是什么呢?可以简单的理解为Hadoop是在分布式服务器集群上存储海量数据并运行分布式分析应用的一种方法,可以理解为它是一种方法。
需要知道的是,Hadoop它是被设计成一种非常“鲁棒”的系统,即使某台服务器甚至集群宕机了,在运行其上的大数据分析应用也不会中断。除此之外的话Hadoop的效率也很高,因为它并不需要你在网络间来进行数据的一个折腾,提升一个实际的效率。
经常听说的Hadoop它是一个用于运行应用程序在大型集群的硬件设备上的框架。Hadoop可以为应用程序透明的提供了一组稳定/可靠的接口和数据运动。在Hadoop中是可以实现Google的MapReduce算法,它能够把应用程序分割成许多很小的工作单元,而每个单元可以在任何集群节点上执行或重复执行。
除此之外,Hadoop还是提供一个分布式文件系统用来在各个计算节点上存储数据,并提供了对数据读写的高吞吐率,因为应用了map/reduce和分布式文件系统使得Hadoop框架具有高容错性,它会自动处理失败节点。
Hadoop分布式文件系统(HDFS)
如果你还是对Hadoop一片空白的话,则是需要记住这一点:Hadoop它是有两个主要部分:一个是数据处理框架和一个分布式数据存储文件系统(HDFS)。
很多人会问到底什么是hadoop,是一种技术?一种架构?一种软件?
它是一种框架
它是包含HDFS,MAPREDUCE两部分,它是分别代表怎么存取数据和怎么使用数据
前面已经是说了HDFS是用来分布式存储的,意思就是上传的数据会分成多份备份分别存在多个服务器(终端)里面,一台挂了也会因为其他服务器还活着且其他服务器上有上传时备份来的数据而不影响继续使用数据
Mapreduce函数式设计,在传统计算方式就是把数据移动到终端设计好的公式里面去计算,mapreduce是把公式移动到终端(终端上有上面说到的“多分数据”)对各终端的数据进行计算。因为分成“多份”备份的分数和分布的终端数不一定一样,因此就有了对应关系(map)指定那块数据在哪些系统中有备份。
看到下图的一个对应的关系:
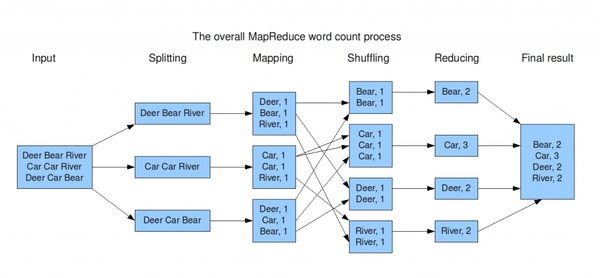
相信大家看完之后,对hadoop的概念解释有一定的了解,简单的来说有很多服务器存储了很多文件。想要从这些文件里面查找想要的内容,把任务描述清楚,它就把结果返回给你了,最简单的理解就是架构系统,其中有各式各样的组件。
