让热点图支持我们的大数据
欢迎大家阅读本文章,本文章是一篇让热点图支持大数据的文章。这篇文章会给大家带来一些关于热点图和大数据的相关知识详解,希望本篇文章能帮助到你,对你有所收获,让我们开始学习吧,课课家提醒您:大家仔细阅读文章。课课家教育提醒您:要认真好好阅读哦~~
所谓的热点图,是图1)构建一张灰度图,图2)在每个热点的位置上绘制并叠加形成灰色的热点图,图3)根据颜色表生成热点图。不难看出,最核心的是图2的过程。详情参考《可视化之热点图》。

图1

图2&图3
1强调两处细节
这种思路效率高,缺点就是不够灵活,每个点都是同一个样式,没有考虑该点的半径和权重。创建大小不一的模版(章),每个热点根据自己的半径值选择对应的章就可以,实现思路如下:
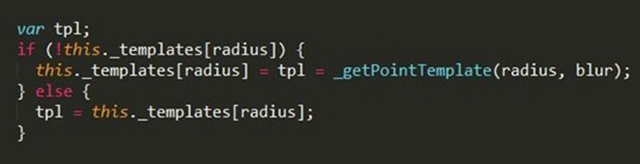
半径&模版
权重的不同,是通过盖章的“力度”,权重越大,不透明度越大,这样叠加时也越能体现权重大的效果。是否发现,这个方式会产生覆盖情况,并不严谨。
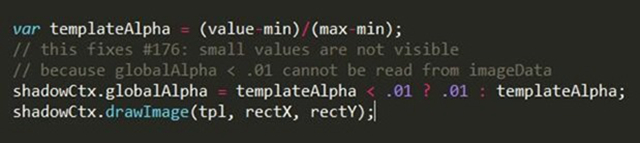
权重&透明度(力度)
2大数据渲染
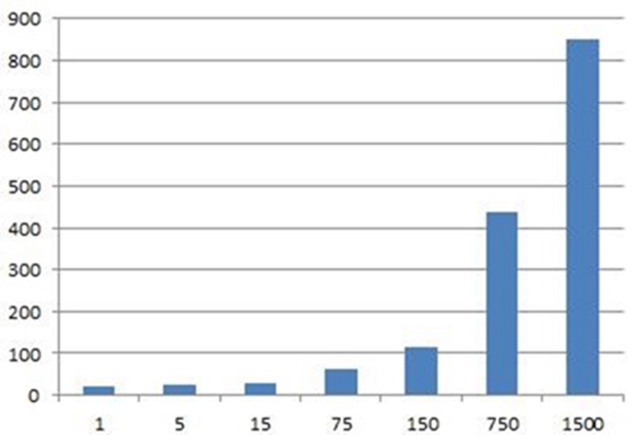
我们看看在不同数据量下的性能分析。7759个热点,每个点有经纬度和权重三个float值,生成一张2000*1400左右的热点图。采用pa7/heatmap.js,在Chrome下测试1w(1倍),5w(5倍),10w(15倍),60w(75倍),100w(150倍),600w(750)六个级别,千万级别会崩溃。
备注:只测试了一次,误差估计不小,仅供参考。
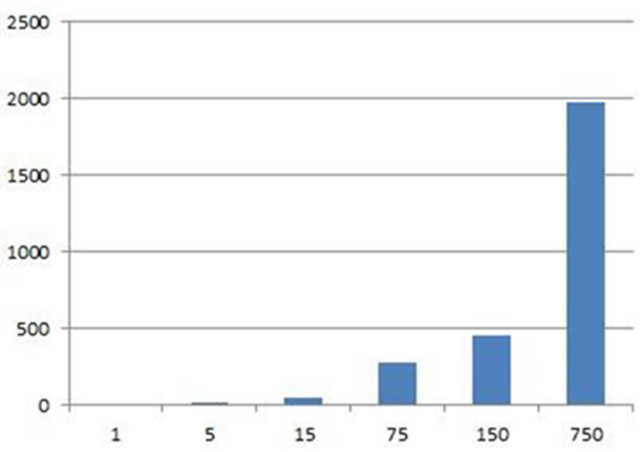
数据转换消耗(毫秒)
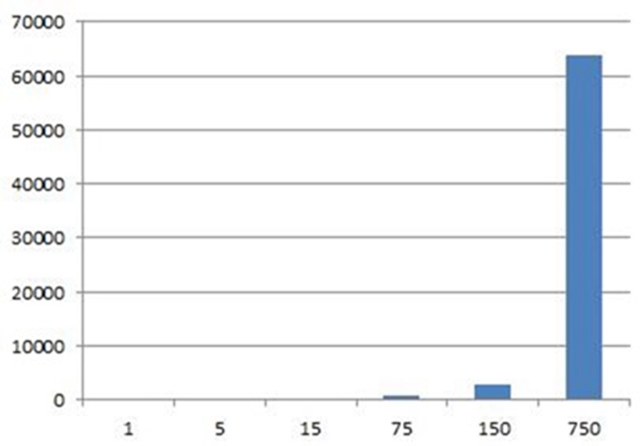
纯渲染时间(毫秒)
在这种方式下渲染时间依次为:68,100,194,894,2918,63817(ms)。数据量在100w以内的还好,渲染时间将近3s。但再往上就不给力了。千万级别下读取会崩溃,内存达到1.2G以上。渲染就算可用,从时间消耗上也不实用。
在渲染性能方面,之前我们通过模版,盖章的思路已经优化了,沿着这个思路提升空间不大。而且,因为渲染上存在叠加依赖,很难并行。
CPU并行
自己实现渲染算法,以并行的方式实现数值计算部分。思路如下:对热点图这个目标图片,遍历每一个像素,以像素半径做一个缓冲区分析,获取对应的热点数据(数据支持范围查询)。如果没有热点,则该像素为空;如果存在N个热点,则计算该点的热点值。乍看上去,这不是又倒退到逐点计算的思路上。
坦白说,我很不喜欢这个思路,就好比老师出了一道1+2+3……+100的题目,本来是想让你发现规律和数据模型,。可是你真的在一个个累加。但全班同学合作,把这100个数分解成10组,每人分别计算一部分,同样也能很快得出结果,这就是另一个角度的智慧。
因为每个点的计算是独立的,可以通过并行来优化“渲染”时间。但这种思路是以放弃渲染技术为代价的,也要借助于空间索引,并行计算,在JS上很难实现。
另外,这个思路让我认为(不知道对不对),点差值和热点图并无本质区别。
GPU并行
下图是OpenGL的思路:每一个热点构造成一个正方形,对角线将其分为两个三角形,有四个顶点和6个顶点索引。采用批次渲染的方式,每个批次下渲染1w个热点(对应4w个顶点),将数据分解为多个批次,实现大数据的渲染,GPU中实现混合效果。具体的shader代码可以参考pyalot。
#p#分页标题#e#
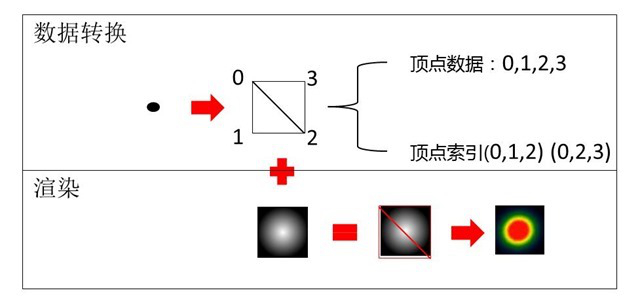
我在WebGL下实现了这个思路,还是刚才那个7759个热点的数据,我放到一个渲染批次,对这一个批次渲染多次, 1s内完成千万级别的渲染。
3问题
数据解析是瓶颈,比如经纬度点最终要转换到像素单。如果性能还不够,就“偷工减料”,建立矢量金字塔,本质就是把N个点合并成一个,减少渲染过程的计算量。
二维对应的策略是,渲染性能不够,就把渲染问题转为for循环下的简单计算,然后通过CPU并行优化;对于三维,需要点转三角形,创建buffer,然后通过GPU实现渲染过程。
从渲染的角度来看,无论二维还是三维,在十万级别下的性能都不错,百万级别也能接受,差别不大,但十万以上,两者的渲染差距则体现出来,前者像打狗棒,强调的是心法和招式,后者则是降龙十八掌,靠的是内力。两点区别,二维是因为渲染性能不行,只好采用最简单的数值计算,以这样的代价实现核心计算的并行;三维本身就是并行策略,就是通过shader,通过顶点和片元实现GPU的并行。第二,GPU的并行能力显然不是CPU可以媲美的,换句话说,GPU能够承担更多的并发计算量,尽可能少的对原始数据做预处理,理论上,只要内存够用或读取数据合理,显存上通过批次渲染,可以渲染任意大的数据量,而且时间和批次应该是线性的。
最后,再强调一下数据。简单计算了一下,假如是一个二进制流的方式,一个热点占12个字节,这样1kw个点要占120M,即使压缩后也得20M,这还没有考虑数据转换上的消耗。对于web端,基于原始数据,需要有一种机制,能够快速的完成数据传输和处理。
有一个不一定对的思路,建一个GeoHash,大范围的预先生成热点图,更新频率可以不高;局部范围则通过GeoHash获取对应的热点,实现本地渲染。GeoHsh貌似是一种很不错的大数据设计方式,我也不太了解,有时间再研究研究。
还有一个收获,当复杂度达到一定程度,原先行得通的算法和方案不一定满足要求了。更精彩的是,因为性能低,以前认为比较差的思路,因为思路简单,容易实现并行改造,竟然可行了。
大数据小知识:
存储
随着大数据应用的爆发性增长,它已经衍生出了自己独特的架构,而且也直接推动了存储、网络以及计算技术的发展。毕竟处理大数据这种特殊的需求是一个新的挑战。
硬件的发展最终还是由软件需求推动的,我们很明显的看到大数据分析应用需求正在影响着数据存储基础设施的发展。
从另一方面看,这一变化对存储厂商和其他IT基础设施厂商未尝不是一个机会。
随着结构化数据和非结构化数据量的持续增长,以及分析数据来源的多样化,此前存储系统的设计已经无法满足大数据应用的需要。
存储厂商已经意识到这一点,他们开始修改基于块和文件的存储系统的架构设计以适应这些新的要求。
总结:大家都会了呢~相信大家对热点图也有些了解了呢~也一定知道了大数据的相关知识的详细介绍,要是您还有什么问题,课课家平台,随时为您服务,关于更多的知识,后面还有很多关于类似的文章,期待大家的到来。
