这篇文章主要讲的是重复数据的概念原理和怎样使用重复数据删除技术。重复数据删除是一个很热门的存储技术。希望本篇文章多你们有用,大家要认真看噢~
Dedupe概述
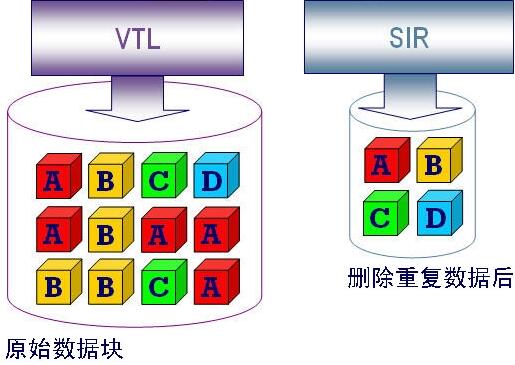
De-duplication,即重复数据删除,它是一种目前主流且非常热门的存储技术,可对存储容量进行有效优化。它通过删除数据集中重复的数据,只保留其中一份,从而消除冗余数据。如下图所示。这种技术可以很大程度上减少对物理存储空间的需求,从而满足日益增长的数据存储需求。
Dedupe技术可以带许多实际的利益,主要包括以下诸多方面:
(1) 满足ROI(投资回报率,Return On Investment)/TCO(总持有成本,Total Cost of Ownership)需求;
(2) 可以有效控制数据的急剧增长;
(3) 增加有效存储空间,提高存储效率;
(4) 节省存储总成本和管理成本;
(5) 节省数据传输的网络带宽;
(6) 节省空间、电力供应、冷却等运维成本。
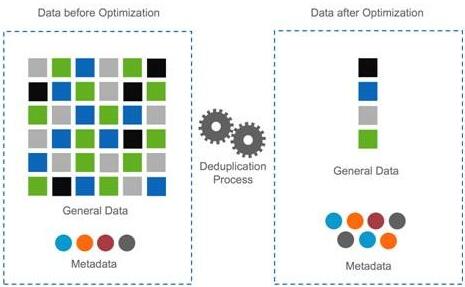
Dedupe技术目前大量应用于数据备份与归档系统,因为对数据进行多次备份后,存在大量重复数据,非常适合这种技术。事实上,dedupe技术可以用于很多场合,包括在线数据、近线数据、离线数据存储系统,可以在文件系统、卷管理器、NAS、SAN中实施。Dedupe也可以用于数据容灾、数据传输与同步,作为一种数据压缩技术可用于数据打包。Dedupe技术可以帮助众多应用降低数据存储量,节省网络带宽,提高存储效率、减小备份窗口,节省成本。
大数据与海量数据已经成为数据中心的主要业务,而重复数据删除与压缩是可以节约大量数据存储的技术。
只有备份还不够。重复数据删除与压缩即将成为主存储的必备功能。
重复数据删除是一种压缩技术,通过识别重复内容,进行去重,并在对应的存储位置留下指针,来最小化数据量。这个指针通过给定大小的数据模式进行哈希创建。
也许在于你已经在备份系统上实施了重复数据删除备份和归档多年,问题在于:是否需要在主存储上运用重复数据删除与压缩技术?
并非所有的重复数据删除技术都一样。IT专业人士在将其添加到主存储环境之前,应该权衡其各自的特点。
何时使用重复数据删除
重复数据删除首先开始于创建数据。接着是所有其他业务——备份、复制、归档以及任何网络传输——都可以受益于规模缩小后的数据,位于Hopkinton。
“几年前,我写道,自己知道为什么重复数据删除技术通常被应用于备份设备上。但是,如果没有限制,重复数据删除应该在数据被创建时进行,而且数据在整个生命周期内,应该以某种脱水格式存储,” Taneja说。唯一的例外应该是当用户或应用程序需要访问这些数据时。
但把重复数据删除应用在主数据这一场景很难被用户接收,因为这样做是在篡改主数据集,Storage Switzerland LLC存储顾问公司的首席分析师George Crump说。“做好备份,就算没有重复数据删除技术,也不会因为搞砸生产环境的数据而出大乱子,”他说,“但是如果动到主存储,问题就很大了,而且需要了解这项技术会如何影响性能、可靠性与数据完整性。”
目前只有少数主存储阵列提供重复数据删除作为产品的附加功能。只有不到5%的磁盘阵列真正支持在线重复数据删除与压缩,Permabit公司的CEO Tom Cook说。该公司是一家数据效率技术供应商。不过,这个数字在未来的18个月内将可能增长到25%,并且在36个月后达到75%,Cook说。
Dedupe关键技术
存储系统的重复数据删除过程一般是这样的:首先将数据文件分割成一组数据块,为每个数据块计算指纹,然后以指纹为关键字进行Hash查找,匹配则表示该数据块为重复数据块,仅存储数据块索引号,否则则表示该数据块是一个新的唯一块,对数据块进行存储并创建相关元信息。这样,一个物理文件在存储系统就对应一个逻辑表示,由一组FP组成的元数据。当进行读取文件时,先读取逻辑文件,然后根据FP序列,从存储系统中取出相应数据块,还原物理文件副本。,Dedupe的关键技术主要包括文件数据块切分、数据块指纹计算和数据块检索。
#p#分页标题#e#

(1) 文件数据块切分
Dedupe按照消重的粒度可以分为文件级和数据块级。文件级的dedupe技术也称为单一实例存储(SIS, Single Instance Store),数据块级的重复数据删除其消重粒度更小,可以达到4-24KB之间。显然,数据块级的可以提供更高的数据消重率,因此目前主流的dedupe产品都是数据块级的。数据分块算法主要有三种,即定长切分(fixed-size partition)、CDC切分(content-defined chunking)和滑动块(sliding block)切分。定长分块算法采用预先义好的块大小对文件进行切分,并进行弱校验值和md5强校验值。弱校验值主要是为了提升差异编码的性能,先计算弱校验值并进行hash查找,如果发现则计算md5强校验值并作进一步hash查找。由于弱校验值计算量要比md5小很多,因此可以有效提高编码性能。定长分块算法的优点是简单、性能高,但它对数据插入和删除非常敏感,处理十分低效,不能根据内容变化作调整和优化。
CDC(content-defined chunking)算法是一种变长分块算法,它应用数据指纹(如Rabin指纹)将文件分割成长度大小不等的分块策略。与定长分块算法不同,它是基于文件内容进行数据块切分的,因此数据块大小是可变化的。算法执行过程中,CDC使用一个固定大小(如48字节)的滑动窗口对文件数据计算数据指纹。如果指纹满足某个条件,如当它的值模特定的整数等于预先设定的数时,则把窗口位置作为块的边界。CDC算法可能会出现病态现象,即指纹条件不能满足,块边界不能确定,导致数据块过大。实现中可以对数据块的大小进行限定,设定上下限,解决这种问题。CDC算法对文件内容变化不敏感,插入或删除数据只会影响到检少的数据块,其余数据块不受影响。CDC算法也是有缺陷的,数据块大小的确定比较困难,粒度太细则开销太大,粒度过粗则dedup效果不佳。如何两者之间权衡折衷,这是一个难点。
滑动块(sliding block)算法结合了定长切分和CDC切分的优点,块大小固定。它对定长数据块先计算弱校验值,如果匹配则再计算md5强校验值,两者都匹配则认为是一个数据块边界。该数据块前面的数据碎片也是一个数据块,它是不定长的。如果滑动窗口移过一个块大小的距离仍无法匹配,则也认定为一个数据块边界。滑动块算法对插入和删除问题处理非常高效,并且能够检测到比CDC更多的冗余数据,它的不足是容易产生数据碎片。
了解了它的关键技术,再来学习重点
重复数据删除的比例
通过数据去重节约的空间十分可观,这取决于数据类型以及所使用的数据去重引擎的组块大小。以文本文件与虚拟桌面架构环境为例,受益于高删除率,压缩比可达到40:1。而视频可以压缩的,但没法去重。存储厂商认为6:1是重复数据删除率的最佳平均值。加上相同的块压缩,数据中心可以通过这些技术轻松实现10:1的存储空间节约。
这些技术能够节约空间,十分具有,但重复数据删除属于计算密集型技术。在相对不重要的二级存储中,一般不会出现问题,但可能给主存储环境出现短暂拥塞现象。
“真正令人当心的是,应用程序可能在写入存储甚至在读取时被卡住,” Russell说。“如果主存储阵列的性能是一个瓶颈,那么就必须采取后处理方式”,在数据已经被写入存储后才开始压缩。
重复数据删除不仅可以在实时删除重复数据,还可以让供应商通过算法最大化潜在的数据压缩率。以Quantum的DXi系列备份设备为例,使用可改变块大小的重复数据删除算法,该算法是固定块大小方法效率的三倍以上。
今天的分享就到这了,也不知道对大家有用不,如果有用的话,那就点个赞吧!如果哪部分知识点欠缺,欢迎各位朋友进行补充哦~更多精彩的内容,就在课课家教育,还不赶紧行动?等着你们哟~
