数据可视化,是关于数据视觉表现形式的科学技术研究。其中,这种数据的视觉表现形式被定义为,一种以某种概要形式抽提出来的信息,包括相应信息单位的各种属性和变量。本文就是教你怎么看穿数据可视化的谎言,接下来我们一起探讨吧!

以前我们看到一个做得很烂的图表,或者穿帮的数据可视化作品时,往往是将它们嘲笑一番也就算了。但有些时候,尤其是刚过去的这一年,我们好像更难分辨一个可视化作品是单纯的糟糕产物,还是出于偏见而刻意制造的虚假信息。
数据可视化适用范围
关于数据可视化的适用范围,存在着不同的划分方法。一个常见的关注焦点就是信息的呈现。
迈克尔·弗兰德利(2008),提出了数据可视化的两个主要的组成部分:统计图形和主题图。
《DataVisualization:ModernApproaches》(意为“数据可视化:现代方法”)(2007),概括阐述了数据可视化的下列主题:
1)思维导图
2)新闻的显示
3)数据的显示
4)连接的显示
5)网站的显示
6)文章与资源
7)工具与服务
所有这些主题全都与图形设计和信息表达密切相关。
另一方面,FritsH.Post(2002)则从计算机科学的视角,将这一领域划分为如下多个子领域:
1)可视化算法与技术方法
2)立体可视化
3)信息可视化
4)多分辨率方法
5)建模技术方法
6)交互技术方法与体系架构
数据可视化的成功,应归于其背后基本思想的完备性。依据数据及其内在模式和关系,利用计算机生成的图像来获得深入认识和知识。其第二个前提就是利用人类感觉系统的广阔带宽来操纵和解释错综复杂的过程、涉及不同学科领域的数据集以及来源多样的大型抽象数据集合的模拟。这些思想和概念极其重要,对于计算科学与工程方法学以及管理活动都有着精深而又广泛的影响。《DataVisualization:TheStateoftheArt》(意为“数据可视化:尖端技术水平”)一书当中重点强调了各种应用领域与它们各自所特有的问题求解可视化技术方法之间的相互作用。
当然,用数据来撒谎已经不是什么新鲜事儿了,但现在图表越来越容易被广泛传播,网上到处都是,而其中好多传递的是假象。你可能只是随便瞟了一眼,但一个简单的信息也可能在脑子里生根发芽。在你还不知道的时候,小李子已经在桌子上转起了陀螺,而没人关心它会停下来还是会一直转下去。
自然而然地,现在我们需要快速看穿一个图表是否在撒谎,而这篇图文就是你贴心的指导手册哟。
1)截断数轴
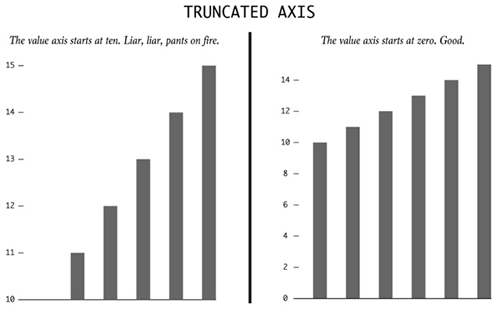
左边的y轴数据从10开始,纯粹的瞎话。右边的数据从0开始,很好。长度是柱状图视觉呈现的关键,所以当某些人通过截断数轴而故意把长度缩短时,整个图表的差别就变得更明显了。这些人想要展现出比实际情况更剧烈的变化。我在另一篇文章里详细谈了这个问题。
2)双重数轴
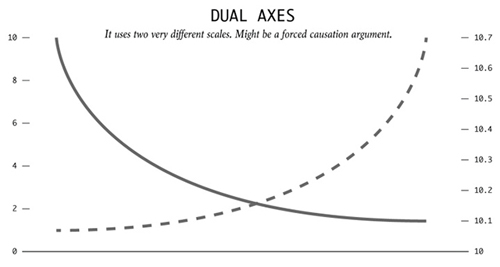
它用了两种差距极大的比例,可能是为了强行扯上因果关系。通过使用双重数轴,数据的量级可以根据两种度量来缩小或扩张。人们通常用它来表达相关度和因果关系。“因为这个东东,另一个事儿发生了,看,很清楚吧。”
Tyler Vigen做的假相关数据的项目是个极好的例子。
3)总和不对头
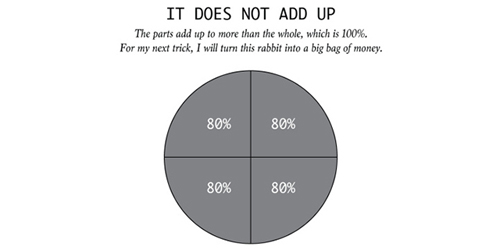
#p#分页标题#e#
饼图中所有部分的比例加起来超过了100%。一些图表专门要展示总体中的某些部分,而当这些部分加起来超过了总和,问题就很大了。比如,饼图代表的是总共100%,而如果每个扇形的比例加起来超过了100%?怪怪的噢。
可以看看这个搞笑的例子。
4)只看绝对值
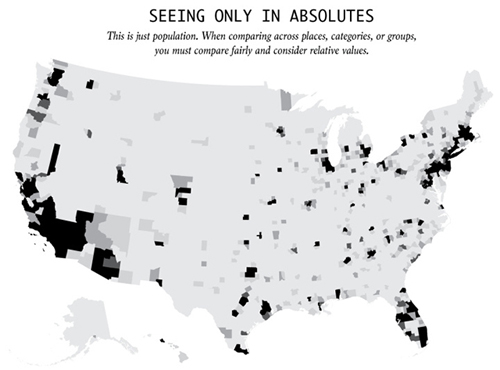
这其实只是人口分布图。当你对比不同地方、种类或群体时,你必须考虑相对值,公平比较任何事物都是相对的。你不能因为某个城镇发生了两起抢劫案,另一个只发生了一起,就说第一个镇更危险。万一第一个镇的人口是第二个的一千倍呢?更有效的方式往往是对比百分数和比例,而非绝对值和总值。
这幅xkcd的漫画很直白地展现了人口绝对数的影响。
5)有限范围
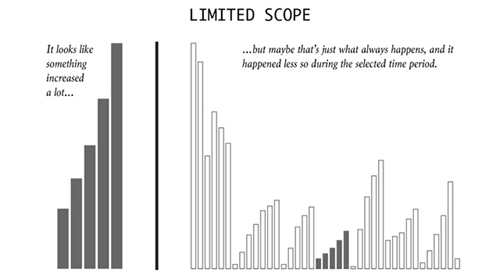
左图看上去增幅很大,但右图显示出这只是常态,且选定时间内的增幅实际并不明显。人们倾向于精心挑选日期和时间段来配合特定的叙事,所以更应该考虑到历史背景、时常发生的事件,以及合理的用来比较的基准。
当你研究全局时,可能会发现有趣的事情。
6)奇怪的分级
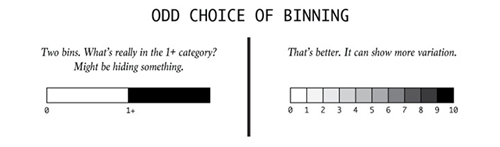
左图只有两个分级,大于1的究竟包括些什么?可能在打掩护。右图更好,展示了更多变量有些可视化作品会过分简化一个复杂的模型,而非展示出原数据中完整的变量范围。这样做很容易会把一个连续的变量转化为从属于某一类别的变量。
广泛的分级在某些情况下很有用,但复杂性往往才是事物的意义所在。要防止过分简化。
7)混乱的面积比
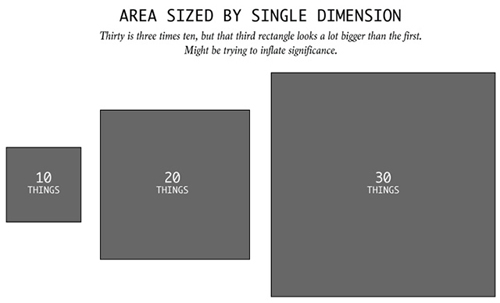
30是10的三倍,但或许是为了增加显著性,图上最大的矩形比最小的大得可不止三倍。如果按照面积来进行视觉上的编码,图形的大小比例就该是面积的比例。有些人却在做面积编码的可视化时,改变边长的比例来突出大小对比,完全是为了抓马啊。
有时这种错误是无意间造成的,更需要警觉。
8)操控面积维度
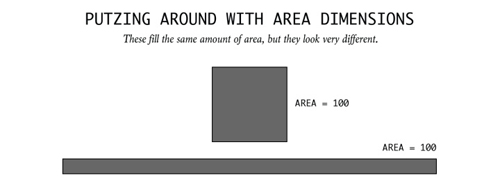
上下两个图形的面积相等,但看上去很不一样。或许有人懂得怎么用面积来做视觉编码,却还(gu)是(yi)做出了上图这样的东西。我还没见过如此夸张的例子,但以后说不定就会有。我打赌连象形图都能出现,等着瞧吧。
9)为了三维而三维
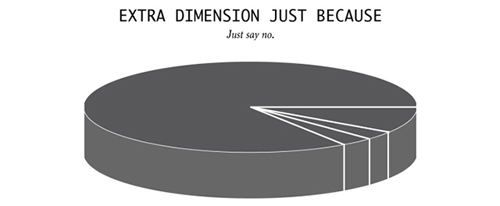
千万别。当你看到一个明明没必要还强行用三维的图表,请质疑它的数据、图表、作者及图表衍生出的任何事物。
划重点:如果一个可视化作品出现了以上任何问题,并不代表它一定在撒谎。正如Darrell Huff在《如何用数据撒谎》里说的:
#p#分页标题#e#
“本书的标题和里面一些内容可能像是在说,所有类似的作品都是为欺骗而生的产物。美国统计协会一个分会的主席曾经因为这个批评我,他觉得与其说出于欺骗,倒更像是能力不足。”
当然,这并不等于就可以原谅,毕竟也做错了嘛。但记住这点,你在骂某某某是骗子之前就可以再考虑考虑。
我的经验是,仔细检查那些令人震惊的、比想象中更具戏剧性的图表。
图表并不能让虚假的信息变成真的,数据也不能。它们会屈从于做图的人,也展示出信息本身之外更多的东西。那么,睁大你的眼睛咯。
结束语:各位小伙伴看完文章,差不多都应该学会怎么看穿数据可视化的谎言了吧!如果各位小伙伴还想了解更多这方面的知识或者内容的话,随时可以登陆课课家教育平台哟! 这里面有全面的知识内容和视频教程哦!随时等着你的到来~
