欢迎各位阅读本篇,数据:在计算机系统中,各种字母、数字符号的组合、语音、图形、图像等统称为数据,数据经过加工后就成为信息。本篇文章讲述了Spark Streaming场景应用&计算模型及监控。
摘要
Spark Streaming是一套优秀的实时计算框架。其良好的可扩展性、高吞吐量以及容错机制能够满足我们很多的场景应用。本篇结合我们的应用场景,介结我们在使用Spark Streaming方面的技术架构,并着重讲解Spark Streaming两种计算模型,无状态和状态计算模型以及该两种模型的注意事项;接着介绍了Spark Streaming在监控方面所做的一些事情,最后总结了Spark Streaming的优缺点。

一、概述
数据是非常宝贵的资源,对各级企事业单均有非常高的价值。但是数据的爆炸,导致原先单机的数据处理已经无法满足业务的场景需求。因此在此基础上出现了一些优秀的分布式计算框架,诸如Hadoop、Spark等。离线分布式处理框架虽然能够处理非常大量的数据,但是其迟滞性很难满足一些特定的需求场景,比如push反馈、实时推荐、实时用户行为等。
为了满足这些场景,使数据处理能够达到实时的响应和反馈,又随之出现了实时计算框架。目前的实时处理框架有Apache Storm、Apache Flink以及Spark Streaming等。其中Spark Streaming由于其本身的扩展性、高吞吐量以及容错能力等特性,并且能够和离线各种框架有效结合起来,因而是当下是比较受欢迎的一种流式处理框架。
根据其官方文档介绍,Spark Streaming 有高扩展性、高吞吐量和容错能力强的特点。Spark Streaming 支持的数据输入源很多,例如:Kafka、Flume、Twitter、ZeroMQ 和简单的 TCP 套接字等等。数据输入后可以用 Spark 的高度抽象原语如:map、reduce、join、window 等进行运算。而结果也能保存在很多地方,如 HDFS,数据库等。另外 Spark Streaming 也能和 MLlib(机器学习)以及 Graphx 完美融合。其架构见下图:

Spark Streaming 其优秀的特点给我们带来很多的应用场景,如网站监控和网络监控、异常监测、网页点击、用户行为、用户迁移等。本文中,将为大家详细介绍,我们的应用场景中,Spark Streaming的技术架构、两种状态模型以及Spark Streaming监控等。
二、应用场景
在 Spark Streaming 中,处理数据的单位是一批而不是单条,而数据采集却是逐条进行的,因此 Spark Streaming 系统需要设置间隔使得数据汇总到一定的量后再一并操作,这个间隔就是批处理间隔。批处理间隔是 Spark Streaming 的核心概念和关键参数,它决定了 Spark Streaming 提交作业的频率和数据处理的延迟,同时也影响着数据处理的吞吐量和性能。
2.1 框架
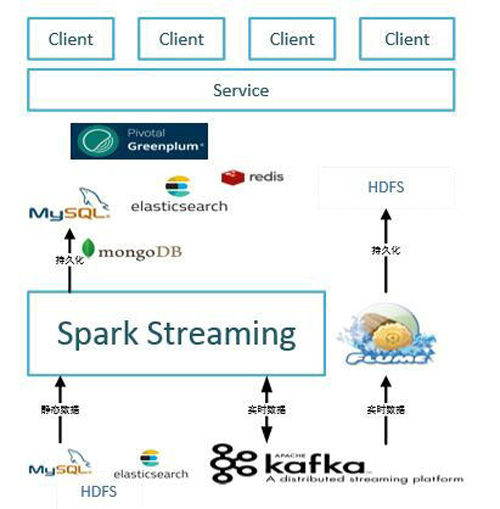
目前我们Spark Streaming的业务应用场景包括异常监测、网页点击、用户行为以及用户地图迁徙等场景。按计算模型来看大体可分为无状态的计算模型以及状态计算模型两种。在实际的应用场景中,我们采用Kafka作为实时输入源,Spark Streaming作为计算引擎处理完数据之后,再持久化到存储中,包括MySQL、HDFS、ElasticSearch以及MongoDB等;同时Spark Streaming 数据清洗后也会写入Kafka,然后经由Flume持久化到HDFS;接着基于持久化的内容做一些UI的展现。架构见下图:
2.2 无状态模型
无状态模型只关注当前新生成的DStream数据,所以的计算逻辑均基于该批次的数据进行处理。无状态模型能够很好地适应一些应用场景,比如网站点击实时排行榜、指定batch时间段的用户访问以及点击情况等。该模型由于没有状态,并不需要考虑有状态的情况,只需要根据业务场景保证数据不丢就行。此种情况一般采用Direct方式读取Kafka数据,并采用监听器方式持久化Offsets即可。具体流程如下:
其上模型框架包含以下几个处理步骤:
读取Kafka实时数据;
Spark Streaming Transformations以及actions操作;
将数据结果持久化到存储中,跳转到步骤一。
#p#分页标题#e#
受网络、集群等一些因素的影响,实时程序出现长时失败,导致数据出现堆积。此种情况下是丢掉堆积的数据从Kafka largest处消费还是从之前的Kafka offsets处消费,这个取决具体的业务场景。
2.3 状态模型
有状态模型是指DStreams在指定的时间范围内有依赖关系,具体的时间范围由业务场景来指定,可以是2个及以上的多个batch time RDD组成。Spark Streaming提供了updateStateByKey方法来满足此类的业务场景。因涉及状态的问题,所以在实际的计算过程中需要保存计算的状态,Spark Streaming中通过checkpoint来保存计算的元数据以及计算的进度。该状态模型的应用场景有网站具体模块的累计访问统计、最近N batch time 的网站访问情况以及app新增累计统计等等。具体流程如下:
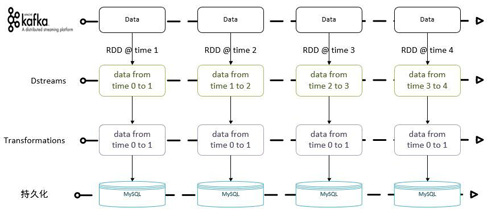
上述流程中,每batch time计算时,需要依赖最近2个batch time内的数据,经过转换及相关统计,最终持久化到MySQL中去。不过为了确保每个计算仅计算2个batch time内的数据,需要维护数据的状态,清除过期的数据。我们先来看下updateStateByKey的实现,其代码如下:
暴露了全局状态数据中的key类型的方法。
def updateStateByKey[S: ClassTag](
updateFunc: (Iterator[(K, Seq[V], Option[S])]) => Iterator[(K, S)],
partitioner: Partitioner,
rememberPartitioner: Boolean
): DStream[(K, S)] = ssc.withScope {
new StateDStream(self, ssc.sc.clean(updateFunc), partitioner, rememberPartitioner, None)
}
隐藏了全局状态数据中的key类型,仅对Value提供自定义的方法。
def updateStateByKey[S: ClassTag](
updateFunc: (Seq[V], Option[S]) => Option[S],
partitioner: Partitioner,
initialRDD: RDD[(K, S)]
): DStream[(K, S)] = ssc.withScope {
val cleanedUpdateF = sparkContext.clean(updateFunc)
val newUpdateFunc = (iterator: Iterator[(K, Seq[V], Option[S])]) => {
iterator.flatMap(t => cleanedUpdateF(t._2, t._3).map(s => (t._1, s)))
}
updateStateByKey(newUpdateFunc, partitioner, true, initialRDD)
}
以上两种方法分别给我们提供清理过期数据的思路:
泛型K进行过滤。K表示全局状态数据中对应的key,如若K不满足指定条件则反回false;
返回值过滤。第二个方法中自定义函数指定了Option[S]返回值,若过期数据返回None,那么该数据将从全局状态中清除。
三、Spark Streaming监控
同Spark一样,Spark Streaming也提供了Jobs、Stages、Storage、Enviorment、Executors以及Streaming的监控,其中Streaming监控页的内容如下图:
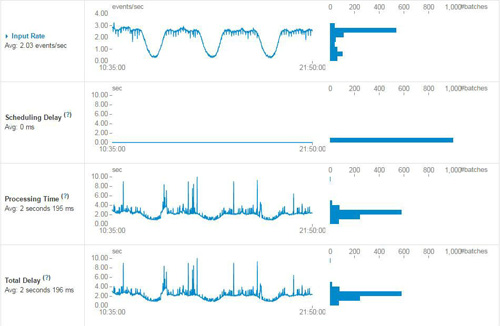
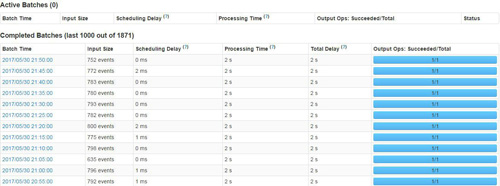
上图是Spark UI中提供一些数据监控,包括实时输入数据、Scheduling Delay、处理时间以及总延迟的相关监控数据的趋势展现。另外除了提供上述数据监控外,Spark UI还提供了Active Batches以及Completed Batches相关信息。Active Batches包含当前正在处理的batch信息以及堆积的batch相关信息,而Completed Batches刚提供每个batch处理的明细数据,具体包括batch time、input size、scheduling delay、processing Time、Total Delay等,具体信息见下图:
Spark Streaming能够提供如此优雅的数据监控,是因在对监听器设计模式的使用。如若Spark UI无法满足你所需的监控需要,用户可以定制个性化监控信息。Spark Streaming提供了StreamingListener特质,通过继承此方法,就可以定制所需的监控,其代码如下:
@DeveloperApi
trait StreamingListener {
/** Called when a receiver has been started */
def onReceiverStarted(receiverStarted: StreamingListenerReceiverStarted) { }
/** Called when a receiver has reported an error */
def onReceiverError(receiverError: StreamingListenerReceiverError) { }
/** Called when a receiver has been stopped */
def onReceiverStopped(receiverStopped: StreamingListenerReceiverStopped) { }
/** Called when a batch of jobs has been submitted for processing. */
def onBatchSubmitted(batchSubmitted: StreamingListenerBatchSubmitted) { }
/** Called when processing of a batch of jobs has started. */
def onBatchStarted(batchStarted: StreamingListenerBatchStarted) { }
/** Called when processing of a batch of jobs has completed. */
def onBatchCompleted(batchCompleted: StreamingListenerBatchCompleted) { }
/** Called when processing of a job of a batch has started. */
def onOutputOperationStarted(
outputOperationStarted: StreamingListenerOutputOperationStarted) { }
/** Called when processing of a job of a batch has completed. */
def onOutputOperationCompleted(
outputOperationCompleted: StreamingListenerOutputOperationCompleted) { }
}
#p#分页标题#e#
目前,我们保存Offsets时,采用继承StreamingListener方式,此是一种应用场景。当然也可以监控实时计算程序的堆积情况,并在达到一阈值后发送报警邮件。具体监听器的定制还得依据应用场景而定。
四、Spark Streaming优缺点
Spark Streaming并非是Storm那样,其并非是真正的流式处理框架,而是一次处理一批次数据。也正是这种方式,能够较好地集成Spark 其他计算模块,包括MLlib(机器学习)、Graphx以及Spark SQL。这给实时计算带来很大的便利,与此带来便利的同时,也牺牲作为流式的实时性等性能。
4.1 优点
Spark Streaming基于Spark Core API,因此其能够与Spark中的其他模块保持良好的兼容性,为编程提供了良好的可扩展性;
Spark Streaming 是粗粒度的准实时处理框架,一次读取完或异步读完之后处理数据,且其计算可基于大内存进行,因而具有较高的吞吐量;
Spark Streaming采用统一的DAG调度以及RDD,因此能够利用其lineage机制,对实时计算有很好的容错支持;
Spark Streaming的DStream是基于RDD的在流式数据处理方面的抽象,其transformations 以及actions有较大的相似性,这在一定程度上降低了用户的使用门槛,在熟悉Spark之后,能够快速上手Spark Streaming。
4.2 缺点
Spark Streaming是准实时的数据处理框架,采用粗粒度的处理方式,当batch time到时才会触发计算,这并非像Storm那样是纯流式的数据处理方式。此种方式不可避免会出现相应的计算延迟 。
目前来看,Spark Streaming稳定性方面还是会存在一些问题。有时会因一些莫名的异常导致退出,这种情况下得需要自己来保证数据一致性以及失败重启功能等。
四、总结
本篇文章主要介绍了Spark Streaming在实际应用场景中的两种计算模型,包括无状态模型以及状态模型;并且重点关注了下Spark Streaming在监控方面所作的努力。首先本文介绍了Spark Streaming应用场景以及在我们的实际应用中所采取的技术架构。在此基础上,引入无状态计算模型以及有状态模型两种计算模型;接着通过监听器模式介绍Spark UI相关监控信息等;最后对Spark Streaming的优缺点进行概括。希望本篇文章能够给各位带来帮助,后续我们会介绍Spark Streaming在场景应用中我们所做的优化方面的努力,敬请期待!
知识分享:
数据仓库的特点
根据数据仓库概念的含义,数据仓库拥有以下四个特点:
1、面向主题。操作型数据库的数据组织面向事务处理任务,各个业务系统之间各自分离,而数据仓库中的数据是按照一定的主题域进行组织。主题是一个抽象的概念,是指用户使用数据仓库进行决策时所关心的重点方面,一个主题通常与多个操作型信息系统相关。
2、集成的。面向事务处理的操作型数据库通常与某些特定的应用相关,数据库之间相互独立,并且往往是异构的。而数据仓库中的数据是在对原有分散的数据库数据抽取、清理的基础上经过系统加工、汇总和整理得到的,必须消除源数据中的不一致性,以保证数据仓库内的信息是关于整个企业的一致的全局信息。
3、相对稳定的。操作型数据库中的数据通常实时更新,数据根据需要及时发生变化。数据仓库的数据主要供企业决策分析之用,所涉及的数据操作主要是数据查询,一旦某个数据进入数据仓库以后,一般情况下将被长期保留,也就是数据仓库中一般有大量的查询操作,但修改和删除操作很少,通常只需要定期的加载、刷新。
4、反映历史变化。操作型数据库主要关心当前某一个时间段内的数据,而数据仓库中的数据通常包含历史信息,系统记录了企业从过去某一时点(如开始应用数据仓库的时点)到目前的各个阶段的信息,通过这些信息,可以对企业的发展历程和未来趋势做出定量分析和预测。
#p#分页标题#e#
企业数据仓库的建设,是以现有企业业务系统和大量业务数据的积累为基础。数据仓库不是静态的概念,只有把信息及时交给需要这些信息的使用者,供他们做出改善其业务经营的决策,信息才能发挥作用,信息才有意义。而把信息加以整理归纳和重组,并及时提供给相应的管理决策人员,是数据仓库的根本任务。因此,从产业界的角度看,数据仓库建设是一个工程,是一个过程。
数据库是依照某种数据模型组织起来并存放二级存储器中的数据集合。这种数据集合具有如下特点:尽可能不重复,以最优方式为某个特定组织的多种应用服务,其数据结构独立于使用它的应用程序,对数据的增、删、改和检索由统一软件进行管理和控制。从发展的历史看,数据库是数据管理的高级阶段,它是由文件管理系统发展起来的。
