超文本传输协议(HypertextTransferProtocol,简称HTTP)是应用层协议。HTTP是一种请求/响应式的协议,即一个客户端与服务器建立连接后,向服务器发送一个请求;服务器接到请求后,给予相应的响应信息。今天我们就来全方面的了解Http报文工作原理,有需要的小伙伴,参考一下。
HTTP请求报文解析
HTTP请求报文由3部分组成(请求行+请求头+请求体):
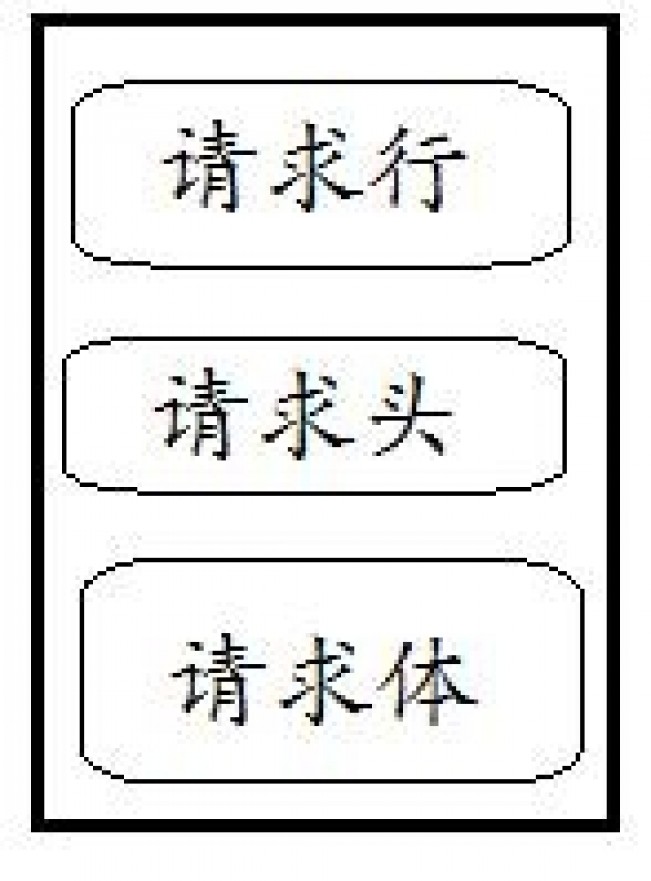
下面是一个实际的请求报文:
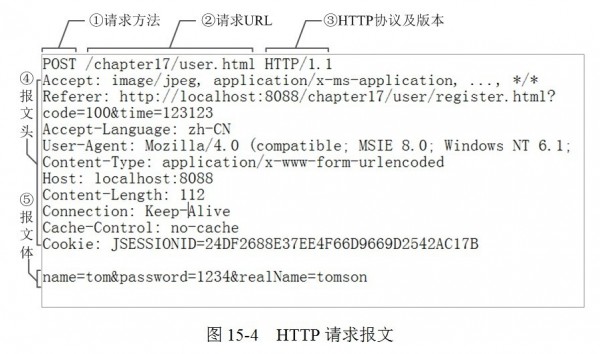
①是请求方法,GET和POST是最常见的HTTP方法,除此以外还包括DELETE、HEAD、OPTIONS、PUT、TRACE。不过,当前的大多数浏览器只支持GET和POST,spring 3.0提供了一个HiddenHttpMethodFilter,允许你通过“_method”的表单参数指定这些特殊的HTTP方法(实际上还是通过POST提交表单)。服务端配置了HiddenHttpMethodFilter后,Spring会根据_method参数指定的值模拟出相应的HTTP方法,这样,就可以使用这些HTTP方法对处理方法进行映射了。
②为请求对应的URL地址,它和报文头的Host属性组成完整的请求URL,③是协议名称及版本号。
④是HTTP的报文头,报文头包含若干个属性,格式为“属性名:属性值”,服务端据此获取客户端的信息。
⑤是报文体,它将一个页面表单中的组件值通过param1=value1¶m2=value2的键值对形式编码成一个格式化串,它承载多个请求参数的数据。不但报文体可以传递请求参数,请求URL也可以通过类似于“/chapter15/user.html? param1=value1¶m2=value2”的方式传递请求参数。
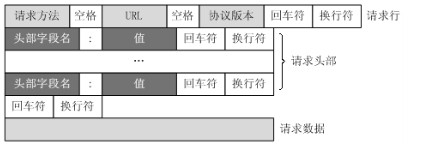
对照上面的请求报文,我们把它进一步分解,你可以看到一幅更详细的结构图:
引用
HttpWatch是强大的网页数据分析工具,安装后将集成到Internet Explorer工具栏中。它不用代理服务器或一些复杂的网络监控工具,就能抓取请求及响应的完整信息,包括Cookies、消息头、查询参数、响应报文等,是Web应用开发人员的必备工具。
HTTP的工作过程
一次HTTP操作称为一个事务,其工作整个过程如下:
1)、地址解析
如用客户端浏览器请求这个页面:http://localhost.com:8080/index.htm
从中分解出协议名、主机名、端口、对象路径等部分,对于我们的这个地址,解析得到的结果如下:
协议名:http
主机名:localhost.com
端口:8080
对象路径:/index.html
在这一步,需要域名系统DNS解析域名localhost.com,得主机的IP地址。
2)、封装HTTP请求数据包
把以上部分结合本机自己的信息,封装成一个HTTP请求数据包
3)封装成TCP包,建立TCP连接(TCP的三次握手)
在HTTP工作开始之前,客户机(Web浏览器)首先要通过网络与服务器建立连接,该连接是通过TCP来完成的,该协议与IP协议共同构建Internet,即著名的TCP/IP协议族,因此Internet又被称作是TCP/IP网络。HTTP是比TCP更高层次的应用层协议,根据规则,只有低层协议建立之后才能,才能进行更层协议的连接,因此,首先要建立TCP连接,一般TCP连接的端口号是80。这里是8080端口
4)客户机发送请求命令
建立连接后,客户机发送一个请求给服务器,请求方式的格式为:统一资源标识符(URL)、协议版本号,后边是MIME信息包括请求修饰符、客户机信息和可内容。
5)服务器响应
服务器接到请求后,给予相应的响应信息,其格式为一个状态行,包括信息的协议版本号、一个成功或错误的代码,后边是MIME信息包括服务器信息、实体信息和可能的内容。
实体消息是服务器向浏览器发送头信息后,它会发送一个空白行来表示头信息的发送到此为结束,接着,它就以Content-Type应答头信息所描述的格式发送用户所请求的实际数据
6)服务器关闭TCP连接
一般情况下,一旦Web服务器向浏览器发送了请求数据,它就要关闭TCP连接,然后如果浏览器或者服务器在其头信息加入了这行代码
Connection:keep-alive
#p#分页标题#e#
TCP连接在发送后将仍然保持打开状态,于是,浏览器可以继续通过相同的连接发送请求。保持连接节省了为每个请求建立新连接所需的时间,还节约了网络带宽。
HTTP请求报文头属性
报文头属性是什么东西呢?我们不妨以一个小故事来说明吧。
引用
快到中午了,张三丰不想去食堂吃饭,于是打电话叫外卖:老板,我要一份[鱼香肉丝],要12:30之前给我送过来哦,我在江湖湖公司研发部,叫张三丰。
这里,你要[鱼香肉丝]相当于HTTP报文体,而“12:30之前送过来”,你叫“张三丰”等信息就相当于HTTP的报文头。它们是一些附属信息,帮忙你和饭店老板顺利完成这次交易。
请求HTTP报文和响应HTTP报文都拥有若干个报文关属性,它们是为协助客户端及服务端交易的一些附属信息。
常见的HTTP请求报文头属性
Accept
请求报文可通过一个“Accept”报文头属性告诉服务端 客户端接受什么类型的响应。
如下报文头相当于告诉服务端,俺客户端能够接受的响应类型仅为纯文本数据啊,你丫别发其它什么图片啊,视频啊过来,那样我会歇菜的~~~:
Accept:text/plainAccept属性的值可以为一个或多个MIME类型的值,关于MIME类型。
Cookie
客户端的Cookie就是通过这个报文头属性传给服务端的哦!如下所示:
Cookie: $Version=1; Skin=new;jsessionid=5F4771183629C9834F8382E23BE13C4C服务端是怎么知道客户端的多个请求是隶属于一个Session呢?注意到后台的那个jsessionid=5F4771183629C9834F8382E23BE13C4C木有?原来就是通过HTTP请求报文头的Cookie属性的jsessionid的值关联起来的!(当然也可以通过重写URL的方式将会话ID附带在每个URL的后面哦)。
Referer
表示这个请求是从哪个URL过来的,假如你通过google搜索出一个商家的广告页面,你对这个广告页面感兴趣,鼠标一点发送一个请求报文到商家的网站,这个请求报文的Referer报文头属性值就是http://www.google.com。
引用
唐僧到了西天.
如来问:侬是不是从东土大唐来啊?
唐僧:厉害!你咋知道的!
如来:呵呵,我偷看了你的Referer…
很多貌似神奇的网页监控软件(如著名的 我要啦),只要在你的网页上放上一段Javascript,就可以帮你监控流量,全国访问客户的分布情况等报表和图表,其原理就是通过这个Referer及其它一些HTTP报文头工作的。
Cache-Control
对缓存进行控制,如一个请求希望响应返回的内容在客户端要被缓存一年,或不希望被缓存就可以通过这个报文头达到目的。
如以下设置,相当于让服务端将对应请求返回的响应内容不要在客户端缓存:
Cache-Control: no-cache如何访问请求报文头
由于请求报文头是客户端发过来的,服务端当然只能读取了,以下是HttpServletRequest一些用于读取请求报文头的API:
//获取请求报文中的属性名称
java.util.Enumeration getHeaderNames();
//获取指定名称的报文头属性的值
java.lang.String getHeader(java.lang.String name)由于一些请求报文头属性“太著名”了,因此HttpServletRequest为它们提供了VIP的API:
//获取报文头中的Cookie(读取Cookie的报文头属性)
Cookie[] getCookies() ;
//获取客户端本地化信息(读取 Accept-Language 的报文头属性)
java.util.Locale getLocale()
//获取请求报文体的长度(读取Content-Length的报文头属性)
int getContentLength();HttpServletRequest可以通过
HttpSession getSession()获取请求所关联的HttpSession,其内部的机理是通过读取请求报文头中Cookie属性的JSESSIONID的值,在服务端的一个会话Map中,根据这个JSESSIONID获取对应的HttpSession的对象。(这样,你就不会觉得HttpSession很神秘了吧,你自己也可以做一个类似的会话管理)
HTTP响应报文解剖
响应报文结构
HTTP的响应报文也由三部分组成(响应行+响应头+响应体):
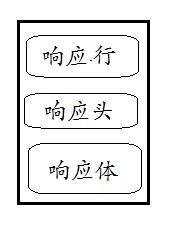
以下是一个实际的HTTP响应报文:
#p#分页标题#e#

①报文协议及版本;
②状态码及状态描述;
③响应报文头,也是由多个属性组成;
④响应报文体,即我们真正要的“干货”。
响应状态码
和请求报文相比,响应报文多了一个“响应状态码”,它以“清晰明确”的语言告诉客户端本次请求的处理结果。
HTTP的响应状态码由5段组成:
1xx 消息,一般是告诉客户端,请求已经收到了,正在处理,别急…
2xx 处理成功,一般表示:请求收悉、我明白你要的、请求已受理、已经处理完成等信息.
3xx 重定向到其它地方。它让客户端再发起一个请求以完成整个处理。
4xx 处理发生错误,责任在客户端,如客户端的请求一个不存在的资源,客户端未被授权,禁止访问等。
5xx 处理发生错误,责任在服务端,如服务端抛出异常,路由出错,HTTP版本不支持等。
以下是几个常见的状态码:
200 OK
你最希望看到的,即处理成功!
303 See Other
我把你redirect到其它的页面,目标的URL通过响应报文头的Location告诉你。
引用
悟空:师傅给个桃吧,走了一天了
唐僧:我哪有桃啊!去王母娘娘那找吧
304 Not Modified
告诉客户端,你请求的这个资源至你上次取得后,并没有更改,你直接用你本地的缓存吧,我很忙哦,你能不能少来烦我啊!
404 Not Found
你最不希望看到的,即找不到页面。如你在google上找到一个页面,点击这个链接返回404,表示这个页面已经被网站删除了,google那边的记录只是美好的回忆。
500 Internal Server Error
看到这个错误,你就应该查查服务端的日志了,肯定抛出了一堆异常,别睡了,起来改BUG去吧!
其它的状态码参见:http://en.wikipedia.org/wiki/List_of_HTTP_status_codes
有些响应码,Web应用服务器会自动给生成。你可以通过HttpServletResponse的API设置状态码:
//设置状态码,状态码在HttpServletResponse中通过一系列的常量预定义了,如SC_ACCEPTED,SC_OK
void setStatus(int sc)常见的HTTP响应报文头属性
Cache-Control
响应输出到客户端后,服务端通过该报文头属告诉客户端如何控制响应内容的缓存。
下面,的设置让客户端对响应内容缓存3600秒,也即在3600秒内,如果客户再次访问该资源,直接从客户端的缓存中返回内容给客户,不要再从服务端获取(当然,这个功能是靠客户端实现的,服务端只是通过这个属性提示客户端“应该这么做”,做不做,还是决定于客户端,如果是自己宣称支持HTTP的客户端,则就应该这样实现)。
Cache-Control: max-age=3600ETag
一个代表响应服务端资源(如页面)版本的报文头属性,如果某个服务端资源发生变化了,这个ETag就会相应发生变化。它是Cache-Control的有益补充,可以让客户端“更智能”地处理什么时候要从服务端取资源,什么时候可以直接从缓存中返回响应。
Spring 3.0还专门为此提供了一个org.springframework.web.filter.ShallowEtagHeaderFilter(实现原理很简单,对JSP输出的内容MD5,这样内容有变化ETag就相应变化了),用于生成响应的ETag,因为这东东确实可以帮助减少请求和响应的交互。
下面是一个ETag:
ETag: “737060cd8c284d8af7ad3082f209582d”Location
我们在JSP中让页面Redirect到一个某个A页面中,其实是让客户端再发一个请求到A页面,这个需要Redirect到的A页面的URL,其实就是通过响应报文头的Location属性告知客户端的,如下的报文头属性,将使客户端redirect到iteye的首页中:
Location: http://www.iteye.comSet-Cookie
服务端可以设置客户端的Cookie,其原理就是通过这个响应报文头属性实现的:
Set-Cookie: UserID=JohnDoe; Max-Age=3600; Version=1其它HTTP响应报文头属性
更多其它的HTTP响应头报文,参见:http://en.wikipedia.org/wiki/List_of_HTTP_header_fields
如何写HTTP请求报文头
在服务端可以通过HttpServletResponse的API写响应报文头的属性:
//添加一个响应报文头属性
void setHeader(String name, String value)象Cookie,Location这些响应都是有福之人,HttpServletResponse为它们都提供了VIP版的API:
//添加Cookie报文头属性
void addCookie(Cookie cookie)
//不但会设置Location的响应报文头,还会生成303的状态码呢,两者天仙配呢
void sendRedirect(String location)
#p#分页标题#e#
结束语:看完文章的各位小伙伴,应该把“Http报文工作原理”了解的差不多了吧!如果还想了解更多关于这方面的内容,随时可以登陆课课家哦!这里面有全面的知识内容和视频教学。随时欢迎你的登陆哟~
