不要让Hadoop有机会成为Had oops!
欢迎各位阅读本篇,Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。本篇文章讲述了Hadoop&Had oops之间,课课家教育平台提醒各位:本篇文章纯干货~因此大家一定要认真阅读本篇文章哦!
过去几年里,数据量的生成以每两年翻翻的速度增长,但企业的预算却没有相应增长。这意味着要更有创造性地通过更少的方式做更多的工作。这是一个持续且艰巨的挑战,我没有一劳永逸的解决方案,但我可以提供一些指导原则,让你以更好的姿态去面对挑战。
IDC预测,到2020年,全球数据规模将达到44ZB,即44万亿GB,如果人们无法继续投资以扩大存储能力,可能在未来只有15%的数据能够找到地方加以存储。
在今天的数据驱动型经济中,存储需求往往超出了计算资源的需求,这就导致IT基础设施无法均衡负载。客户添加越来越多的服务器用来扩展其大数据和分析功能,然而CPU资源却并未得到充分利用。这是因为大数据和分析工作通常是存储密集型,而不是计算密集型。因此,成功应对数据挑战的关键之一就是认识到基础设施所需的不同增长率,了解到什么会增长,以什么样的速度增长。
为了应对持续增长的数据挑战,越来越多的公司创造了一系列技术和工具,用于摄取,传输,分析,存储,预测,剥离等。其结果呈现在你眼前,是一幅充满各种选择的巨大地图,并且这些选择并不都是平等的:有些是死胡同,有些会把你锁定到一个特定的供应商,而另一些只能应对今天的问题,更不要说明天或后天了。
可悲的是,一些组织似乎认为,应对数据挑战非常简单 :“Just add Hadoop!”,然而直到他们拥有太多的Hadoop或Hadoop装在了错误的位置时,才意识到了问题所在。此外,把硬件和软件简单地投入到分析挑战中,就如同把汽油投入火中,它能烧得更旺,但也可能会烧到你。将技术应用于数据和分析问题时,通常包含着的复杂性。即使是Hadoop,也会面临多重挑战。
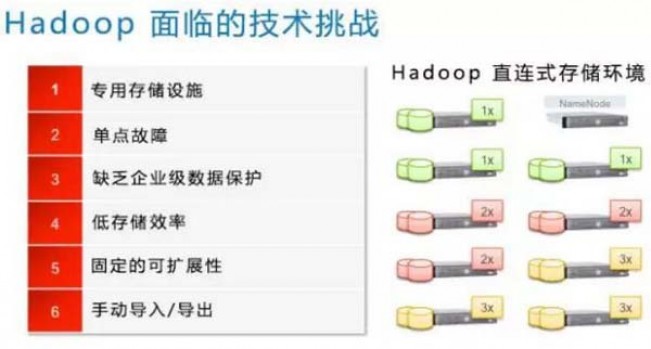
除了挑战之外,也有很多选择让你无从下手。选择Hortonworks、Cloudera、MapR还是BigInsights Hadoop发行版? 是否使用诸如EMC Vblock / VxBlock之类的融合基础架构或超融合基础设施(如EMC VxRail和VxRack)?直连式存储(DAS)是否满足您的需求,还是应该将计算和存储分离,使用Isilon为你的数据湖横向扩展? 相信我,以上这些只是衡量使用Hadoop所需考虑的一部分因素。大象并不是你在丛林中唯一需要担心的, 了解技术的同时了解其对业务和IT的影响,对成功至关重要。
对于以上这些挑战,一个有效解决方案是企业级的扩展存储解决方案,如EMC Isilon。在Isilon上运行Hadoop拥有以下几个优点。

除了以上优势,Isilon还通过以下方式为客户带来好处:
消除Hadoop NameNode维护的昂贵开销
大大减少与处理磁盘故障相关的工作量
通过消除Hadoop的典型3X数据复制,帮助管理分析存储增长的速度
减少移动和分段数据的需要,使其可以访问Hadoop。
对于许多客户而言,Isilon代表了可扩展性,可用性和性能的最佳平衡,同时降低了与Hadoop集群相关的运营开销。没有任何银弹能解决爆炸性数据增长所带来的所有问题,但是应用横向扩展存储技术往往有助于减轻痛苦。
分享:
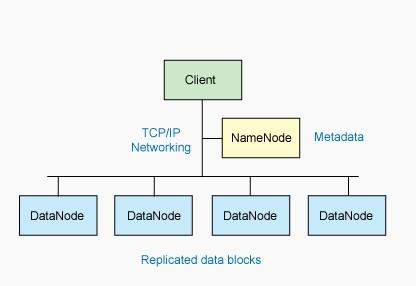
DataNode
DataNode 也是一个通常在 HDFS 实例中的单独机器上运行的软件。Hadoop 集群包含一个 NameNode 和大量 DataNode。DataNode 通常以机架的形式组织,机架通过一个交换机将所有系统连接起来。Hadoop 的一个假设是:机架内部节点之间的传输速度快于机架间节点的传输速度。
DataNode 响应来自 HDFS 客户机的读写请求。它们还响应来自 NameNode 的创建、删除和复制块的命令。NameNode 依赖来自每个 DataNode 的定期心跳(heartbeat)消息。每条消息都包含一个块报告,NameNode 可以根据这个报告验证块映射和其他文件系统元数据。如果 DataNode 不能发送心跳消息,NameNode 将采取修复措施,重新复制在该节点上丢失的块。
文件操作
可见,HDFS 并不是一个万能的文件系统。它的主要目的是支持以流的形式访问写入的大型文件。如果客户机想将文件写到 HDFS 上,首先需要将该文件缓存到本地的临时存储。如果缓存的数据大于所需的 HDFS 块大小,创建文件的请求将发送给 NameNode。NameNode 将以 DataNode 标识和目标块响应客户机。同时也通知将要保存文件块副本的 DataNode。
#p#分页标题#e#
当客户机开始将临时文件发送给第一个 DataNode 时,将立即通过管道方式将块内容转发给副本 DataNode。客户机也负责创建保存在相同 HDFS名称空间中的校验和(checksum)文件。在最后的文件块发送之后,NameNode 将文件创建提交到它的持久化元数据存储(在 EditLog 和 FsImage 文件)。
Linux 集群
Hadoop 框架可在单一的 Linux 平台上使用(开发和调试时),但是使用存放在机架上的商业服务器才能发挥它的力量。这些机架组成一个 Hadoop 集群。它通过集群拓扑知识决定如何在整个集群中分配作业和文件。Hadoop 假定节点可能失败,因此采用本机方法处理单个计算机甚至所有机架的失败。
小结:充分利用集群的威力进行高速运算和存储。文章中不足及错误之处在所难免,敬请专家和读者给予批评指正。
