Java实现Web版RSS阅读器(五)劈头完成阅读成果
副标题#e#
上一篇博文《Web版RSS阅读器(四)——定制本身的Rss理会库myrsslib4j》中,已经分享给各人建造本身的rss理会库。稍微有点遗憾的是,它仅仅支持rss名目标博客。此刻给各人分享一下我基于rome修改而成的另一款rss理会库——myrome,完美支持atom和rss 2种名目。
myrome.jar是在rome的基本上修改而来的,主要窜改的处所是:(查察具体修改说明)
修改GetAuthor()返回null
修改getPublishedDate()返回null
添加获取文章摘要的接口和要领
附下载地点:http://pan.baidu.com/share/link?shareid=3563208157&uk=1259218556
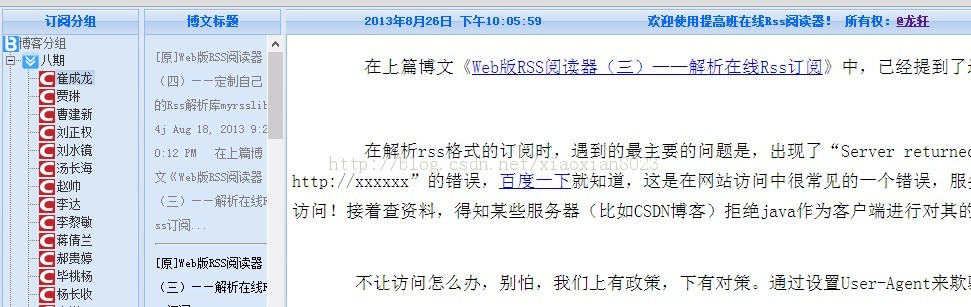
本篇主题是把myrome插手到RssReader中,修改界面,完成劈头的会见和阅读的成果。详细实现的结果为:
按照差异的订阅信息,加载对应的图标,从而一眼得知订阅的出处
点击左侧的某个订阅,在中间的页面中显示出标题、时间和摘要列表,用程度线离隔
点击某个摘要信息,在右侧内容区域,显示该文章的所有内容。
双击摘要信息,则会用新窗口打开原文章地点。
言归正传,接下来请各人跟从我劈头乐成的脚步:
下载myrome-1.0.jar,拷贝到WebRoot/WEB-INF/lib下。假如已经引用过rome-0.2.jar,要提前删除去。在com.tgb.rssreader.manager包中新建RomeReadRss类,用来理会在线rss内容。
【RomeReadRss.java】
package com.tgb.rssreader.manager;
import java.net.URL;
import java.net.URLConnection;
import com.sun.syndication.feed.synd.SyndFeed;
import com.sun.syndication.io.SyndFeedInput;
import com.sun.syndication.io.XmlReader;
/**
* 理会Rss订阅信息
*
* @author Longxuan
*
*/
public class RomeReadRss {
/**
* 理会Rss订阅信息
*/
public SyndFeed parseRss(String rss) {
SyndFeed feed = null;
feed = null;
try {
URLConnection feedUrl = new URL(rss).openConnection();
// 由于处事器屏蔽java作为客户端会见rss,所以配置User-Agent
feedUrl.setRequestProperty("User-Agent",
"Mozilla/4.0 (compatible; MSIE 5.0; Windows NT; DigExt)");
// 读取Rss源
XmlReader reader = new XmlReader(feedUrl);
SyndFeedInput input = new SyndFeedInput();
// 获得SyndFeed工具,即获得Rss源里的所有信息
feed = input.build(reader);
} catch (Exception e) {
e.printStackTrace();
}
return feed;
}
}
#p#副标题#e#
修改left.jsp页的树形节点加载信息,按照差异的博客提供商,加载差异的图标。点击某节点后,将rss地点通报给servlet,去理会在线的rss。
【left.jsp】
<%@ page language="java" contentType="text/html; charset=GB18030"
pageEncoding="GB18030"%>
<%@ page import="com.tgb.rssreader.bean.*" %>
<%@ page import="java.util.*" %>
<%
String path = request.getContextPath();
String basePath = request.getScheme() + "://" + request.getServerName() + ":" + request.getServerPort()+path+"/";
%>
<html>
<head>
<base href="<%=basePath %>" />
<link rel="stylesheet" href="style/main.css">
<link rel="StyleSheet" href="style/dtree.css" type="text/css" />
<script type="text/javascript" src="js/dtree.js"></script>
<script type="text/javascript">
//获取图标地点
//
在com.tgb.rssreader.web包中新建一个RssServlet类,担任HttpServlet,实现doGet和doPost要领。它吸收到有left.jsp通报过来的rss地点,挪用RomeReadRss来理会rss内容。理会完毕后,转向middle.jsp,在中间这个网页中,显示理会的内容。
【RssServlet.java】
package com.tgb.rssreader.web;
import java.io.IOException;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import com.sun.syndication.feed.synd.SyndFeed;
import com.tgb.rssreader.manager.RomeReadRss;
/**
* 理会Rss信息资源Servlet
* @author Longxuan
*
*/
@SuppressWarnings("serial")
public class RssServlet extends HttpServlet {
@Override
protected void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
//获取rss地点
//
#p#分页标题#e#【middle.jsp】
<%@ page language="java" contentType="text/html; charset=GB18030"
pageEncoding="GB18030"%>
<%@ page import="com.sun.syndication.feed.synd.*"%>
<%@page import="java.util.List"%>
<%@page session="true" %>
<%
String path = request.getContextPath();
String basePath = request.getScheme() + "://"
+ request.getServerName() + ":" + request.getServerPort()
+ path + "/";
%>
<html>
<head>
<base href="<%=basePath%>" />
<link rel="stylesheet" href="style/main.css">
<style type="text/css">
#middleTitle ul li {
text-align: left;
display: inline;
line-height: 24px;
height: auto;
word-break: break-all;
word-wrap: break-word;
}
a {
text-decoration: none;
}
a:link {
color: #000000;
} /* 未被会见的链接 */
a:visited {
color: #808080;
} /* 已被会见的链接 */
a:hover {
color: #0000FF;
} /* 鼠标指针移动到链接上 */
a:active {
color: #0000FF;
} /* 正在被点击的链接 */
</style>
<script type="text/javascript">
function openInBrowser(url) {
window.open(url);
}
</script>
</head>
<body>
<div id="middleTitle">
<ul>
<%
//获取配置到session中的摘要信息
SyndFeed feed = (SyndFeed) request.getSession().getAttribute("feed");
if (feed == null)return;
//获取所有文章列表
List entriesList = feed.getEntries();
//轮回加载文章摘要列表
for (int i = 0; i < entriesList.size(); i++) {
SyndEntry entry = (SyndEntry) entriesList.get(i);%>
<a href="servlet/ArticleServlet?articleIndex=<%=i%>"
title="<%=entry.getTitle()%>" target="contenthtml"
ondblclick="openInBrowser('<%=entry.getLink().trim()%>')">
<li>
<%=entry.getTitle().trim()%>
<%=entry.getPublishedDate().toLocaleString()%>
</li>
<li>
<%=((SyndContent) entry.getContents().get(0)).getSummary(30)%>
</li> </a>
<hr>
<%}%>
</ul>
</div>
</body>
</html>
当点击某篇文章标题时,将该文章的索引值通报到ArticleServlet中,在Session中找到对应的文章,把文章正文内容通报到content.jsp页面。所以在com.tgb.rssreader.web包中新建ArticleServlet类,担任HttpServlet,实现doGet和doPost要领。
【ArticleServlet.java】
package com.tgb.rssreader.web;
import java.io.IOException;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import com.sun.syndication.feed.synd.SyndContent;
import com.sun.syndication.feed.synd.SyndEntry;
import com.sun.syndication.feed.synd.SyndFeed;
/**
* 获取文章正文
* @author Longxuan
*
*/
@SuppressWarnings("serial")
public class ArticleServlet extends HttpServlet {
@Override
protected void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
//获取要查察的文章的索引值
//
【content.jsp】
<%@ page language="java" contentType="text/html; charset=GB18030"
pageEncoding="GB18030"%>
<%@page import="com.sun.syndication.feed.synd.*"%>
<%
String path = request.getContextPath();
String basePath = request.getScheme() + "://"
+ request.getServerName() + ":" + request.getServerPort()
+ path + "/";
%>
<html>
<head>
<base href="<%=basePath%>" />
<link rel="stylesheet" href="style/main.css">
</head>
<body>
<div id="content">
<div id="welcome" class="content" style="display: block;">
<div align="left">
<p>
<%= request.getAttribute("content")==null?"<marquee behavior='alternate'" +
"onmouseover='this.stop()' onmouseout='this.start()' wight='60%' scrollamount='4'>" +
"<font size='6' text-align='center' >接待利用提高班在线Rss阅读器!" +
"——@<a href = \"http://blog.csdn.net/xiaoxian8023\" target='_blank'>龙轩</a></font>"
:request.getAttribute("content").toString()%>
</p>
<hr>
</div>
</div>
</div>
</body>
</html>
#p#分页标题#e#
至此,Web版Rss阅读器阅读博客成果根基已经落成了,终于可以看到这款rss阅读器的样子了。虽然需要优化的处所还许多。临时规划告一段落,等过段时间再举办优化。根基的代码都已经写过了,不规划单独提供源码了。最后晒一下结果图吧: